本文主要是介绍SiamBAN 训练过程debug记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、一些参数的图片展示
1. train.py
(1) main()
(2)def train
(3) def build_data_loader()
(4) build_opt_lr
2. model_load.py
(1) def load_pretrain
(2) def remove_prefix
(3) def check_keys
3. dataset.py
(1) class BANDataset(Dataset)
def shuffle
(2)class SubDataset(object)
(3)def _filter_zero-->class SubDataset(object)
(4) def shuffle-->class SubDataset(object)
(5) def _find_dataset--> class BANDataset(Dataset)
(6) def get_positive_pair-->class SubDataset(object)
(7) _get_bbox--> class BANDataset(Dataset)
4. lr_scheduler.py
(1) def _build_warm_up_scheduler
(2) class WarmUPScheduler
5.distributed.py
(1) class DistModule
(2) broadcast_params
6. model_builder.py
7. augmentation.py
(1) def __call__
(2) _shift_scale_aug
8.point_target.py
二、一些关键部分的入口以及代码
1. 搭建主干网络以及构造模型
2. 加载Rsnet预训练骨干的参数
3. 建立dataset loader
4. 导入数据集的入口
5. 训练时打印的出处
(1) 刚开始准备的阶段
(2) 开头时打印的config内容
(3) Epoch 啥的
(4) progress 啥的
(5) 模型的模块结构
6. 数据送入模型的入口
7. 分类标签和回归标签的创建
8. 损失函数的使用
9. 原输入图片为(511,511,3),resize到输入网络的尺寸的入口
10.正样本随机选16个,负样本随机选48个入口
11. 输入shape 通道转成对应的3通道 (3,255,255)以及(3,127,127)入口
12 日志文件创建入口
13. 更改数据集导入路径啥的设置
14. 截取训练数据的入口
15 .最终训练数据的每轮epoch的大小
三、 网络结构
一、一些参数的图片展示
1. train.py
(1) main()
optimizer

lr_scheduler

dist_model

(2)def train
average_meter
train_loader
data

outputs
batch_info (first)

v
batch_info(second)

average_meter

v (batch_info)
(3) def build_data_loader()
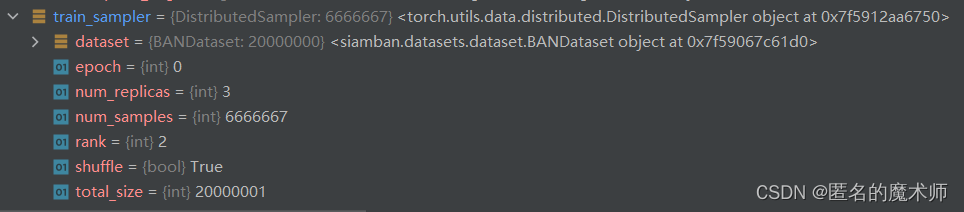
train_dataset

train_sampler
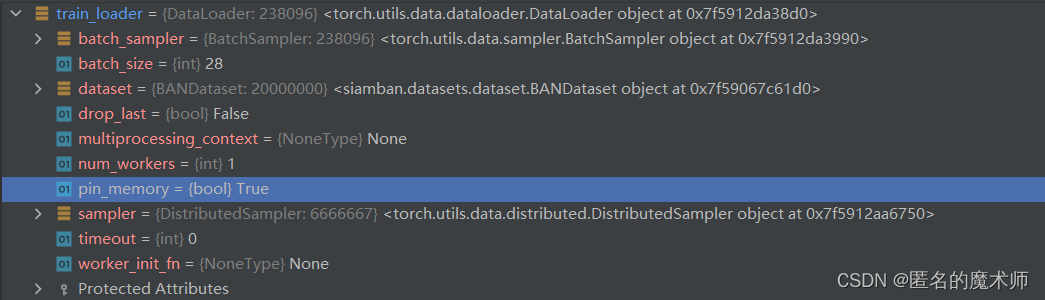
train_loader
(4) build_opt_lr
model




