本文主要是介绍mysql从大到小搜索_关于搜索,从Like到Match Against到搜索引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在弄Mysql搜索相关的东西,走了很多坑,总结一下How to search。
一、使用like模糊查询
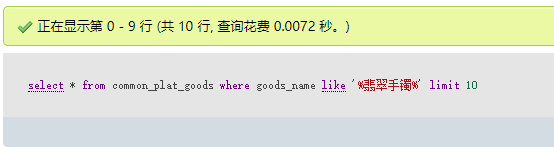 大家常用的搜索方式,莫过于使用mysql自带的模糊查询like,where like “%xxx%”搜索简单粗暴,屡试不爽。对于小几万数据量的数据库来说,这个方式是很好用的,很符合当下快节奏的生活方式。(测试数据库有近20W条)
大家常用的搜索方式,莫过于使用mysql自带的模糊查询like,where like “%xxx%”搜索简单粗暴,屡试不爽。对于小几万数据量的数据库来说,这个方式是很好用的,很符合当下快节奏的生活方式。(测试数据库有近20W条)
似乎看起来是很快的,但是

一加上order by 排序的话,花费时间成指数增长,而且

随着like要匹配的词长度增加,查询速度也是程指数下降,14秒,才20W数据,就用了14.5秒的时间,简直不能忍,要是增长到百万,不得爆炸。like貌似真的不行~于是,上全文索引。
二、使用match against 全文索引search
由于实在不能忍like的缓慢,于是乎就上Mysql自带的全文索引。mysql自5.6以后innodb支持fulltext index。嗯,刚好我们的服务器上是5.7,撸起袖子,换match。但是第一个问题出现了,分词?由于英语句子都有空格作为分隔符,而中文是没有空格的,怎么样才能分词呢?两种解决办法,一种是中文转拼音塞个新字段进去;再就是把中文分词后用符号隔开塞个新字段进去。我用了第二种方式:
然后修改mysql配置文件:mysql> SHOW VARIABLES LIKE 'ft%';ft_boolean_syntax + ->
ft_min_word_len一定要改小,改为1或者2.因为中文分词最小就是一个字或两个字,4的话显然是不行的。然后创建全文索引:

ps:有三点要说一下:
1.全文索引match的字段和建索引时的字段必须一致,联合索引同理。
2.against要匹配的中文,需要加上“+”号参数+:表示必须包含。 -:表示必须不包含 *:表示任意字符
3.两种匹配方式 自然语言检索:IN NATURAL LANGUAGE MODE 布尔检索: IN BOOLEAN MODE
剔除一半匹配行以上都有的词,譬如说,每个行都有this这个字的话,那用this去查时,会找不到任何结果,这在记录条数特别多时很有用,
原因是数据库认为把所有行都找出来是没有意义的,这时,this几乎被当作是stopword(中断词);但是若只有两行记录时,是啥鬼也查不出来的,
因为每个字都出现50%(或以上),要避免这种状况,请用IN BOOLEAN MODE。现在就可以使用全文索引了,来试试看吧:

卧槽,貌似比like慢多了啊,什么玩意?加上排序之后呢?

再试试多几个词
虽然说比起like来,多一点的匹配词并没有增加额外的时间,但是只要一order by ,不管你order by 的字段有没有创建索引,都要对结果集进行重排序。观察mysql性能分析后发现:
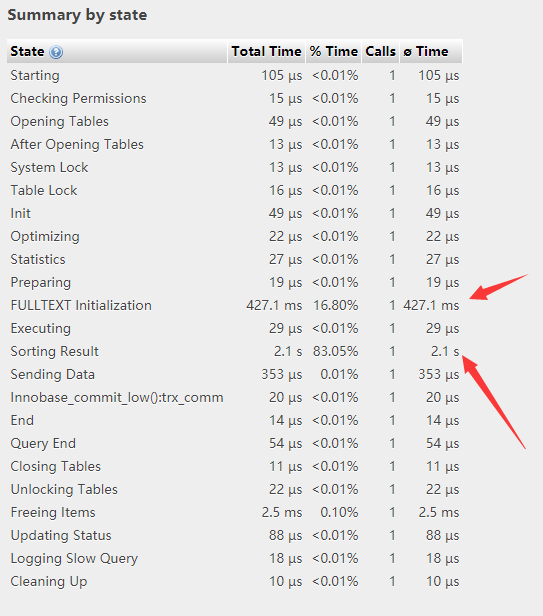
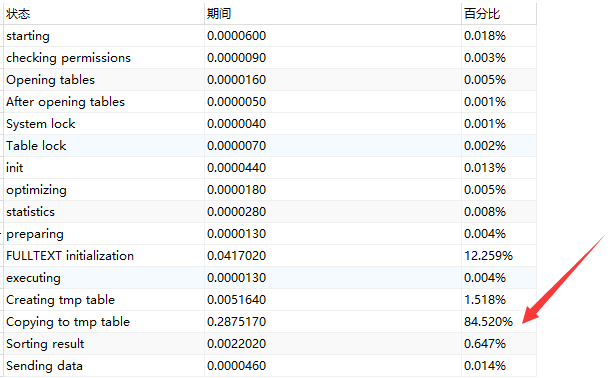
全文索引稳定只用了300到500毫秒的时间,剩下的80%~90%时间全在排序上了。这也是不能忍啊,于是乎找了各种解决办法,再stackexchange上找到一个回答。
在使用全文索引之后要进行排序操作的话需要这样:
SUGGESTION
Refactor the Query so that the MATCH ...AGAINST collects keys only
EXAMPLE #1SELECT a.id FROM a
WHERE
MATCH ('search1','search2') AGAINST ('aaaa' IN BOOLEAN MODE)
ORDER BY a.id DESC
LIMIT 5;
should become something likeSELECT N.id FROM
(SELECT id FROM a WHERE
MATCH ('search1','search2') AGAINST ('aaaa' IN BOOLEAN MODE)) M
INNER JOIN a N USING (id)
ORDER BY N.id DESC LIMIT 5;
EXAMPLE #2SELECT a.id,a.popularity FROM a
WHERE
MATCH ('search1','search2') AGAINST ('aaaa' IN BOOLEAN MODE)
ORDER BY a.popularity DESC
LIMIT 5;
should become something likeSELECT N.id,N.popularity FROM
(SELECT id FROM a WHERE
MATCH ('search1','search2') AGAINST ('aaaa' IN BOOLEAN MODE)) M
INNER JOIN a N USING (id)
ORDER BY N.popularity DESC LIMIT 5;
CONCLUSION
The main idea: Collect the keys using MATCH ...AGAINST and join it back to the source table
好吧,看到了零时表。。。。继续

