欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
作者:陈峻
近期,我拜访了一家文化传播公司的 IT 运维总监 Tim,他向我讲述了他的团队是如何像当年玩《大航海时代》那样将 IT 系统的战舰越造越大,并使之在企业运营的海洋中平稳前行的。

在此,我将他的心路历程分享出来,希望能够帮助您改变那种像小仓鼠一样一直在环形轮上盲目地“跑酷”状态。
纵然练就“72变”,也无法笑对“81难”
该文化公司成立于 2013 年,他们最初从简单的“PC 服务器 + 二手三层交换 + 托管服务器”这样的硬件架构起步,既要对内满足员工的“上网 + 邮件 + 文件共享 + 存储”,又要对外提供“官网 + 视频上传/下载”的服务。
在 IT 系统建成初期,由于处于运维“四少”,即设备少、应用少,流程少,问题少的状态,他和另一名同事组成的“哼哈二将”模式完全可以 hold 住各种与 Ops 相关的需求和问题。
但是随着公司这几年来的多元化发展,各种看得见的设备和看不见的软件越来越多,特别是“论坛 + 会员博客 + 微官网 + 在线订单 + 移动支付 + 远程访问”等业务所带动的系统复杂性,纵然他们不断练就七十二变,也无法笑对前方的八十一难。
在扩大运维团队的同时,他们通过整合资源、逐步转变并提升了 Ops 的相关观念和操作模式,摸索出了一条具有本企业特色的 Ops+ 模式。
总的说来就是:针对整个运维生命周期中的各个方面,用三步递进的模式来逐步改进日常各项工作,即“标准化—配置与流程、自动化—操作与安全、平台化—监控与管理”。
Ops+ 运维模式初探
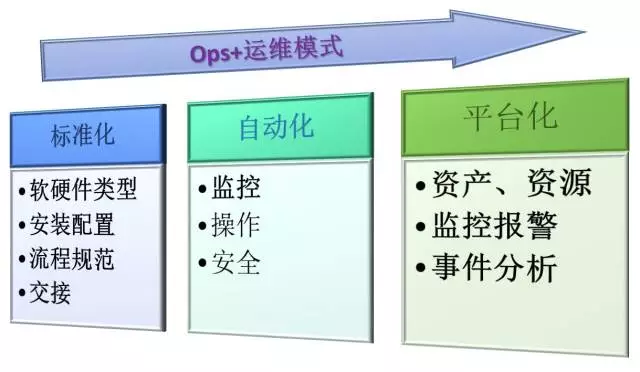
标准化—配置与流程
过去他们的运维人员过分依赖技术上的大牛,由于上手门槛较高,部门里往往充斥着个人英雄主义,当然也就造成了人员资源上的单点风险。与此同时,他们又时常被服务厂商所“绑架”。
由于各家实现方式的不尽相同,在系统出现问题的时候,要么相互推诿,要么一拥而上、各自为政。这些都给系统的正常运营埋下了不少的“雷”。
在经历数次“多么痛的领悟”之后,他们逐渐认识到标准化的重要性,并通过如下方面的实践,有效杜绝了各种“任性”。
软硬件类型标准化
无论是网络设备、服务器端、用户终端,还是操作系统和应用软件,他们都有既定的支持和首选的列表。
这样一来,在品牌和型号层面上大幅降低了不兼容性,并缩小了排查的可能性范围。
安装配置标准化
- 可参照的实施步骤文档与配图包括:
- 设备上架安装所在的机房和机架的物理位置约定。
- 网线、电源线的走向、编号和颜色等规范。
- 在服务器端,涉及到虚拟硬件资源(CPU、内存、磁盘空间、分区大小)的分配、虚拟机安装文件的准备、主机名/IP地址/默认使用目录/日志目录/代码目录的定义。
- 在用户端,通过 PXE 和 cobbler 来使用镜像文件批量安装操作系统。
- 规范服务端所用到的基础支撑软件(如 IIS)和产品应用的部署路径和配置顺序。
- 账号名称、对应的密码和权限属性、以及服务与端口的关开列表。
流程规范标准化
无论是新建发布、服务变更、事件处理、事故响应、还是项目推进等,都有可遵循的流程和清晰的操作次序图表。
交接标准化
虽然他们不像一些互联网企业那样有专门的 Dev 团队、且产品迭代也不频繁,但是他们也充分考虑到了“建转运”过程中的风险。
通过分阶段、分步骤地制定了相应的转化流程,他们实现了测试账户的及时回收,并合理区分了系统类与业务类账户与数据的迁移。
除了上述各个方面的标准化之外,他们还日常维护着诸如:硬件设备全量清单、软件应用全量清单、第三方服务提供清单、干系人联系清单等支持类文档。
这些文档多以图表的形式清晰直观地提供了各类速查的信息,同时方便了后面将要提到的平台化所进行的二次筛选与统计。