param

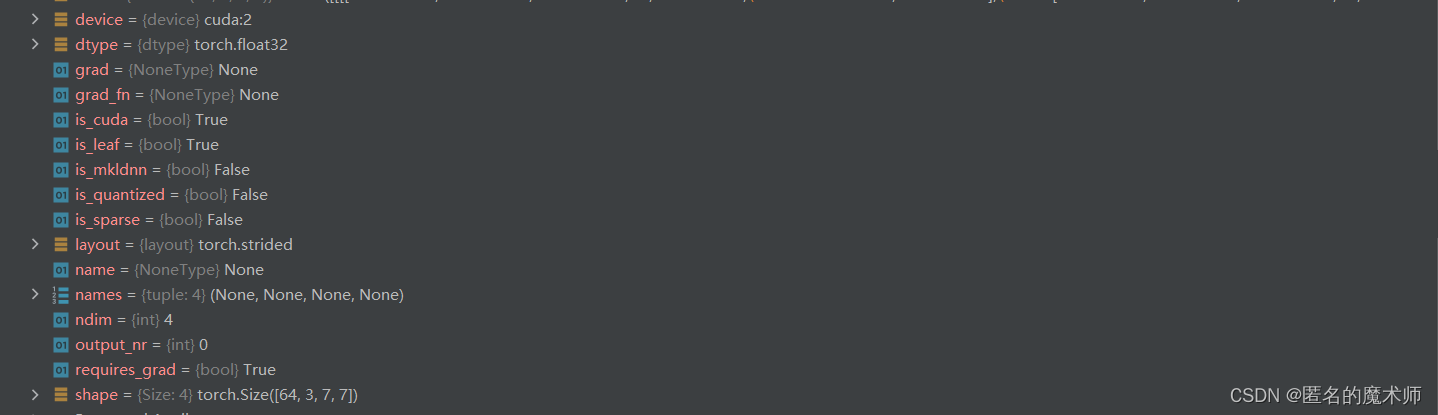
m
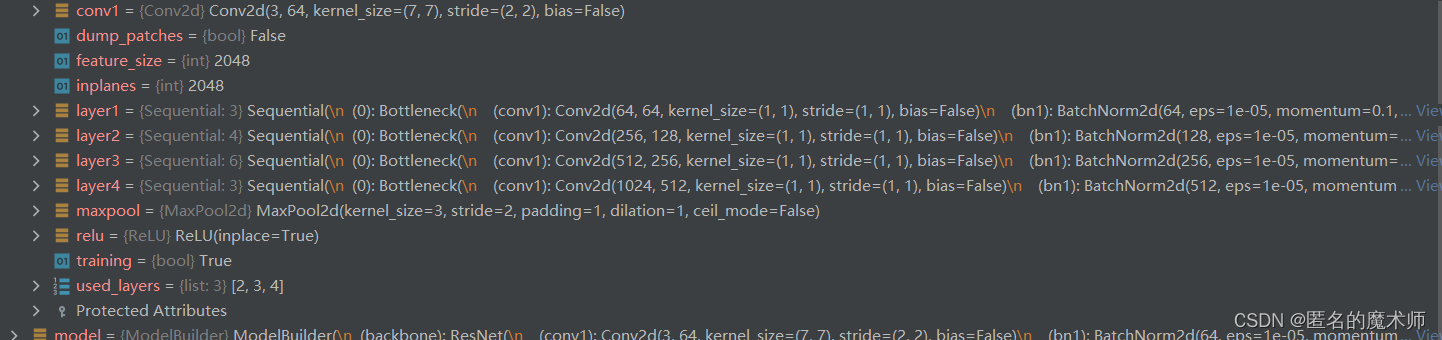
trainable_params (first)

trainable_params (second)

trainable_params (third)

optimizer

lr_scheduler (first)

lr_scheduler (second)

2. model_load.py
(1) def load_pretrain
第一个
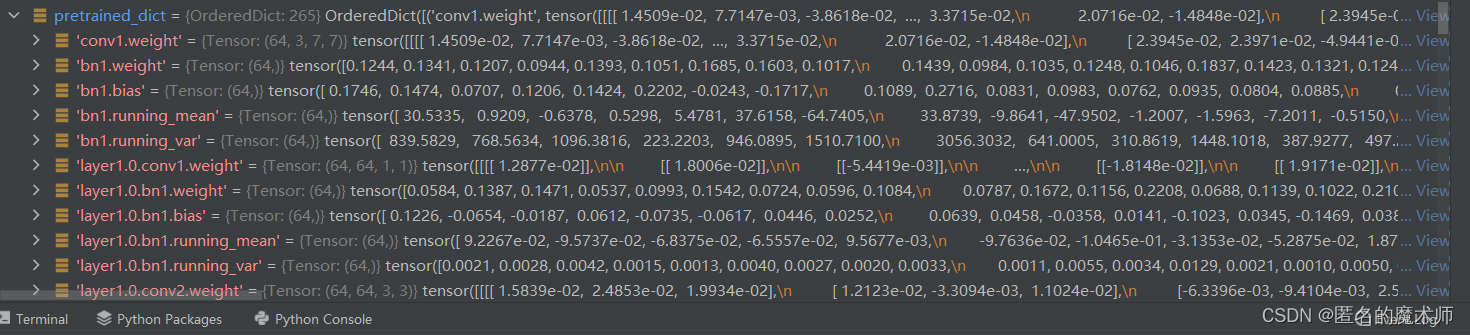
经过remove_prefix后

