本文主要是介绍Brain:机器学习揭示精神分裂症两个不同的神经解剖亚型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《本文同步发布于“脑之说”微信公众号,欢迎搜索关注~~》
精神分裂症的神经生物学异质性了解甚少,并混淆了当前的分析。我们在一个多机构多种族队列中研究了神经解剖亚型,使用新的半监督机器学习方法,旨在发现与疾病相关的模式,而不是正常的解剖变异。研究人员对307名确诊精神分裂症患者和364名健康对照者进行了结构MRI和临床测量分析。灰质、白质和脑脊液局部体积测量被用来识别独特的和可重复的精神分裂症神经解剖亚型。两种不同的神经解剖亚型被发现。亚型1表现出广泛更低的灰质体积,主要分布于下丘脑、伏隔核、内侧颞叶、内侧前额叶/额叶和岛叶皮质。亚型2显示基底神经节和内囊体积增加,其他脑体积正常。在亚型1中灰质体积与病程呈负相关(r = -0.201, P = 0.016),而在亚型2中则不相关(r = -0.045, P = 0.652),这可能暗示了不同的潜在神经病理过程。子类型没有年龄(t = -1.603, df = 305, P = 0.109),性别(df =1χ2 = 0.013,P = 0.910),疾病持续时间(t = -0.167, df = 277, P =0.868),抗精神病剂(t = -0.439, df = 210, P = 0.521),发病年龄(t = -1.355, df = 277, P = 0.177),阳性症状(t =0.249, df = 289, P = 0.803),阴性症状(t = 0.151, df = 289, P= 0.879)或抗精神病类型(卡方= 6.670,df =3, P = 0.083)差异。亚型 1的受教育程度低于亚型2(卡方= 6.389,df = 2, P = 0.041)。总之,我们发现了两种截然不同且高度可再生的神经解剖亚型。亚型1显示与病程相关的广泛体积减少,以及更差的发病前功能。亚型2除基底神经节和内囊较大外,解剖结构稳定正常,不能用抗精神病药剂量解释。这些亚型挑战了脑容量损失是精神分裂症的一个普遍特征的概念,并暗示了不同的病因。它们可以为丰富和分层临床试验和精确诊断提供策略。
1.简述
精神分裂症的诊断因个体临床表现、病程、治疗反应、功能结果和生物标志物的表达多变而被混淆。先前的神经影像学研究主要采用二元病例对照设计来研究精神分裂症的神经解剖学异常。基于神经解剖数据客观地定义生物亚型对进一步研究具有重要意义。之前的“biotype”研究已经检查了其他表型,包括基因,功能磁共振成像,或电生理和认知的组合。
