本文主要是介绍边写代码边学习之mlflow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 简介
MLflow 是一个多功能、可扩展的开源平台,用于管理整个机器学习生命周期的工作流程和工件。 它与许多流行的 ML 库内置集成,但可以与任何库、算法或部署工具一起使用。 它被设计为可扩展的,因此您可以编写插件来支持新的工作流程、库和工具。

MLflow 有五个组件:
MLflow Tracking:用于在运行机器学习代码时记录参数、代码版本、指标、模型环境依赖项和模型工件的 API。 MLflow Tracking 有一个用于查看和比较运行及其结果的 UI。 MLflow Tracking UI 中的这张图片显示了将指标(学习率和动量)与损失指标联系起来的图表:
MLflow Models::一种模型打包格式和工具套件,可让您轻松部署经过训练的模型(来自任何 ML 库),以便在 Docker、Apache Spark、Databricks、Azure ML 和 AWS SageMaker 等平台上进行批量或实时推理。 此图显示了 MLflow Tracking UI 的运行详细信息及其 MLflow 模型的视图。 您可以看到模型目录中的工件包括模型权重、描述模型环境和依赖项的文件以及用于加载模型并使用模型进行推理的示例代码:
MLflow Model Registry:集中式模型存储、API 集和 UI,专注于 MLflow 模型的批准、质量保证和部署。
MLflow Projects:一种用于打包可重用数据科学代码的标准格式,可以使用不同的参数运行来训练模型、可视化数据或执行任何其他数据科学任务。
MLflow Recipes:预定义模板,用于为各种常见任务(包括分类和回归)开发高质量模型。
2. 代码实践
2.1. 安装mlflow
pip install mlflow2.2. 启动mlflow
方式一:命令窗口 -- 只能查看本地的数据
mlflow ui方式二:启动一个server 跟踪每一次运行的数据
mlflow server用方式二的话,你要添加下面代码
mlflow.set_tracking_uri("http://192.168.0.1:5000")
mlflow.autolog() # Or other tracking functions2.3. 用方式二启动之后你发现创建了下面文件夹

2.4. 访问mlflow
localhost:5000

运行下面代码测试。加三个参数(config_value, param1和param2), 加一个metric和一个文件
log_params: 加参数
log_metric: 加metric
log_artifact : 加相关的文件
import os
from random import random, randint
from mlflow import log_metric, log_param, log_params, log_artifacts
import mlflowif __name__ == "__main__":mlflow.set_tracking_uri("http://localhost:5000")# mlflow.autolog() # Or other tracking functions# Log a parameter (key-value pair)log_param("config_value", randint(0, 100))# Log a dictionary of parameterslog_params({"param1": randint(0, 100), "param2": randint(0, 100)})# Log a metric; metrics can be updated throughout the runlog_metric("accuracy", random() / 2.0)log_metric("accuracy", random() + 0.1)log_metric("accuracy", random() + 0.2)# Log an artifact (output file)if not os.path.exists("outputs"):os.makedirs("outputs")with open("outputs/test.txt", "w") as f:f.write("hello world!")log_artifacts("outputs")之后你会发现在mlflow中出现一条实验数据