(2) def remove_prefix

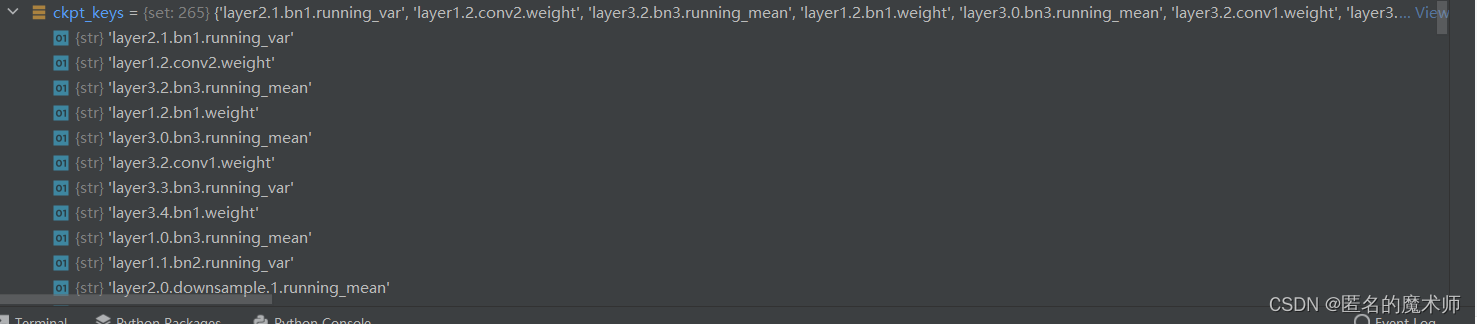
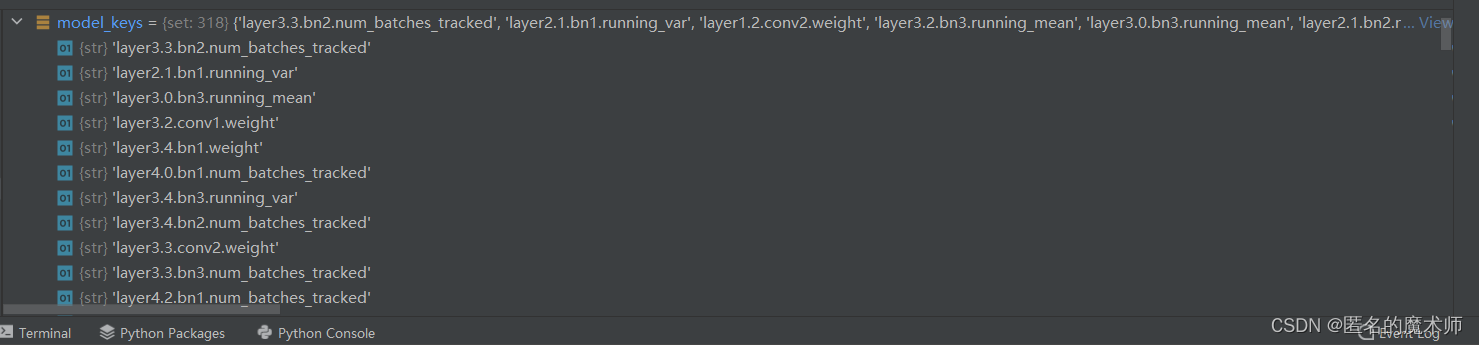
(3) def check_keys
ckpt_keys
model_keys
used_pretrainde_keys
unused_pretrained_keys

missing_keys (first)
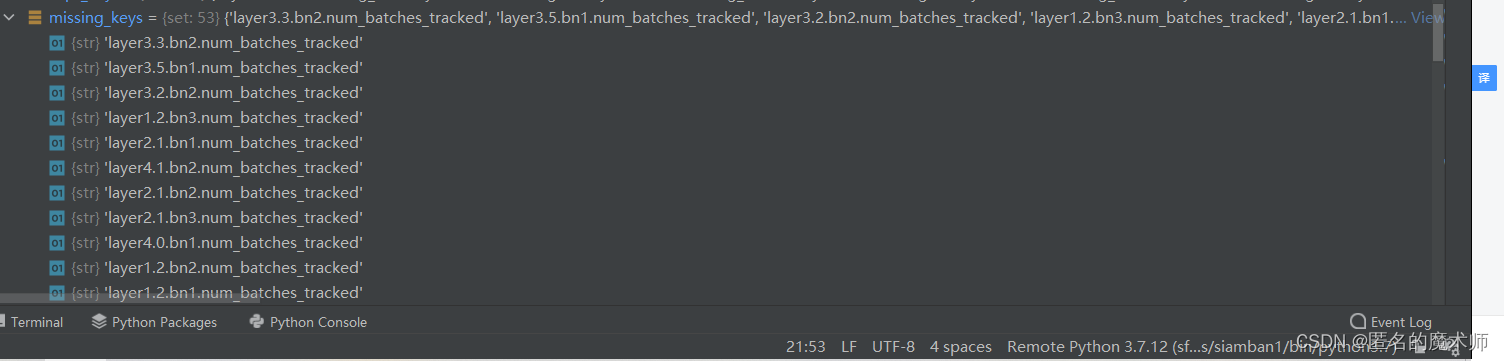
missing_keys (secend)

