本文主要是介绍PixelShuffle方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://blog.csdn.net/u014636245/article/details/98071626
PixelShuffle是一种上采样方法,可以对缩小后的特征图进行有效的放大。可以替代插值或解卷积的方法实现upscale
PixelShuffle
PixelShuffle(像素重组)的主要功能是将低分辨的特征图,通过卷积和多通道间的重组得到高分辨率的特征图。这一方法最初是为了解决图像超分辨率问题而提出的,这种称为Sub-Pixel Convolutional Neural Network的方法成为了上采样的有效手段。
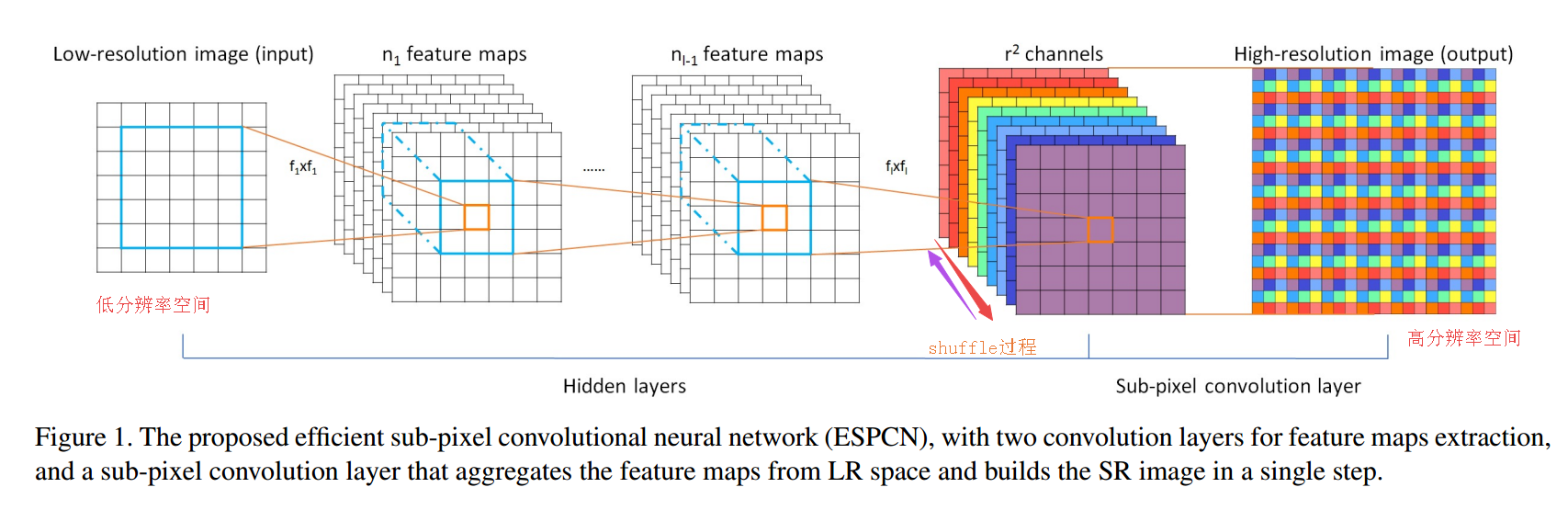
要把一张低分辨输入转变为高分辨输出,论文ESPCN中提出用基于特征抽取和亚像素卷积的方法来扩大特征图,将特征图从低分辨空间转换到高分辨空间中去.上图中左侧第一部分是用于对图像的特征进行抽取。而后在倒数第二层生成 r 2 r 2 r 2 r2r2 r^2 r2r2r2w∗r,h∗r的上采样结果。具体来说,就是将原来一个低分辨的像素划分为rr各更小的格子,利用rr个特征图对应位置的值按照一定的规则来填充这些小格子。按照同样的规则将每个低分辨像素划分出的小格子填满就完成了重组过程。在这一过程中模型可以调整r*r个shuffle通道权重不断优化生成的结果。
主要实现了这样的功能:N*(C*r*r)*W*H---->>N*C*(H*r)*(W*r)
实现
在pytorch,mxnet和tensorflow都用相应的pixelshuffle实现。
pytorch 中主要使用nn.PixelShuffle函数:
#官方文档的实例可以参考::>>> ps = nn.PixelShuffle(3)>>> input = autograd.Variable(torch.Tensor(1, 9, 4, 4))>>> output = ps(input)>>> print(output.size())torch.Size([1, 1, 12, 12])在mxnet中,gluon前端有针对不同的维度有三个apiPixelShuffle1D, PixelShuffle2D, PixelShuffle3D
#官方文档使用例子可以参考:
pxshuf = PixelShuffle1D(2)
x = mx.nd.zeros((1, 8, 3))
pxshuf(x).shape
#-----#
pxshuf = PixelShuffle2D((2, 3))
x = mx.nd.zeros((1, 12, 3, 5))
pxshuf(x).shape
#-----#
pxshuf = PixelShuffle3D((2, 3, 4))
x = mx.nd.zeros((1, 48, 3, 5, 7))
pxshuf(x).shape
tensorflow中也有人对pixelshuffle进行了实现:
#numpy
def PS(I, r):assert len(I.shape) == 3assert r>0r = int(r)O = np.zeros((I.shape[0]*r, I.shape[1]*r, I.shape[2]/(r*2)))for x in range(O.shape[0]):for y in range(O.shape[1]):for c in range(O.shape[2]):c += 1a = np.floor(x/r).astype("int")b = np.floor(y/r).astype("int")d = c*r*(y%r) + c*(x%r)print a, b, dO[x, y, c-1] = I[a, b, d]return O
#------#
#Tensorflow
def _phase_shift(I, r):
# Helper function with main phase shift operation
bsize, a, b, c = I.get_shape().as_list()
X = tf.reshape(I, (bsize, a, b, r, r))
X = tf.transpose(X, (0, 1, 2, 4, 3)) # bsize, a, b, 1, 1
X = tf.split(1, a, X) # a, [bsize, b, r, r]
X = tf.concat(2, [tf.squeeze(x) for x in X]) # bsize, b, ar, r
X = tf.split(1, b, X) # b, [bsize, ar, r]
X = tf.concat(2, [tf.squeeze(x) for x in X]) #
bsize, ar, br
return tf.reshape(X, (bsize, ar, br, 1))
def PS(X, r, color=False):
# Main OP that you can arbitrarily use in you tensorflow code
if color:
Xc = tf.split(3, 3, X)
X = tf.concat(3, [_phase_shift(x, r) for x in Xc])
else:
X = _phase_shift(X, r)
return X
这篇关于PixelShuffle方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