描述精神分裂症脑亚型的进展需要增加样本量,增加样本异质性,以及在不同地点和种族之间推广的方法学进展。为了应对这一挑战,我们建立了一个跨越三个大陆的联盟,称为PHENOM(“通过维度神经成像评估精神病异质性”)。然后,我们试图通过应用最近开发的半监督机器学习方法HYDRA(通过鉴别分析的异质性)来识别神经解剖亚型。HYDRA从根本上不同于以往的聚类方法,因为它专门通过建模与健康对照组的差异来聚集疾病影响,而不是直接聚集患者。这种方法通过限制由年龄、性别、扫描仪、种族和其他因素引入的混杂变异的影响,帮助确定真正的疾病亚型。这是因为所有这些混杂的变异已经出现在对照组中,而只有患者和对照组之间的差异,可能是由于病理过程,是聚集的。我们假设,这种方法将客观地揭示以前在典型的病例对照设计中被掩盖的不同的神经解剖亚型,并且不能用疾病持续时间或抗精神病药物剂量来解释。
2.方法简述
本研究调查了来自三个地点的PHENOM的子样本。1.5T采集结构影像,年龄在45岁及以下,共307个精神分裂症患者,364个健康对照。结构像质量控制,然后进行多图集分隔以得到灰质、白质和脑脊液ROI。生成灰质、白质、脑脊液的局部体积图。去除地点效应,进行年龄和性别协变量校正。对ROI体积测量使用HYDRA识别亚型。进行亚型可重复性分析。用局部线性多变量判别统计映射(MIDAS)进行体素水平体积的分析。进行亚型与临床测度相关性分析。
3. 结果
3.1 HYDRA揭示了两种高度可重复的亚型
在标准病例控制比较中,体积增加和减少都出现了,但不清楚这是由所有病例还是部分病例贡献的。HYDRA解决了这个问题。将HYDRA应用于结构ROI的体积来识别亚型。用调整的Rand 因子(ARI)来评估多个分辨率(2-8聚类)的聚类一致性,它相对而言对聚类数K不敏感。在K = 1时的ARI是没有意义的,因为它对应的是根据定义将所有患者分配到同一组的简单解决方案。然而,如果样本同质性较好(最优K=1),对于其他K值,ARI就更低。在K=2时有最大可重复性,ARI = 0.616. K =3-8 时,ARI约为0.4,低于K=2. 不同K和地点的病人分布在补充表2. K=2,在每个地点,有更多的病人被分配到亚型1. 为了决定聚类的统计意义,我们将每个聚类的ARI与使用排列检验生成的零分布进行了比较。K = 2时的ARI高于零分布(图1),K=3没有。K=4-8也高于零分布,但K=3或更多引入了地点间的性别、年龄和地点效应。