3. dataset.py
(1) class BANDataset(Dataset)
cfg.DATASET
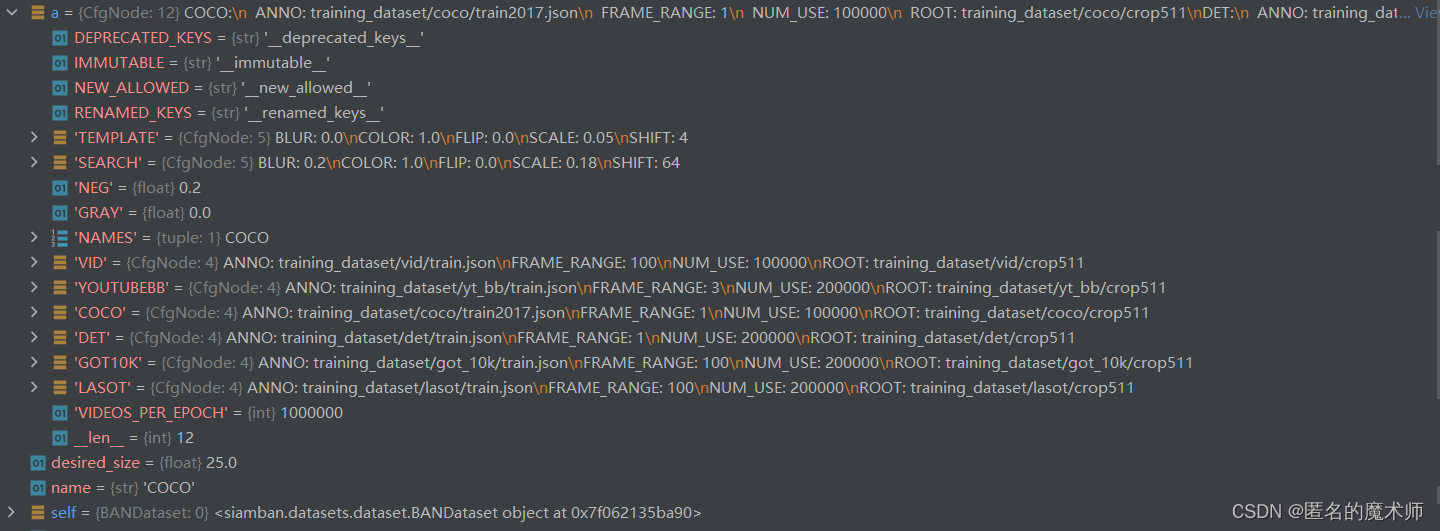
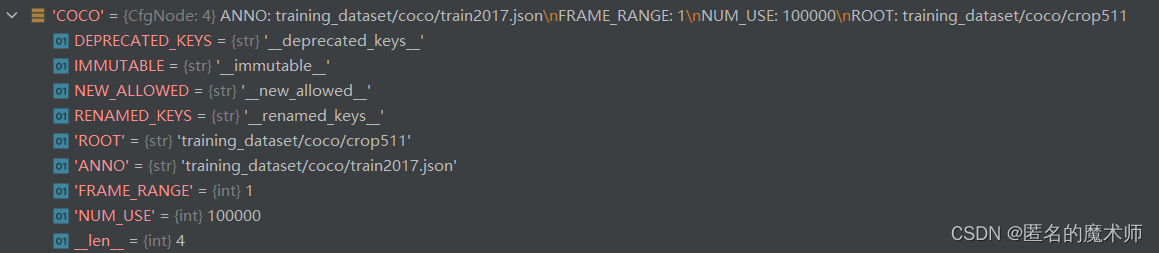
《config文件中的设置》
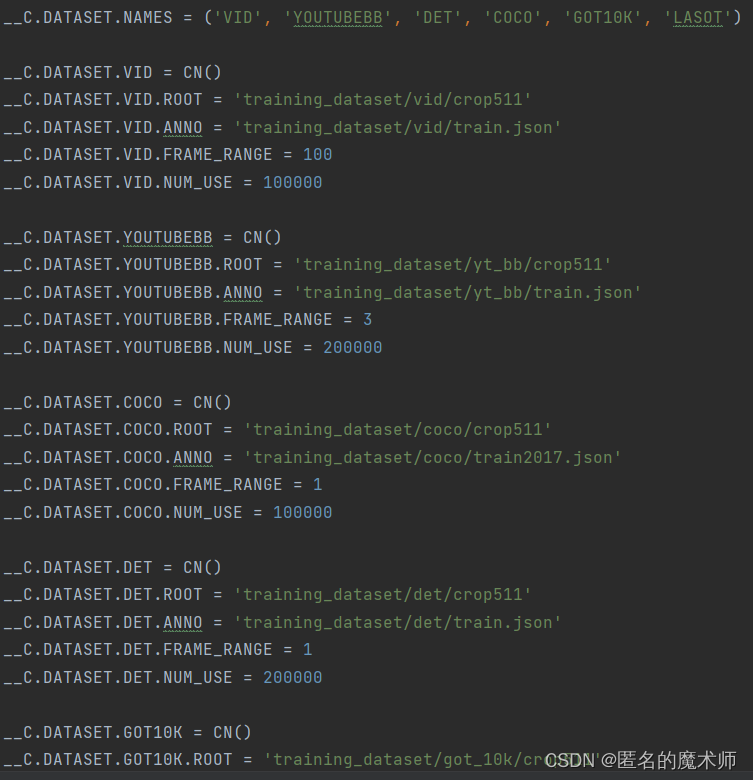
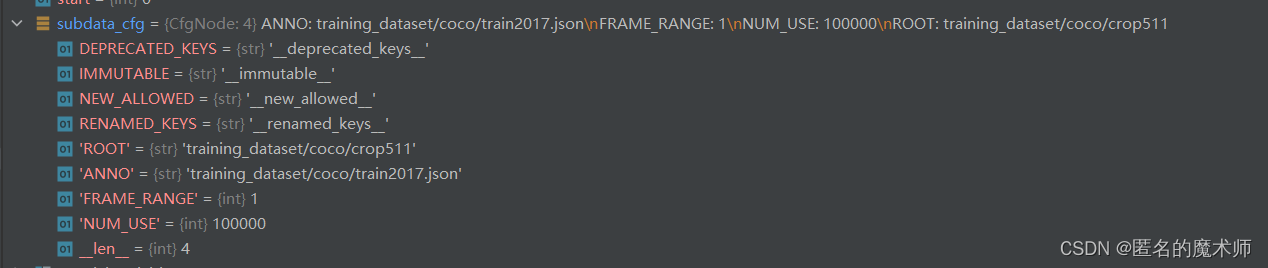
subdata_cfg
self.all_dataset

