本文主要是介绍opencv 分类器的训练(生成.xml, CascadeClassifier),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
检测的物体是否为绝对刚性的物体,也就是检测的目标是一个固定物体,没有变化(如特定公司的商标),这样的物体只要提供一份样本就可以进行训练。但绝大数时候我们想进行训练的目标是非绝对刚性的物体,如对人的检测,包括人脸识别、手势识别。
分类器的训练以分为以下三部进行:
1、 样本的创建(正样本和负样本)
2、 训练分类器(生成.xml)
3、 利用训练好的分类器进行目标检测
正样本:所谓正样本就是只包含检测目标的图片
1、要求尺寸必须相同,例如40x30
2、进行灰度处理
负样本:不包含检测目标的任何图片(背景图片)
1.不要求样本尺寸,但要大于等于正样本的大小;且负样本不能重复,要增大负样本的差异性。
2.负样本灰度化,同正样本操作相同。
制作正样本:
1、收集数据(截图或拍照等)进行处理:
2、 将所有图像调整成一致大小,我用的“美图看看”这款软件,批量处理的,我处理的统一尺寸是40x30
3、进行灰度处理
#include "stdafx.h"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
#include <stdio.h>using namespace cv;
using namespace std;int main()
{char buffer[50];char buffer1[50];int i = 0;for (i = 1; i <= 100; i++){sprintf_s(buffer, "C:\\Users\\Administrator\\Desktop\\xml\\ww\\%d.png", i);sprintf_s(buffer1, "C:\\Users\\Administrator\\Desktop\\xml\\pos\\%d.png", i);Mat src = imread(buffer, IMREAD_COLOR);if (src.empty()){return -1;}cvtColor(src, src, COLOR_BGR2GRAY);equalizeHist(src, src);imwrite(buffer1, src);}return 0;
}
4、这样正样本就处理好了,接下来要生成posdata.dat文件
将opencv安装目录的D:\Program Files\opencv\build\x64\vc15\bin\opencv_createsamples.exe和opencv_traincascade.exe复制到需要进行图像处理的目录下(也可不复制,操作时加上目录)
制作dos命令操作文件dat_cmd.bat:输入dir /b > posdata.dat(表示将当前文件写入posdata.dat)
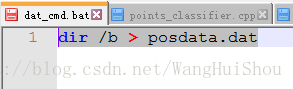
双击执行dat_cmd.bat生成posdata.dat,打开posdata.dat,删除不需要文件

在对文件进行处理,使其含有图片信息,格式为:图片路径 检测目标在图片中的个数 起始监测点坐标(x,y) 图片大小(w,h)
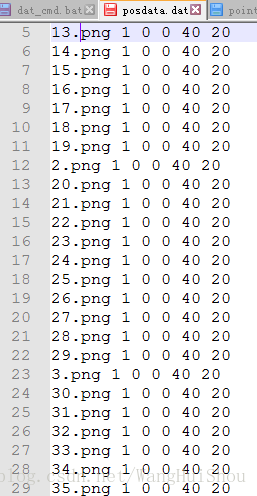
5、生成训练.vec文件

执行生成pos.vec

参数说明
命令行参数:
-
-vec <vec_file_name>
输出文件,内含用于训练的正样本。
-
-img <image_file_name>
输入图像文件名(例如一个公司的标志)。
-
-bg <background_file_name>
背景图像的描述文件,文件中包含一系列的图像文件名,这些图像将被随机选作物体的背景。
-
-num <number_of_samples>
生成的正样本的数目。
-
-bgcolor <background_color>
背景颜色(目前为灰度图);背景颜色表示透明颜色。因为图像压缩可造成颜色偏差,颜色的容差可以由 -bgthresh 指定。所有处于 bgcolor-bgthresh 和 bgcolor+bgthresh 之间的像素都被设置为透明像素。
-
-bgthresh <background_color_threshold>
-
-inv
如果指定该标志,前景图像的颜色将翻转。
-
-randinv
如果指定该标志,颜色将随机地翻转。
-
-maxidev <max_intensity_deviation>
前景样本里像素的亮度梯度的最大值。
-
-maxxangle <max_x_rotation_angle>
X轴最大旋转角度,必须以弧度为单位。
-
-maxyangle <max_y_rotation_angle>
Y轴最大旋转角度,必须以弧度为单位。
-
-maxzangle <max_z_rotation_angle>
Z轴最大旋转角度,必须以弧度为单位。
-
-show
很有用的调试选项。如果指定该选项,每个样本都将被显示。如果按下 Esc 键,程序将继续创建样本但不再显示。
-
-w <sample_width>
输出样本的宽度(以像素为单位)。
-
-h <sample_height>
输出样本的高度(以像素为单位)。
6、处理负样本:对负样本只需得到.dat文件(同正样本处理)
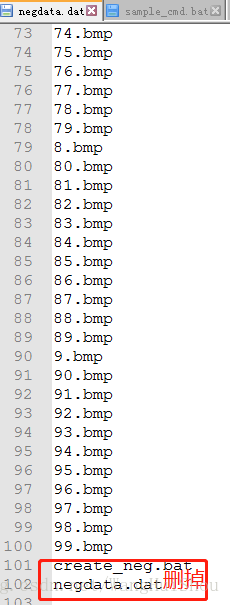
二、训练级联分类器
1、将生成的的负样本negdata.dat复制到和opencv_traincascade.exe同目录下(也可以吧正样本的pos.vec复制到此目录下)
并且制作训练命令train.bat
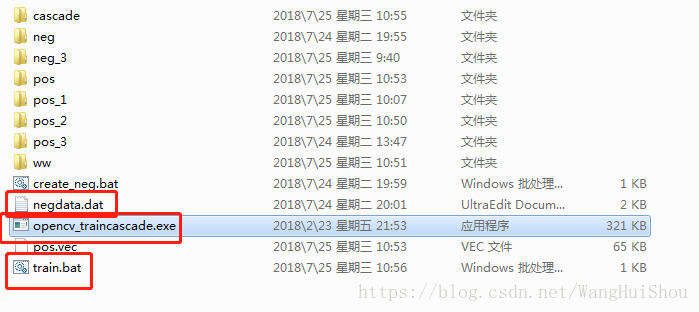
opencv_traincascade.exe -data cascade -vec pos.vec -bg negdata.dat -numPos 41 -numNeg 100 -numStages 20 -minHitRate 0.999 -maxFalseAlarmRate 0.4 -featureType HAAR -w 40 -h 20