他们有专门的共享知识库(后面会提到 CMDB)来分门别类地妥善存放所有的标准化文档。
可以说,他们以标准化作为基础的 Ops+ 模式,能有效地降低人员犯低级错误的发生频率,统一整体的服务水平,提高他们的响应和处理速度,并能简化对其工作质量的考核。
自动化—操作与安全
虽说上述各个方面的标准化能够从规范的角度减少出错的可能,但是随着需要维护的设备数量和系统复杂程度的增加,各种重复性的例行操作日趋占据了维护人员的大量时间和精力。
为了控制成本和增加系统本身的鲁棒性,他们的团队在如下方面进行了自动化的尝试,进而提高了系统日常管理的效率。
监控自动化
通过软件(如 Zabbix)的自动注册与发现特性实现了:
- 机房环境、物理设备、网络流量、虚拟化、数据库、业务应用、存储状态、备份作业和日志等方面的实时自动巡检。
- 自动跟踪监测的项目除了标准的 CPU、内存、磁盘、I/O 之外,还有定制化的某项服务(如 Nginx、PHP 页面等)的 KPI 性能。
- 在显示上通过自动发现,能提供 2D 机房拓扑图、3D 机架视图、地域链路实时图、流量历史曲线图和各类应用的dashboard等。
而运维人员通过进一步点击,则可细致到每个服务自有的状态视图,以便人工分析潜在的异常并介入跟踪诊断。
操作自动化
善假于物方可事半功倍:
- 通过调用各种云服务平台所提供的 API,自动化启/停、操作和管理云端的服务。
- 运用 SaltStack 在初始化好的操作系统上部署 Nginx,运用预先定制好 sls 之类的文件对目标主机进行程序包、文件、网络配置、服务以及用户等方面的管理。
- 使用 Ansible 来实现上述标准化的安装部署方案,把多个 Shell、Python、PowerShell、Bat 等脚本串在一起执行,实现对系统和服务的流程化操作。
- 在补丁和订阅方面,他们有用到 SCCM 和 Yum 分别对服务器端的 Windows 和 Linux 进行自动化的定期更新和升级。
- 这些软件通过对版本文件的上传、分发、以及在必要时进行的回滚等实现各种版本控制与更新操作。
- 根据自动化监控到的事件进行知识关联,依照既定的规则进行自动化的初步响应,包括各种报警和服务中断保护等。
安全自动化
上述操作自动化虽然能够广受运维人员的推崇,但势必会涉及到对特权的调用和对基线的调整。
为了防范由此所带来的安全隐患和漏洞,他们也上马和启用了针对安全运维方面的自动化:
- 根据身份和访问管理(IAM)原则,安全程序能智能地识别出各种场景,如:请求 SSH 的服务在屡次尝试性登录失败后,仅有一次成功的记录。
非活跃 VPN 用户在非常规工作时间登录,并对共享文件进行频繁的移动、复制甚至是删除等操作。
某台主机向内网的其他主机发送探测扫描包;网络设备的配置在计划外的时间被更改;以及 Web 页面出现 404、401、500 等错误代码。
- 基线核查:对于主机而言,对指定目录和文件的完整性检查,对指定设备和系统的端口勘察,对指定操作系统的注册表、服务和进程、以及恶意软件 Rookit 和 WebShell 予以检查。
而对于内网的数据流量而言,则是对协议、内容和攻击签名模式的匹配检查。 - 自动合规:根据审计的流程,检查各个系统上多余/可疑的账号与组,文件/文件夹的属性/访问权限,远程访问的 IP 与账户限制,静态代码中的漏洞,各类补丁与防毒签名的更新等,并且能根据既定的 playbook 自动进行整改和加固。
平台化—监控与管理
业界喜欢用物理学上的熵理论来阐述:倘若不对 IT 系统进行人工管控的话,则会趋向于无序。
Tim 和他的运维团队认识到:如果日常运维工作完全依赖于标准化和自动化进行推进的话,很快就会陷入“中年油腻”,大家也会频繁被动地打“遭遇战”。