self.pick

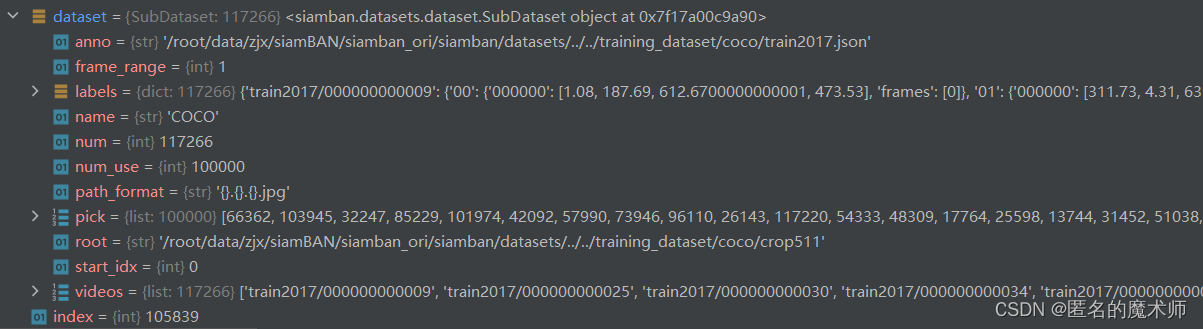
dataset
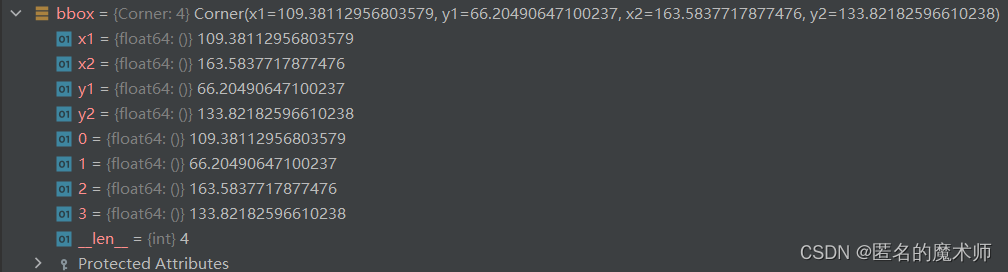
bbox
def shuffle
p, pick
《第一次循环》
《循环结束后》
(2)class SubDataset(object)
f
meta_data (太长了,没截图完) first
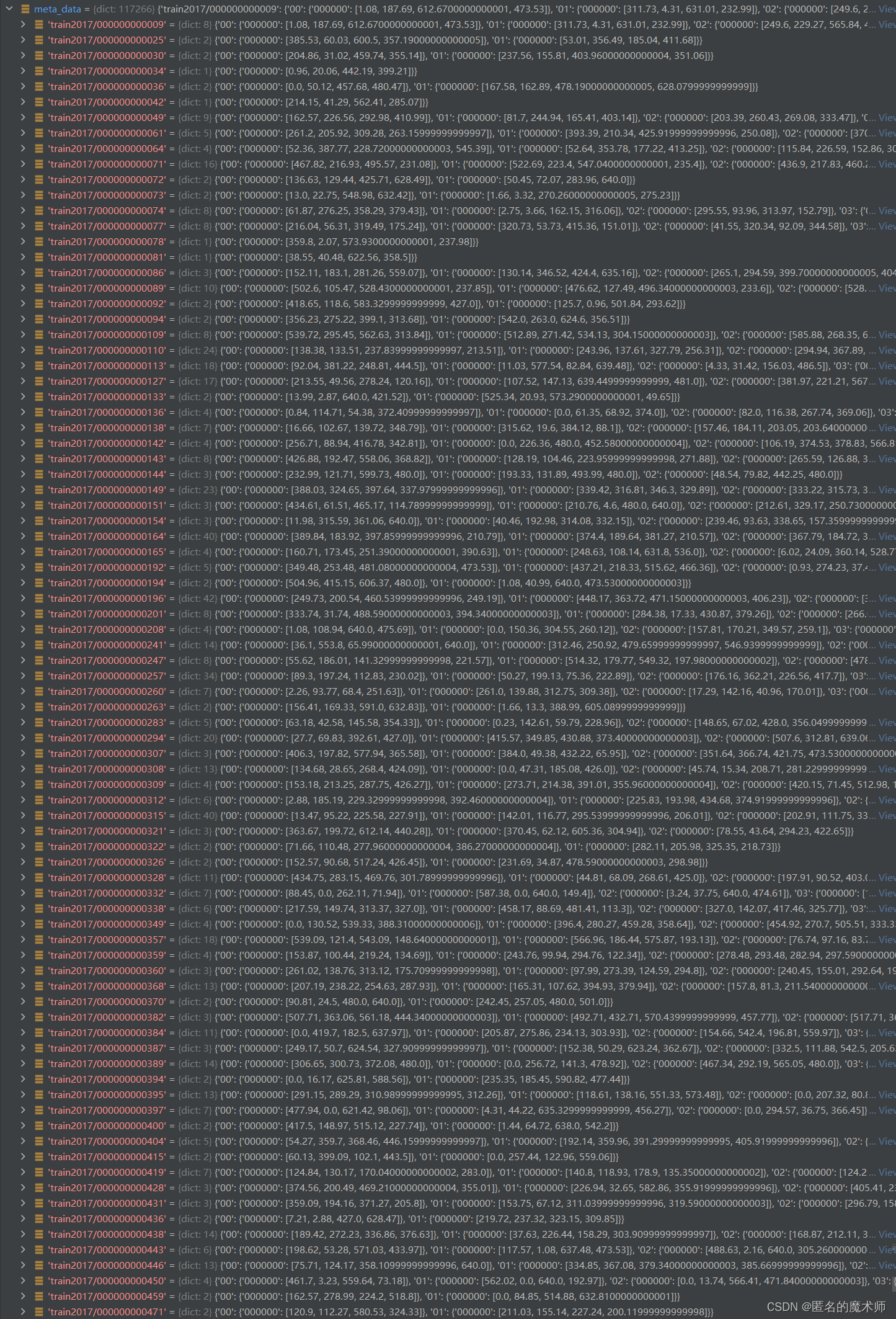
meta_data (second,经过_filter_zero之后的)
self.labels
self.videos