貌似跟原来一样,并没有提升什么。。。。

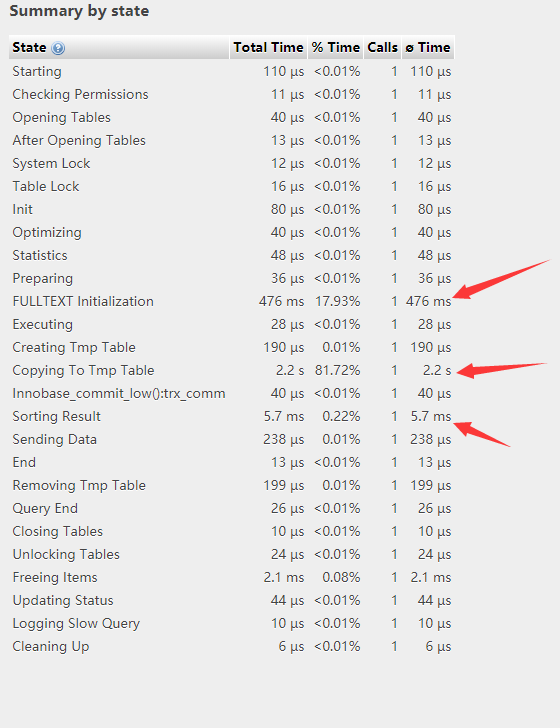
这样做虽然sorting result的时间变短了,但是copy to tmp table 的时间增加了很多。。。。这样的话,对优化来说并无卵用,再次google,stackexchange:You may need to try setting certain variables within your sessionYou may need to try setting certain variables within your session
These particular values may be too small for your DB Connection to fulfill the query efficiently. These can be set within as follows:To see what values these settings have currently do the following:SHOW VARIABLES LIKE 'max_heap_table_size';SHOW VARIABLES LIKE 'tmp_table_size';
To set max_heap_table_size to 64M do the following:SET max_heap_table_size = 1024 * 1024 * 64;
To set tmp_table_size to 32M do the following:SET tmp_table_size = 1024 * 1024 * 32;
If you cannot set these values within your own session, contact your hosting provider to dynamically set them in your my.cnf.
好吧,改配置文件。。。。修改配置文件之后Copy to temp table 的时间就大幅下降了
至此,全文索引告一段落。这个数据量下,在有排序的情况下,检索速度能保持在1秒以内。然后这远远不够,怎么办?上搜索引擎~
三、使用搜索引擎
sphinx,coreseek,xunsearch 三种选一个吧。
sphinx名气比较大,但是中文文档比较少。
coreseek,反正官网我是访问不了了。
xunsearch 中文文档够用,而且一直在更新。所以就选xunsearch吧。
顺着教程来:
1、下载安装xunsearch
wget http://www.xunsearch.com/download/xunsearch-full-latest.tar.bz2
tar -xjf xunsearch-full-latest.tar.bz2
cd xunsearch-full-1.3.0/
sh setup.sh
2、开启和重启
xunsearch /usr/local/xunsearch/bin/xs-ctl.sh restart
3、检测运行环境和修改配置文件
/usr/local/xunsearch/sdk/php/util/RequiredCheck.php
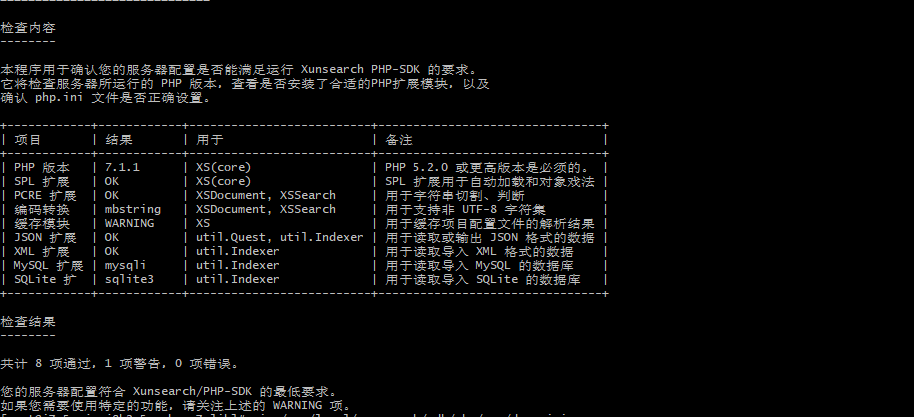
3、修改索引配置文件demo.ini这个ini配置文件是很重要的,如果不会写的话,推荐使用官方的模板自动生成:http://www.xunsearch.com/tools/iniconfig
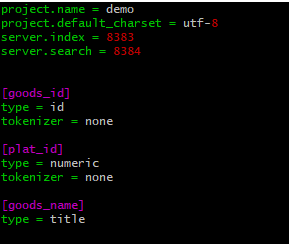