K = 2解决方案的卓越的再现性也在分裂的比较中再现,与其他集群解决方案相比(补充图3)。K=2,voxel-wise体积模式在分裂1和分裂2再现,其他K没有(补充图4和5)。此外,亚型的再现性分析进行了使用leave-one-site-out方法(补充图6)。从这三个地点使用leave-one-site-out预测的亚型1和亚型2 与将三个地点结合起来的原始分配相比较(补充表2:K = 2)。分配给同一亚型重叠的患者比例为86.72%(83.33%的site1中,86.21%在site2,和90.63%在site3)。这两个亚型在所有地点可再现(补充图7)。鉴于这些收敛结果,后继的分析集中于这两个高度可再生的亚型。

图1 与随机排列的零分布相比,不同K的ARI的统计显著性
3.2 亚型表现出不同的神经解剖损伤
亚型显示明显差异voxel-wise神经解剖学的损伤的模式(图2)。亚型1显示一个分布式灰质损伤模式,与健康 (图2)和亚型2相比(补充图8)。与健康对照组相比,亚型1异常中最突出的在丘脑 ,伏隔核,内侧颞叶,内侧前额叶,和岛叶皮质。此外,亚型1显示白质体积普遍减少(图2C)。相比之下,亚型2有正常的大脑结构,除了基底神经节的灰质体积较大(苍白球、壳核和部分尾状核)(图2B)。与健康对照组相比,亚型2的深部结构中白质体积也相对较大,尤其是内囊(图2D)。与健康对照组相比,这两种亚型的脑脊液均轻度升高,主要出现在第三脑室和额叶半球间裂(补充图9)。
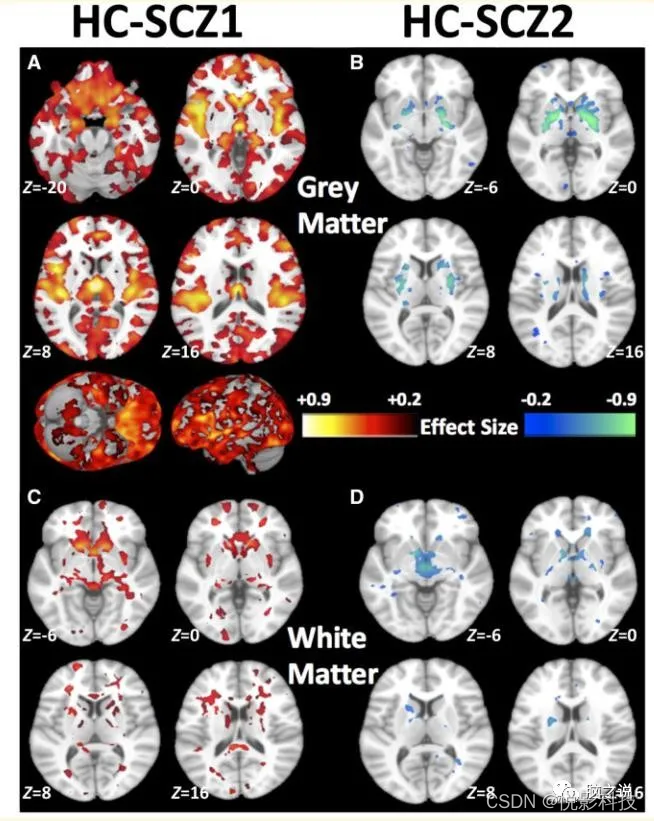
图2 两种亚型的灰、白质体积模式
3.3 亚型在leave-one-site-out验证中表现鲁棒的可重复性
使用leave-one-site-out方法预测亚型显示良好的再现性(图3)通过所有的地点在一起(图2) 获得的结果。与上述结果一致,亚型1的异常很广泛,丘脑中最明显,伏隔核,内侧颞,内侧前额叶,和岛叶皮质(图3A)和亚型2在基底节区体积较大(图3B)。与Subtype 2相比,Subtype 1也表现出灰质缺陷的分布模式(Supplementary Fig 10),这与上述结果(SupplementaryFig 8)是一致的。
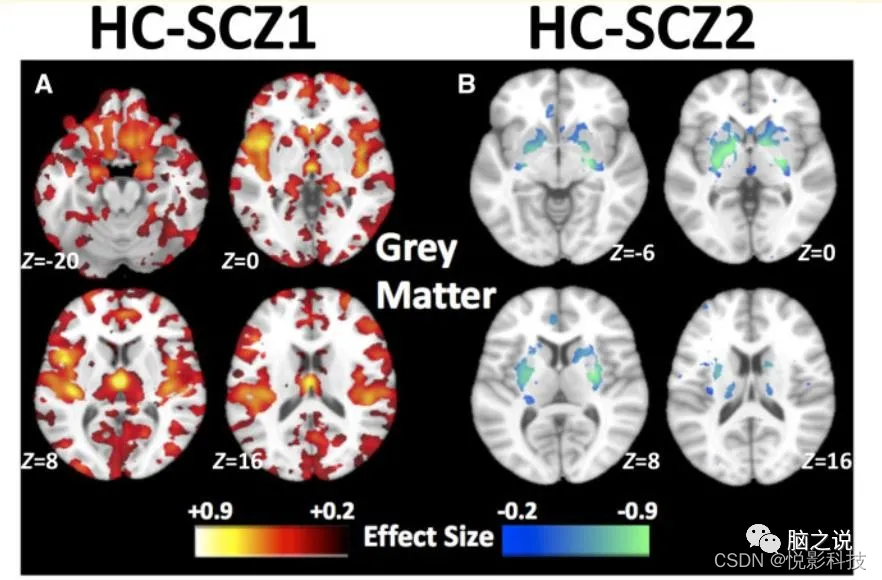
图3 可重复性分析
3.4 敏感性分析提供了收敛结果
接着,进行大量敏感性分析,确保这些结果不会受样本量、性别、药物、慢性病、组织对比影响。该分析产生的亚型模式与原分析一致。