template

search

template_box
search_box
(3)def _filter_zero-->class SubDataset(object)
tracks

(4) def shuffle-->class SubDataset(object)
list
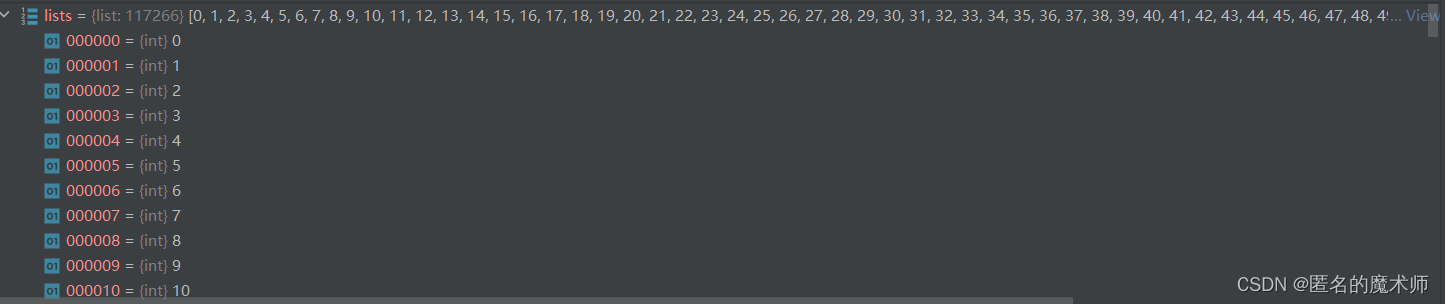
(5) def _find_dataset--> class BANDataset(Dataset)
dataset
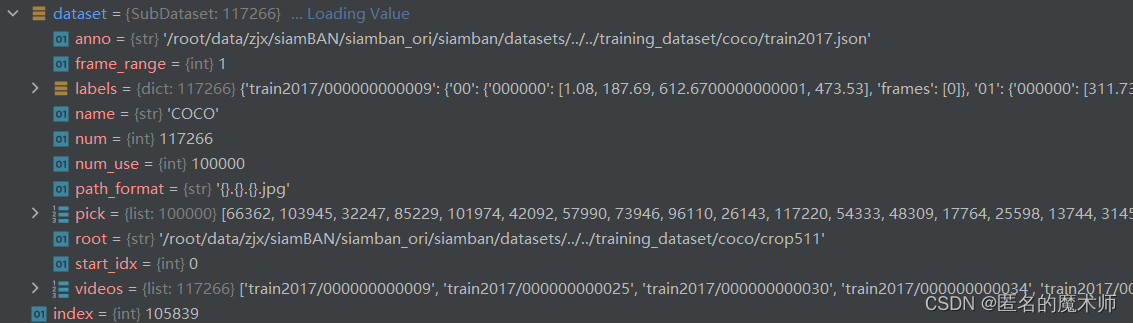
(6) def get_positive_pair-->class SubDataset(object)
self
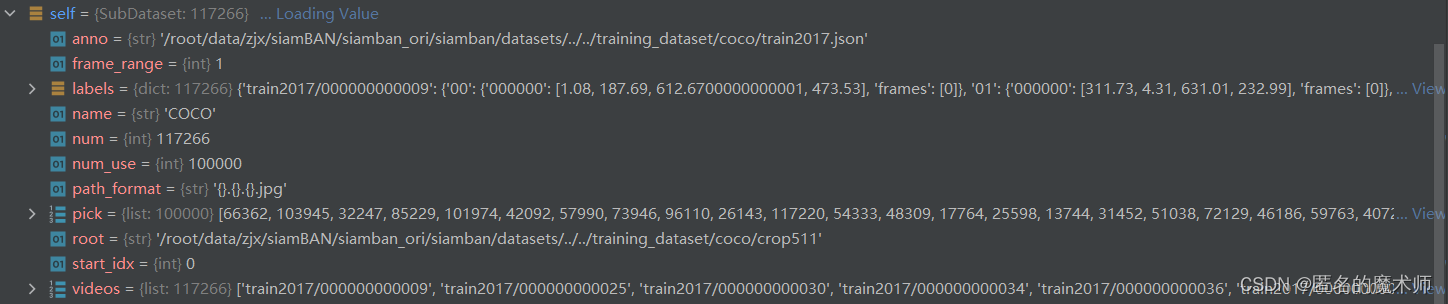
video
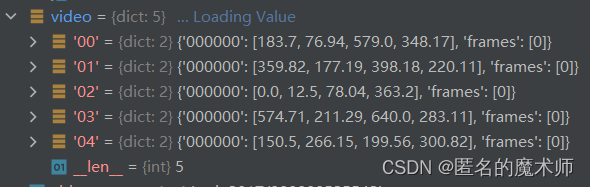
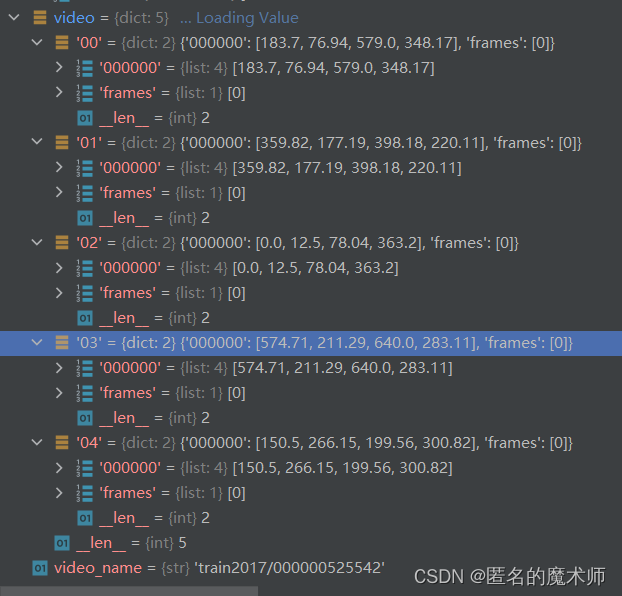
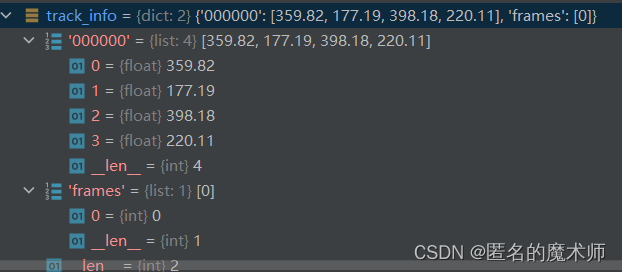
track_info
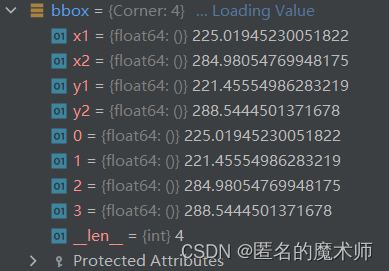
(7) _get_bbox--> class BANDataset(Dataset)
bbox
4. lr_scheduler.py
(1) def _build_warm_up_scheduler
sc1