点击之后,你会发现下面数据。三个参数,一个metrics数据以及一个在artifacts下的文件。
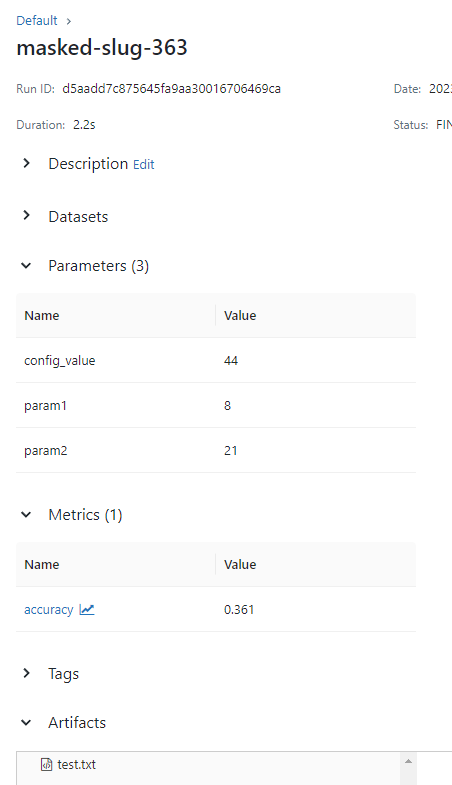
运行下面实验代码
import mlflowfrom sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressormlflow.set_tracking_uri("http://localhost:5000")
mlflow.autolog()db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)# Create and train models.
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
rf.fit(X_train, y_train)# Use the model to make predictions on the test dataset.
predictions = rf.predict(X_test)
之后你会发现mlflow server 里出现了例外一条实验数据
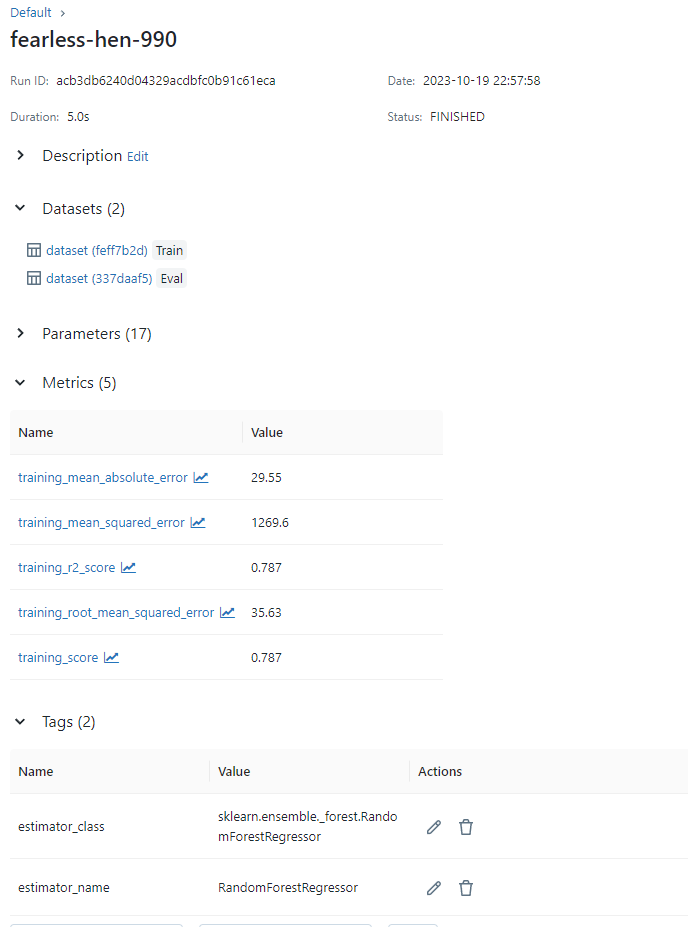
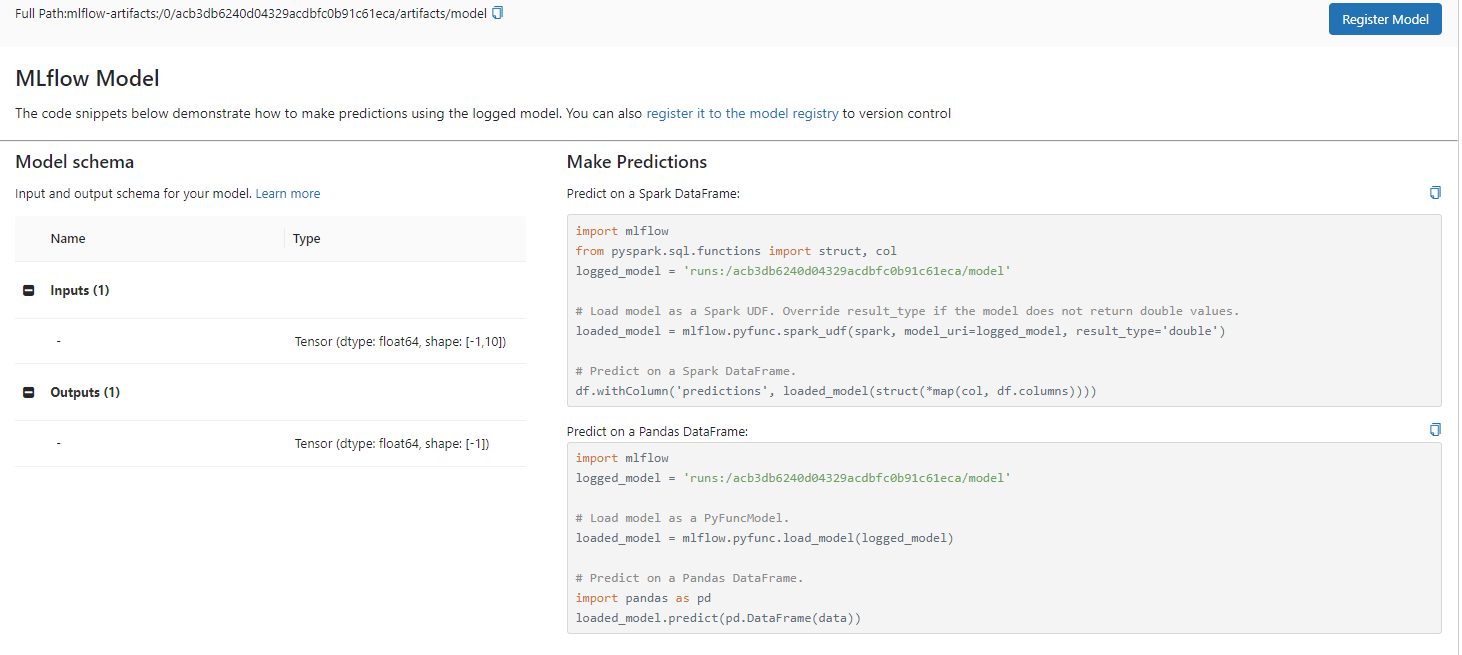
在mlflow server 取出你的模型做测试
import mlflowfrom sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
mlflow.set_tracking_uri("http://localhost:5000")db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)logged_model = 'runs:/acb3db6240d04329acdbfc0b91c61eca/model'# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model)predictions = loaded_model.predict(X_test[0:10])
print(predictions)运行结果
[117.78565758 153.06072713 89.82530357 181.60250404 221.44249587125.6076472 106.04385223 94.37692115 105.1824106 139.17538236]
参考资料
MLflow - A platform for the machine learning lifecycle | MLflow
这篇关于边写代码边学习之mlflow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




