本文主要是介绍扫描全能王文档矫正逆向记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
扫描全能王有个功能是将弯曲的文本拉直成平直的文本。在扫描全能王的app上,这个功能的入口在拍书籍的tab。同时在图片编辑页面,也有个按钮可以触发这个功能。它的效果大概如下。
这篇文章主要介绍如何逆向这个算法
初步定位
对扫描王apk初步逆向之后,发现破解难度有点大。大概有这几个问题
- 扫描全能王apk经过爱加密加过壳,ida动态破解难度大,基本一开始挂调试就触发反调试机制
- 文档矫正算法有两套,其中纯C++实现的算法复杂度极高
加壳的处理直接导致很多逆向手段用不了。而复杂的纯CV又导致还原算法基本不可能。
好在多次尝试之后,发现扫描全能王还有个模型矫正的算法。
模型矫正逆向
扫描全能王在6.0版本之后增加了一个矫正函数。在6.0之前的矫正函数名都是 dewarpXXX,在6.0之后多了一个dewarpXXXNew。比如这个,接受的是一个图片的指针参数。
dewarpImgPtrNew
用ida静态分析该函数之后发现,它使用的是基于MNN推理引擎的模型。
这个模型实现了端到端的图像矫正,而且效果跟传统算法的矫正结果差不多。
把逆向目标定位在这个函数上,难度会小很多。所需要做的事情大概是:
- 梳理模型矫正的输入数据预处理和后处理
- dump模型出来
- 还原矫正流程
逆向模型矫正的好处之一是只要拿到了模型,就成功了一半。
dump模型
虽然扫描全能王把模型以二进制方式打包进了so库,但是没有很好地对二进制数据进行加密。在花了一些时间分析之后,就用ida将模型dump出来了
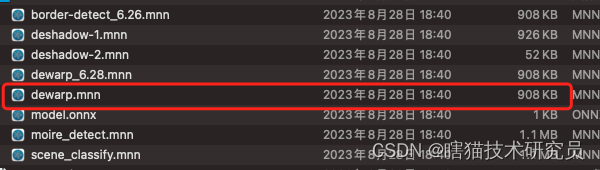
初步分析这个模型之后,不得不说扫描全能王的算法团队有点东西。他们用同一个分割网络实现了边缘检测,阴影检测,文档矫正。而这个模型的大小才1M不到。
分析前后处理
预处理的分析比较简单。我构造了模型矫正的上下文环境,通过hook的方式让矫正流程强制走了模型矫正。
1. int val = initDewarpContext()//初始化引擎2. ScannerEngine.dewarpImgPtrNew(val, ptr)//处理数据3. ScannerEngine.releaseContext(val)//释放引擎
在进入了模型矫正调用之后,还需要hook一些关键函数。
比如,我需要知道输入图像缩放到什么尺寸,它的归一化参数是多少。
而这些需要对so进行静态分析后才能找到合适的hook位置。
举例来说,输入到模型的图像缩放的尺寸,我用这个frida函数实现
Interceptor.attach(resize, {onEnter: function(args) {if(dewarpProcessDone != 1) return;if(Process.getCurrentThreadId() != threadId) return;console.log('\n[-] resize, thread: ', Process.getCurrentThreadId());console.log("[-] resize args[0] - args[4]: ", args[0], args[1], args[2], args[3], args[4]);console.log("[-] resize src size: ", ptr(args[0]).add(4).readPointer(), " \n src size:", ptr(args[0]).add(4).readPointer().add(8).readInt(), "-", ptr(args[0]).add(4).readPointer().add(12).readInt());console.log("[-] resize dst size: ", ptr(args[2]), " \n dst size:", ptr(args[2]).readInt(), "-", ptr(args[2]).add(4).readInt());console.log(' args[2]:\n', Memory.readByteArray(ptr(args[2]), 16));console.log(' flag:\n', Memory.readByteArray(ptr(args[0]).add(0x4).readPointer(), 16));
这里涉及到二进制分析,还有对数据结构的了解。展开讲比较复杂,都可以单独开一篇了。总之在分析后知道,模型的输入是240x240。
有些人可能会问,啊模型输入不是看模型文件就知道吗?这个不行,它的MNN文件看不到输入尺寸信息。
预处理的流程不多,解决了输入尺寸,就完成了一大半。
真正难的是后处理的分析
看后处理的代码,至少包含几个步骤。
- 输出数据高斯模糊
- 平滑处理
- 放大插值
- 原图映射
光是这几个流程的还原,就花了我小一个月时间。
还原矫正流程
最后还原出来的结果大概是这样:

扫描全能王的模型矫正,其实是一种位移场矫正算法。
这里我在中间的图用绿色的网格将位移场表示出来,会比较直观。
- 左边是原图,首先将模型缩放到240x240的尺寸,送进模型
- 模型会检测图像的曲率,得到一系列离散的曲率值。将这些曲率值连起来,就是中间图的绿色网格
- 在得到了曲率值之后,将原图的像素一一映射到新的图片,得到最右边的图
位移场矫正的思路大概是这样:
- 假设有一张平直的图像文档,像最右边的
- 将它以某种程度扭曲,这种扭曲必须是连续的,不是离散的。那么描述这种扭曲的就是一种位移场
- 将原图的所有像素,按照这个位移场进行映射,就能得到一张扭曲后的图
可以看到位移场矫正算法,它是一种自然位移的逆运算。能想到这个方案的算法师有点东西,而且这个方案值钱的地方在于需要大量接近真实的数据标注。
目前还不知道这些数据是怎么标注的,如果用Blender造数据,会和真实样张有出入。用真实样张进行标注,又是天量的工作时间。
最后
整个逆向大概花了两三个月时间。最后我用C++还原了这个位移场矫正算法。上面的绿色网格图,就是在还原出来的算法代码上添加的。它其实是逆运算。
简单讲,矫正模型输出的是扭曲->原图的位移数据,我称之为逆位移场。如果将这些数据可视化的话,会不好理解。
我在逆向出来的代码上,将模型的输出数据反向计算,得到一个正的位移场,再将这个位移场套到一个标准的网格上,就能看出来原图是经过怎样的一个扭曲空间,变成一张扭曲过的图的。
这篇关于扫描全能王文档矫正逆向记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






