本文主要是介绍通过wav文件和text文件训练出phoneme文件的过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境:python2.7和python3.6
最近训练的一个神经网络需要wav文件和phn文件作为自己输入。
所有的数据库中都有wav文件,但是phoneme文件却不是每个数据库都有。
TIMIT数据库中就PHN文件。
先贴个PHN文件的图。
SX127.PHN
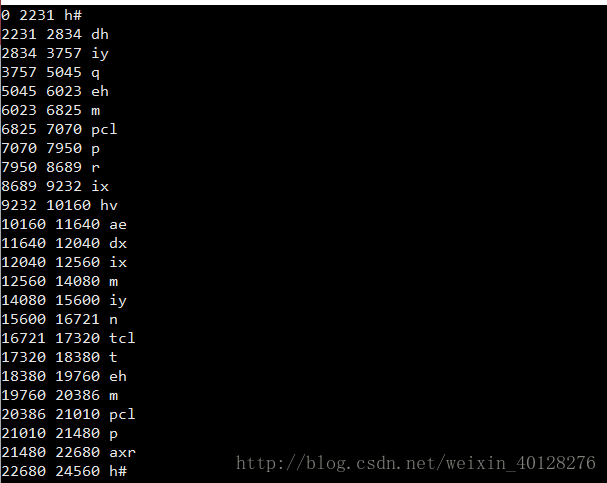
再看一下这句话的文本。

后面就是这句话没问题,0-24679肯定就是时间了。
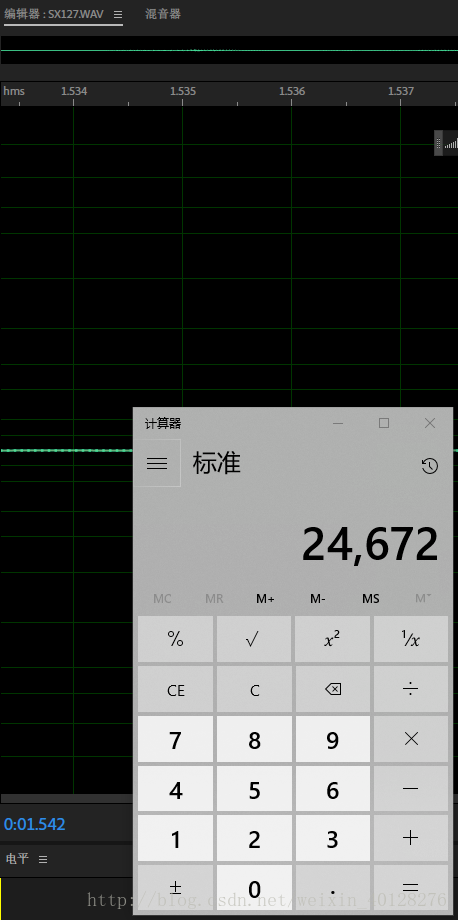
我们看到时间是1.543,因为是16000的采样率,所以一共采24672个点,和24679基本一致(差几个估计是时间精度不够)。
至此,PHN文件我们已经非常了解了。
start_time end_time phoneme
应该是这个格式。
接下来我们先了解一下一个包:glob
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。查找文件只用到三个匹配符:"*", "?", "[]"。"*"匹配0个或多个字符;"?"匹配单个字符;"[]"匹配指定范围内的字符,如:[0-9]匹配数字。
用法也很简单。
import globwav_file = glob.glob('data_path')
举个例子:
import glob
wav_file = glob.glob('./train/*/*/*.wav')用的时候要注意下相对路径和绝对路径。
这样我们就得到了数据库中所有wav的名字了,被存在一个list中。
接下来学习一个alienment的软件 ,基于kaldi做的。
montreal-forced-aligner。
这是他们的git:https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner
这是他们的官方文档:http://montreal-forced-aligner.readthedocs.io/en/latest/
其实这个工具非常好用,因为我们是汉字的对齐,所以就不使用他们的预训练模型了。
我们直接使用release版本。
解压后有3个文件夹,其中的bin里面就是我们需要的程序。
看两个简单的命令来了解一下。
bin/mfa_align /path/to/librispeech/dataset /path/to/librispeech/lexicon.txt english ~/Documents/aligned_librispeech这个是直接对齐的命令,第一个参数是你的数据库,第二个参数是字典,第三个参数是你使用的模型。
bin/mfa_train_and_align /path/to/librispeech/dataset /path/to/librispeech/lexicon.txt ~/Documents/aligned_librispeech这个是训练模型命令,第一个参数是数据库,第二个但是字典,第三个是你保存模型的位置。
下面我们继续学习一个分词工具包:jieba
因为我们要进行中文的txt2phn。
所以我们不得不面临分词的问题,接下来我们继续来看看如何中文分词。
python有个很好的工具包jieba
安装非常容易。python2或3均可。
pip install jieba这个包也是非常的简单,Git上有详细说明,这里就不赘述了。
用这个工具把文本全部分割好就可以对齐了。
后面的过程就不赘述了,大概就是分割-对齐-最后形成相同格式。。。
可能有点烂尾,如果也在做相同过程碰到了一些问题可以给我留言,Emm
这篇关于通过wav文件和text文件训练出phoneme文件的过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








