本文主要是介绍C++实现AC自动机,剪枝、双数组压缩字典树!详解双数组前缀树(Double-Array Trie)剪枝字典树(Patricia Trie),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码在:github.com/becomequantum
最近研究了一下字典树,什么AC自动机,双数组压缩字典树,剪枝字典树都自己写代码实现了一下。这本该是本科学数据结构时该玩明白的东西,我到现在才会玩。本视频主要介绍一下双数组和剪枝这两种压缩字典树的方式,尤其是双数组。我发现中文科普双数组字典树的文章都没把问题讲清楚,我看了好几篇文章都没看明白,后来还是看了这篇英文文章才搞明白。不得不说,科普文章还是老外写的更加通俗易懂。其实双数组压缩这个方法的确很简单。

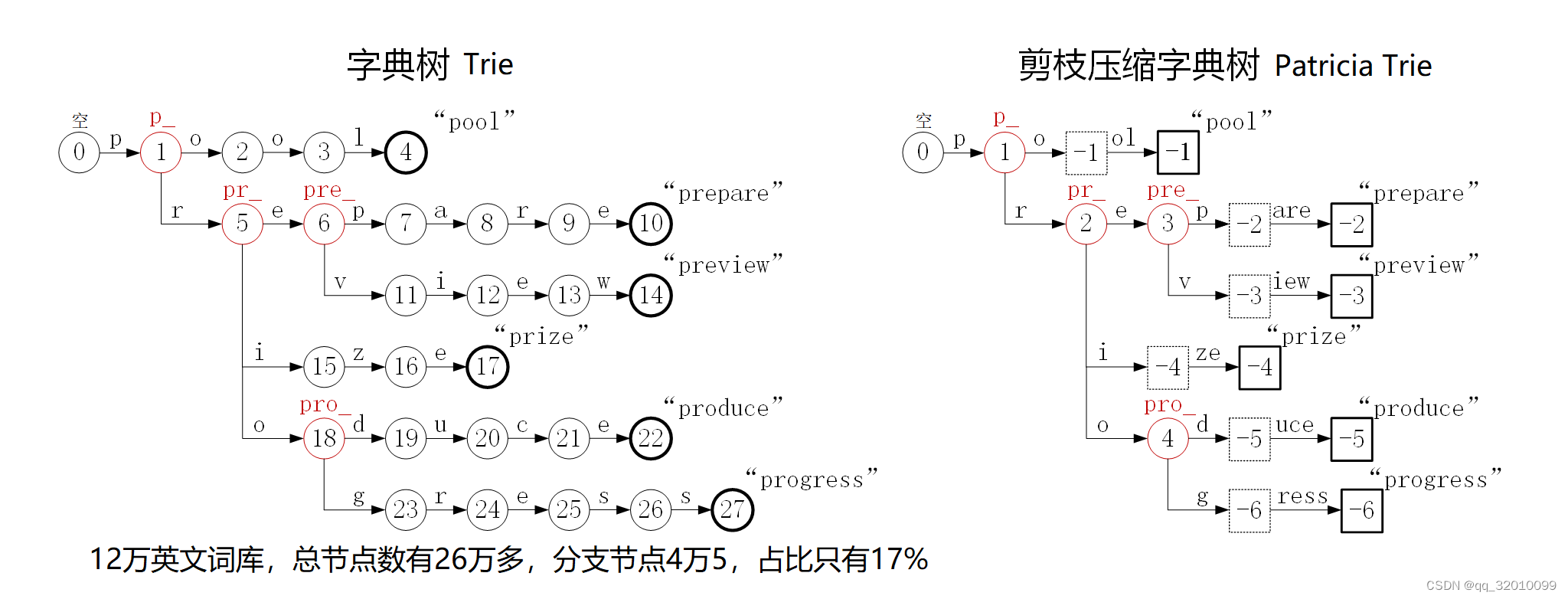
先来说剪枝字典树,因为它的概念一看图就明白了,“剪枝”是我给起的名字,英文名叫“Patricia Trie”。请看上图,左边是基础的字典树,可以看出,在这个包含六个单词的树中,一共有节点28个,但有分支的节点,也就是子节点不止一个的节点,就只有上图中标为红色的四个。我在Github上找了个有12万单词的英文词库做了下统计,形成的字典树中分支节点占比只有百分之十七。要知道,字典树中的这些节点和它们之间的转换关系,都是存在一个二维数组中的。上面这个小字典树的状态转换表就如下图所示:

这个表就是我的代码打印出来的。这是一个26乘28的表,26就是英文字母的个数。如果是那个12万词库,这个表就是26乘26万。听起来好像也不是很大啊!是的,英文这样弄还行,那要是中文呢?万国码里的汉字有两万多个啊!我试了一下,中文字典树如果想建一个两万多乘多少的表,结果就直接实现不了,数组大小超标了。仔细看上面这个表,大家猜这个表的利用率有多少呢?也就是表中存的节点号的个数除以总容量。我本想着写点代码统计一下,结果思忖了一下发现这个利用率就不需要统计,因为它就恒等于二十六分之一。大家可以仔细看上表琢磨一下这是为啥。
所以说用二维数组存字典树效率是很低的,要是中文那就更低了,低到都实现不了。一个改进办法就是把数组换成哈希表,这个很好实现啊,C++里用模板换一下就行了,一套代码就可以搞定这两种类型的节点表。改为哈希表之后,中文字典树就能实现了,但问题是,改为哈希表之后查词会慢些,毕竟读哈希表没有读数组块。我写代码实测也的确是这样。所以还得想办法,办法之一就是把字典树中的线性分支给压缩合并掉,如上图右边所示。
这样字典树里就会存在第二种节点,在上图右边用方框表示,节点编号我用负数表示,以示区别。第二种节点我管它叫尾枝节点。这种节点里不需要存转换表,但需要存它包含的词尾上的那几个字母。当从分支节点查到尾枝节点时,就不需要再往下查了,直接改为字串比较,把待查词剩下的字母和节点里存的比一下就行了。这个改进方法看起来还不错,既减少了节点数量,又把查几次表改为了字串比较,理论上是会更快一些的。
我没有写代码实现如何一点点的构建这样的字典树,而是写了个整体剪枝代码,也就是把一个已经构建好的基础字典树一下子改造成剪枝字典树。这个改造算法在深度优先遍历的基础上加些内容就能实现。改造完测了一下速度发现,查词速度还没基础字典树快,似乎改了个寂寞。这大概是因为我的实现方法还不够优化,多了个节点又会多一个数组存储这种节点。查字典树是避免不了随机读取数据的,多一种节点就意味着,字典树要查的数据更加分散,缓存没命中的概率就会增加,进而导致整体耗时是增加了,不是减小了。所以要想剪枝字典树效率更高,还得在数据存储的紧凑性上继续想办法。

接着说双数组压缩法,这个方法的意思就是,把上面这么多行稀疏数组中的内容都塞进两个数组里。那这该咋塞呢?我们从上表中截取三行,若干列内容来说明。请看上面这个小点的表,我们先在下面新建一个存储“下个状态”的数组,它就只有一行。然后把上面表中后两行的数据直接往下放进去。这样放是能放,但放一块之后不就不知道某个数据原来是来自哪一行了吗?于是就还需要另一个,在英文文献中叫做check的数组,这个数组会在“下个状态”号数据对应的位置存它原来是属于哪一行。

如上图所示,“下个状态”行中,19,23的下面都存着18,示意着它们都来自“当前状态号”是18的那一行。这样在另外一行给“下个状态”行中的数据打上标签,就知道它是来自哪一行了。接下来的问题就是,第一行的13和第二行的17位置相同咋办?好办,错个位置,找个空塞进去就行。那这又会带来一个新问题,原来13是在字母e下面,现在跑到f下面去了,那又该怎么通过输入字符值检索到它呢?这就还需要一个base数组,里面存的是,每个当前状态号,在查“下个状态”表时需要的起始位置。

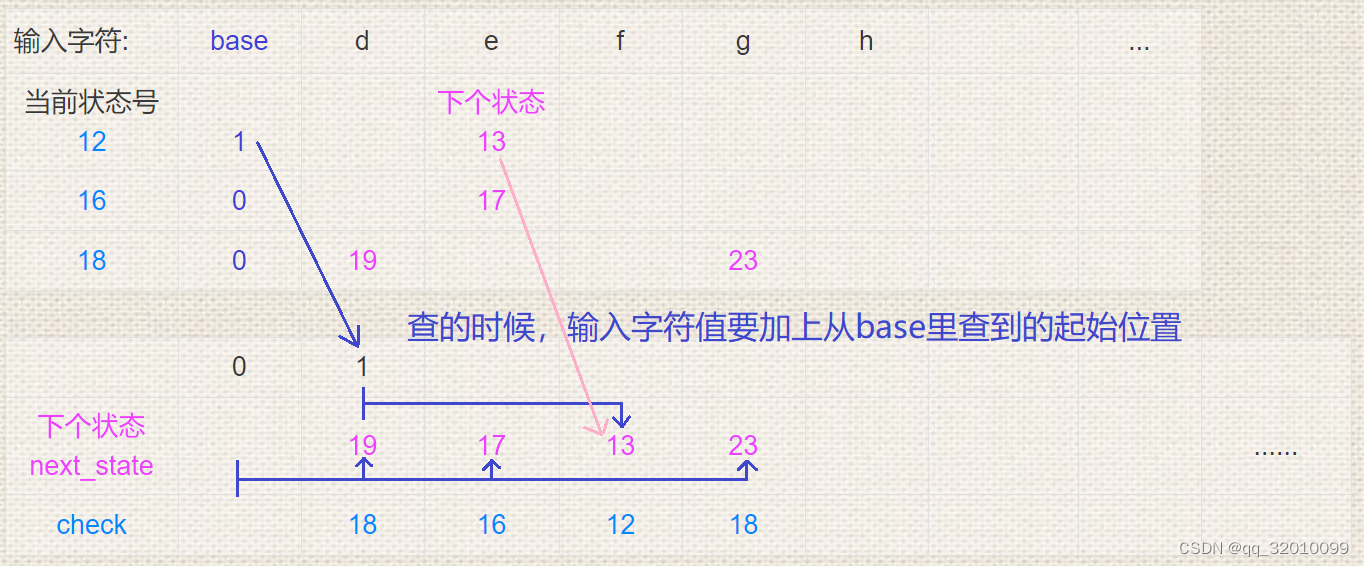
比如要查当前状态12,在输入为e时的下个状态号,我们需要先用base[12],把它的查表起始位置找出来,在上面这个例子中它是1。然后用这个1加上e的值,就得到了去查“下个状态”数组的索引位置。这时还不能确定这个位置的数据就是属于状态12的,还得用check[base[12] + e],去看看check数组里该位置的标签是不是12,如果是12,那就跳转到这下个状态,如果不是,那就是没查到下个状态。
双数组的原理就是这样了,这不明明有三个数组吗?双数组实际上指的是把上述的base和next_state合并成了一个数组。同样的,我也没写一个个插入单词,构建双数组字典树的代码,只写了个把构建好的字典树的状态表压缩成双数组的代码。这个代码要做的事情就是见缝插针,通过顺序递增base值,看看增加到多少的时候能正好能把当前行的数据都塞进next_state和check数组中空的位置中。这两个数组的长度大概是比所有节点数大一点点。大家猜猜这两个数组的利用率是多少?几乎接近百分之一百,因为很多行都只有一两个数据,很好塞。