因此,他们基于过往的经验汇总、需求分析、当然也考虑到实际预算,设计并集成了一个具有可视化和方便管控的平台架构。该平台具体由如下三部分所组成:
资产、资源管理
做到手中有粮,心里不慌:
- 通过建立 CMDB 来存储所有的主机名、域名、IP 地址及分配范围、应用服务特征属性等资产相关的信息,从而为日常运维和问题处理提供最新且完整的信息。
下一阶段,他们将引入数据分析模块,分析一般用户和专业运维人员登录该平台后,检索知识库的方式(如题名、关键词、作者、部门等)、使用频率、驻留时间、反馈信息等。 - 在平台上融入服务资产和配置管理(Service Asset and Configuration Management,SACM)的概念,通过梳理和建立资产、应用和使用者的对应关系,平台能够快速、准确地获知新发布的服务和应用,从而自动化执行扫描、编录和后续的管理。
- 引入“容器”的概念,从资产的购置入库开始进行整个生命周期的跟踪,及时回收闲置的资产,在提高资源复用率的前提下避免了资源的浪费和设备超期服役所带来的安全隐患。
- 对关键备件状态和第三方服务合同,这两个容易被忽视的地带提供平台化的跟踪管理,为预算和决策提供数据依据。
监控报警
一站式获取策略的实施和服务的状态:
- 平台提供一致的可视化入口,实时反映:人员的操作行为(用户操作、文件处置与打印、移动设备使用)、设备与服务的运行状况、链路的连接质量与拥塞程度、数据存储与备份作业完全情况、工具与文档的更新频率等。
- 通过各种标准接口对自建的或是由第三方平台提供的云服务进行监控。例如:通过设定监控的频率和触发报警的阀值,获知资源(CPU、IOPS)的使用率、通用服务(如 HTTP、PING 等)和特定服务(如果 POST 方法、HEAD 方法)的可用状态和请求响应的时间。
事件分析
做到事前防范、事中控制、事后溯源:
- 从两个维度出发,分别抓取和过滤来自各个主机层面的系统事件和基于网络的异常流量信息,通过持续将经过整理的日志信息写入 Hbase 数据库,为后期的各种故障诊断和攻击取证提供重要的判定依据。
- 管理平台对某些事件的发生次数和频率进行统计,为了去重,系统可以对事件进一步按照其特征码的种类予以分组显示。
- 在平台上引入了应用性能分析(APM)模块,能够精确地定位到应用服务中某个 URL 的访问速度的骤降、或是用户在网站上提交某个 SQL 执行语句时的延时,这些都能协助运维人员快速定位问题。
- 平台通过关联分析,可以有效地处置风险、提出持续改进的建议,以及发现和预报可能出现的问题。
小结
我正好在采访 Tim 之前阅读过《凤凰项目——一个IT运维的传奇故事》一书,书中很多桥段与他所奉行的 Ops+ 模式遥相呼应。
在 Tim 看来,通过他们的 Ops+,运维人员提升了对系统各类隐患的发现能力、对例行操作的处理能力、对应急事故的恢复能力和对内外攻击的应对能力。
正如他自己所坦言的那样:“我们正在确保自己所维护的系统能从 run right(运行正确)稳步进化为 right run(正确地运行)”。
好了,最后低调地帮他打一下 call 吧:希望上述分享的运维“大礼包”能够如一杯泡满枸杞的保温杯一般给您在这个冬天带来一丝暖意。
文章来自: 51CTO技术栈 公众号
相关阅读
网页加速特技之 AMP
表格行与列边框样式处理的原理分析及实战应用
「腾讯云游戏开发者技术沙龙」11月24 日深圳站报名开启 畅谈游戏加速
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处
原文链接:https://cloud.tencent.com/community/article/761253?utm_source=bky
海量技术实践经验,尽在腾讯云社区!