3.5 亚型1的受教育程度低
亚型1受教育程度低,但两个亚型在年龄、性别、病程、抗药性、发病年龄、症状严重性、抗药类型无差异。
3.6 亚型1灰质体积与病程负相关
亚型1灰质体积与疾病持续时间负相关(图4),亚型2没有。
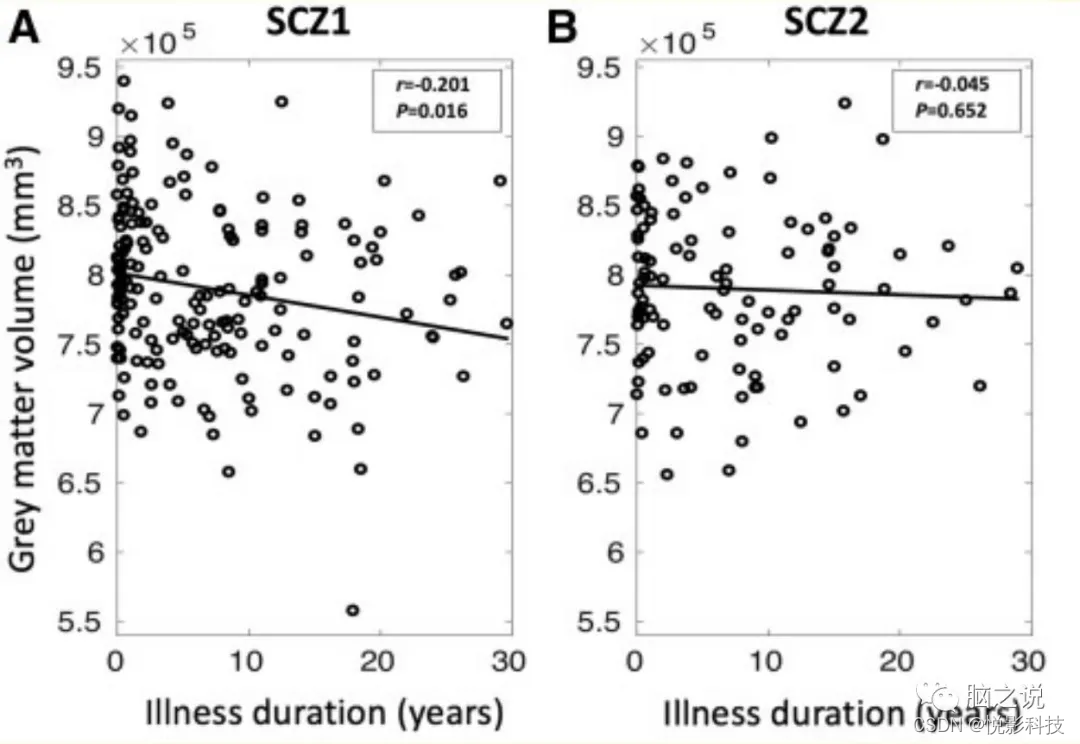
图4 两个亚型灰质体积与病程相关性
4. 讨论
我们识别出两个明显不同的亚型,与健康对照相比,亚型1 表现出广泛的灰质体积减少,亚型2 与正常的灰、白质体积相比,在基底节和内囊体积增加。研究的发现总结在图5.

图5 亚型1和亚型2
这两种亚型对置换试验、分离样本试验、单点排除试验、性别专门分析、抗精神病药物剂量调整和对病程少于2年的患者的限制都是稳健的。重要的是,标准的病例对照比较掩盖了这样一个事实,即精神分裂症的平均差异来自于不同的神经解剖亚型,灰质减少只占到大约三分之二的患者群体,大约三分之一的患者的皮质下增加。最近使用规范模型的研究也表明,精神分裂症的平均群体差异掩盖了生物异质性,客观地定义生物亚型是合乎逻辑的下一步。根据对神经影像学异质性的新认识,我们的分析揭示了(相对粗糙的)临床表型无法检测到的亚型,但这些亚型可能尚未被发现的临床含义。因此,我们的研究结果挑战了精神分裂症患者脑容量普遍减少的主流观点,澄清了以前的病例对照研究结果,并首次提出了个体精神分裂症患者不同亚型之间的根本大脑差异,这些亚型不是通过慢性或标准临床措施明确定义的。
5. 结论
总之,我们发现了精神分裂症的两个明显不同的神经解剖亚型,因此表明了这种疾病的两个神经解剖轴。与健康对照组相比,亚型1的灰质体积较低,呈广泛分布,而亚型2的基底节区和内囊相对较大,但皮质解剖正常。这两种亚型在没有直接解释潜在神经解剖学异质性的病例对照研究或临床亚型研究中未被揭示。未来的研究将提供关于这些亚型与大脑结构和功能的其他方面的更详细的图片,临床特征包括认知功能,急性治疗反应,纵向进展和病因学。这些“亚型指纹”将在高危人群、亚综合和流行病学样本中被追踪。通过额外的研究,这些亚型可以为精确的临床护理做出贡献,通过广泛使用的临床脑成像方法来解释诊断、预后和治疗中的生物异质性。
注:解读不易,请多多转发支持,您的每一次转发是对我们最好的支持!本文原文及附加材料,请添加赵老师微信索要(微信号:15560177218)
这篇关于Brain:机器学习揭示精神分裂症两个不同的神经解剖亚型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