4、导入数据生成索引(支持json,mysql,CSV)一般使用mysql
# 清空 demo 项目的索引数据
util/Indexer.php --clean demo
# 导入 JSON 数据文件 file.json 到 demo 项目
util/Indexer.php --source=json demo file.json
# 导入 MySQL 数据库的 dbname.tbl_post 表到 demo 项目中,并且平滑重建
util/Indexer.php --rebuild --source=mysql://root:pass@localhost/dbname --sql="SELECT * FROM common_plat_goods" --project=demo
# 查看 demo 项目在服务端的相关信息
util/Indexer.php --info -p demo
# 强制刷新 demo 项目的搜索日志
util/Indexer.php --flush-log --project demo
# 强制停止重建
util/Indexer.php --stop-rebuild demo
这里我使用的是mysql,只需要goods_id,plat_id,goods_name 三个字段。导入脚本如下:
/usr/local/xunsearch/sdk/php/util/Indexer.php --rebuild --source=mysql://root:123456@127.0.0.1/search --sql="select goods_id,plat_id,goods_name from common_plat_goods order by goods_id desc" --project=demo
PS:
localhost不行就换成127.0.0.1
--project=demo是配置文件的名称
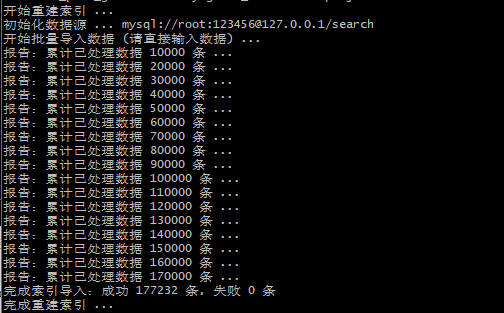
速度还是很快的,近18W条数据几秒钟索引就重建好了。试试看官方提供的测试搜索:
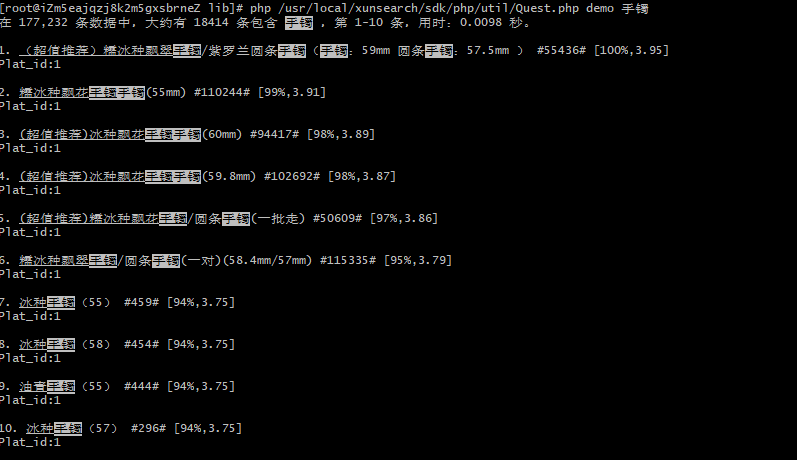
你没看错,0.0098秒就完成了检索,大功告成~什么like,match aginst都是浮云,搜索引擎才是王道啊。
接下来就可以结合xunsearch的SDK写相应的业务了,具体可以看官方的文档。比起直接使用like或者match against,搜索引擎的确很爽
这篇关于mysql从大到小搜索_关于搜索,从Like到Match Against到搜索引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