注:pause是为了查看cmd执行

参数说明:
-
通用参数:
-
-data <cascade_dir_name>
目录名,如不存在训练程序会创建它,用于存放训练好的分类器。
-
-vec <vec_file_name>
包含正样本的vec文件名(由 opencv_createsamples 程序生成)。
-
-bg <background_file_name>
背景描述文件,也就是包含负样本文件名的那个描述文件。
-
-numPos <number_of_positive_samples>
每级分类器训练时所用的正样本数目。
-
-numNeg <number_of_negative_samples>
每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目。
-
-numStages <number_of_stages>
训练的分类器的级数。
-
-precalcValBufSize <precalculated_vals_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征值(feature values),单位为MB。
-
-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb>
缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB。内存越大,训练时间越短。
-
-baseFormatSave
这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储。
-
-
级联参数:
-
-stageType <BOOST(default)>
级别(stage)参数。目前只支持将BOOST分类器作为级别的类型。
-
-featureType<{HAAR(default), LBP}>
特征的类型: HAAR - 类Haar特征; LBP - 局部纹理模式特征。
-
-w <sampleWidth>
-
-h <sampleHeight>
训练样本的尺寸(单位为像素)。必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致。
-
-
Boosted分类器参数:
-
-bt <{DAB, RAB, LB, GAB(default)}>
Boosted分类器的类型: DAB - Discrete AdaBoost, RAB - Real AdaBoost, LB - LogitBoost, GAB - Gentle AdaBoost。
-
-minHitRate <min_hit_rate>
分类器的每一级希望得到的最小检测率。总的检测率大约为 min_hit_rate^number_of_stages。
-
-maxFalseAlarmRate <max_false_alarm_rate>
分类器的每一级希望得到的最大误检率。总的误检率大约为 max_false_alarm_rate^number_of_stages.
-
-weightTrimRate <weight_trim_rate>
Specifies whether trimming should be used and its weight. 一个还不错的数值是0.95。
-
-maxDepth <max_depth_of_weak_tree>
弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps)。
-
-maxWeakCount <max_weak_tree_count>
每一级中的弱分类器的最大数目。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given -maxFalseAlarmRate.
-
-
类Haar特征参数:
-
-mode <BASIC (default) | CORE | ALL>
选择训练过程中使用的Haar特征的类型。 BASIC 只使用右上特征, ALL 使用所有右上特征和45度旋转特征。更多细节请参考 [Rainer2002] 。
-
-
LBP特征参数:
LBP特征无参数。
当 opencv_traincascade 程序训练结束以后,训练好的级联分类器将存储于文件cascade.xml中,这个文件位于 -data 指定的目录中。这个目录中的其他文件是训练的中间结果,当训练程序被中断后,再重新运行训练程序将读入之前的训练结果,而不需从头重新训练。训练结束后,你可以删除这些中间文件。
训练结束后,你就可以测试你训练好的级联分类器了!
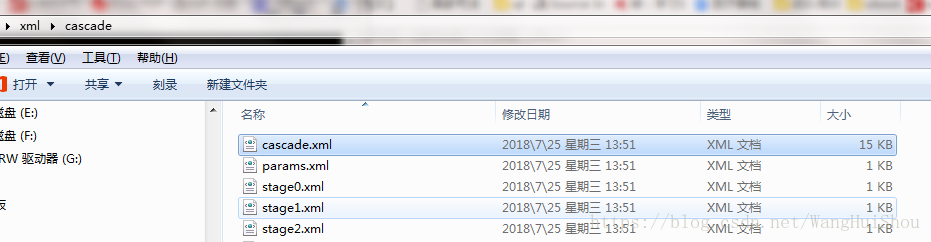
三、训练器的测试
参考CascadeClassifier级联分类器的使用https://blog.csdn.net/WangHuiShou/article/details/81201698
四、考 训练分类器所遇到的问题
1、

-bg 参数不能直接跟目录,因为neg目录下手下读取的不是negdata.dat文件,导致失败
2、问题:traincascade's error (Required leaf false alarm rate achieved. Branch training terminated.)
解析:虚警率已经达标 不再继续训练 ,这里不能说是一个错误,只能说制作出来的xml文件可能较差
解决办法:先测试一下生成的cascade.xml,如果效果没有达到你的预期,有以下几个解决方案:
1:maxfalsealarm值应该设定到0.4 - 0.5之间
2:正负样本数太少,增大样本数
四、参考网站
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html#id6
这篇关于opencv 分类器的训练(生成.xml, CascadeClassifier)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