经过实测发现,双数组压缩之后,查询效率有成倍的提升。双数组查询的时候,看起来所需要的运算多了一点点,没有直接查一个数组那么简单。但双数组能让被查数据变得更加紧凑,这样应该能提升CPU缓存命中率,所以耗时反而减少了。
另外我也写了在字典树的基础上构建AC自动机的代码,这回是广度优先遍历,顺便推荐一下上面这个没人看的视频,这位老师讲Fail指针的构建讲了好几遍,讲的比较清楚。我在这就懒得讲了,有兴趣的朋友可以去看代码,俺写的代码里注释比较多,比较好懂。
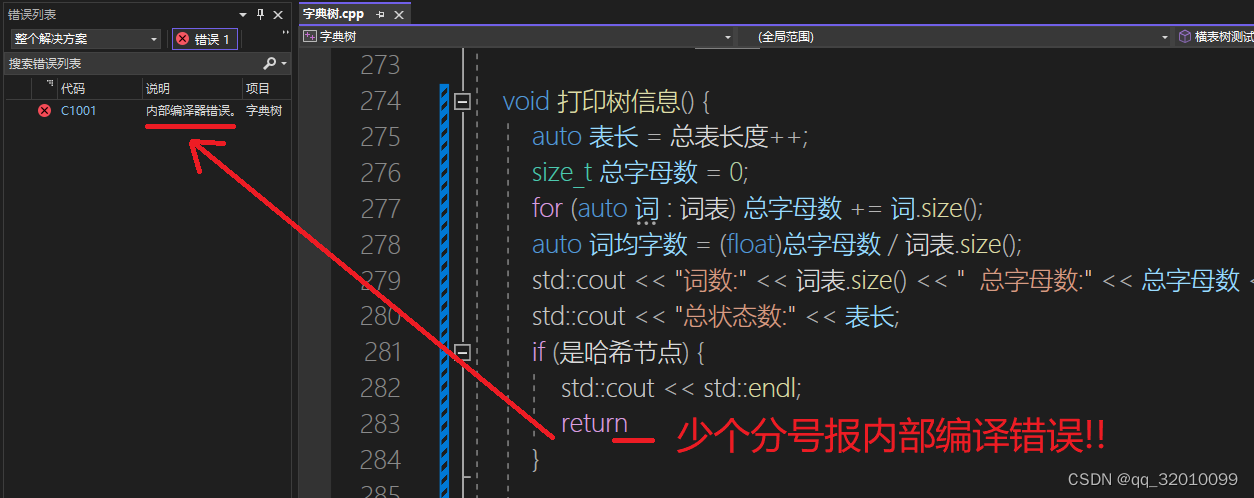
最后再来吐槽一下C++,如上图所示,上面这段代码,我就return后面少写了个分号,结果就报了个莫名其妙的“内部编译器错误”。当然不是所有没打分号的情况都会报这个错,而是在某些特定情况下会报。这都2023年了,C++编译器的报错能力还是不行,远不如Rust。不过从灵活性上来说,还是C++最好。比如模板编程,C++里的模板本质就是宏替换,没做过多的限制。Rust里的模板和C sharp比较像,限制较多,而这反而让有些代码不好写。C++里的模板还是挺好用的,两个类型只要部分形式相同,就都能往模板里套,驴头和马嘴都可以找个共同点套一个模板里去。
大脑视觉皮层运作机理简介,CNN其实不像它_哔哩哔哩_bilibili
这篇关于C++实现AC自动机,剪枝、双数组压缩字典树!详解双数组前缀树(Double-Array Trie)剪枝字典树(Patricia Trie)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!