sc2

(2) class WarmUPScheduler
warmup

normal

self.lr_spaces

5.distributed.py
(1) class DistModule
self.module

(2) broadcast_params
p

6. model_builder.py
data

template

search
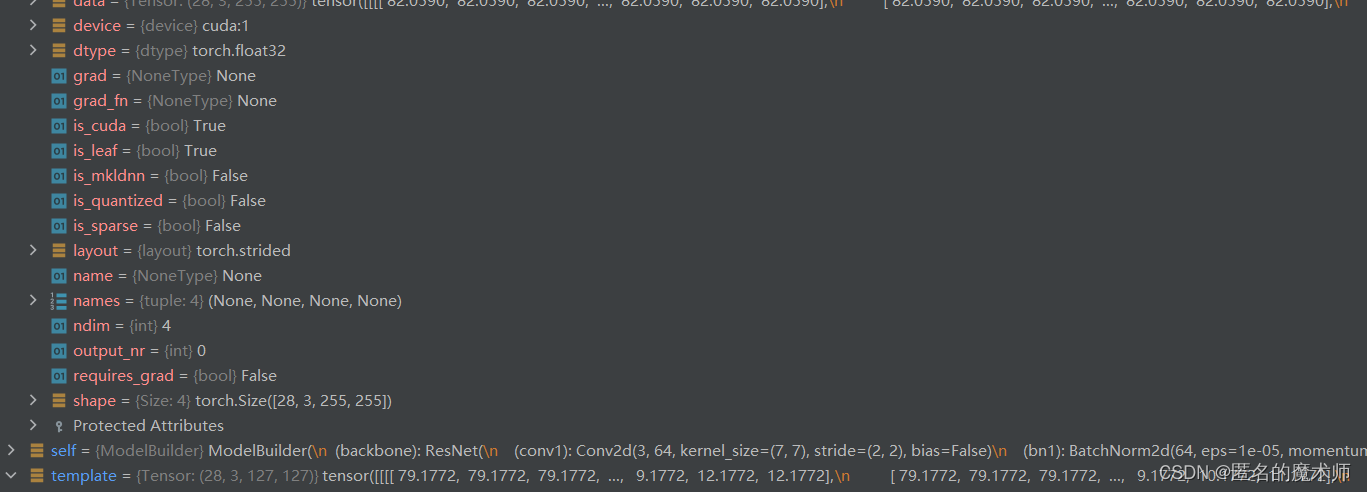
label_cls
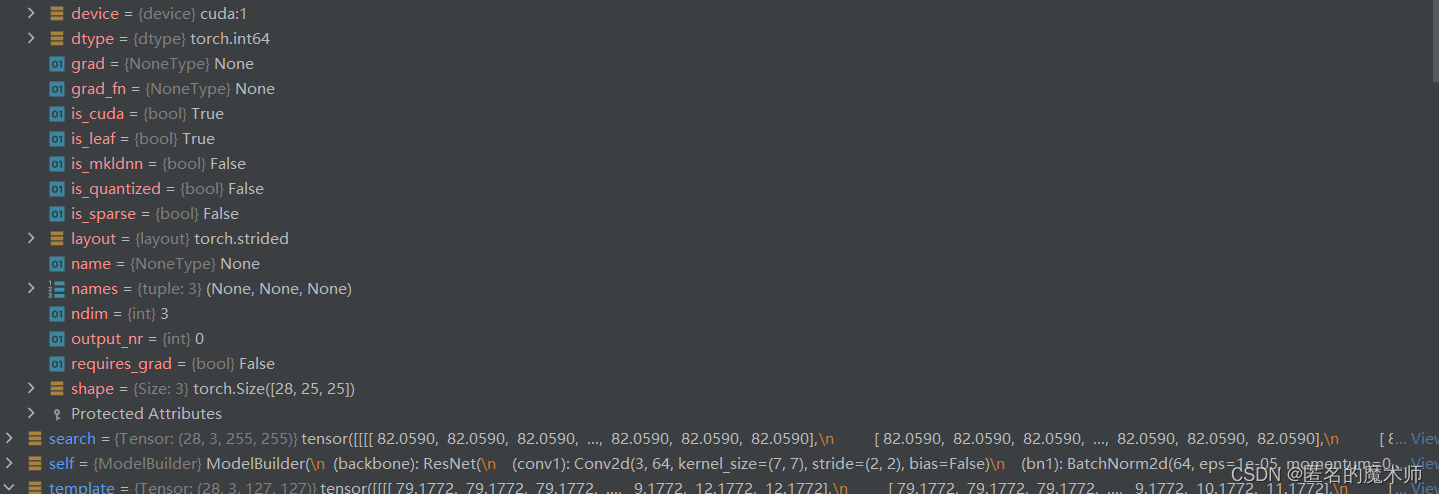
label_loc
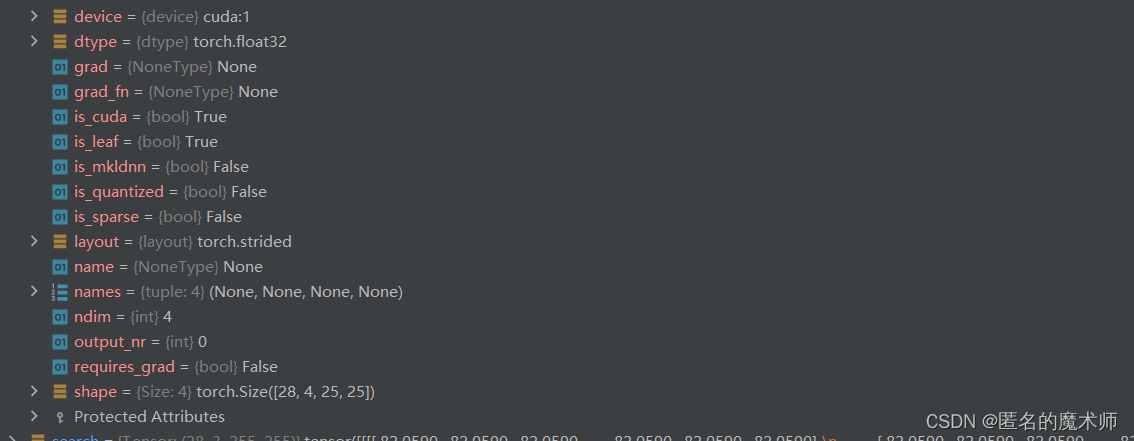
zf

xf

zf (neck)

xf (neck)

cls
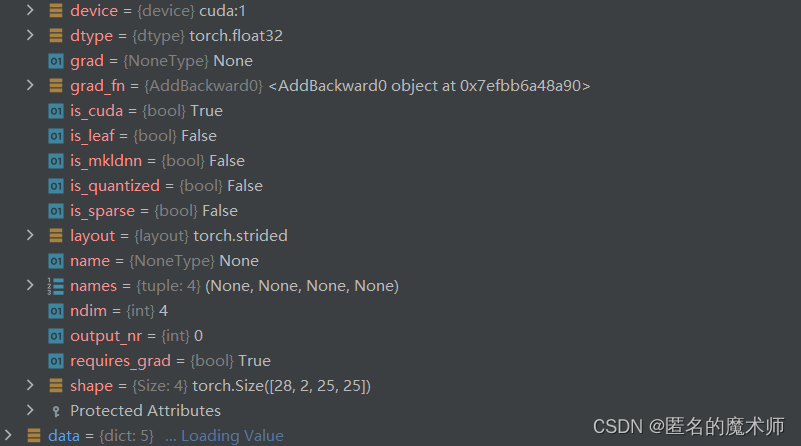
loc
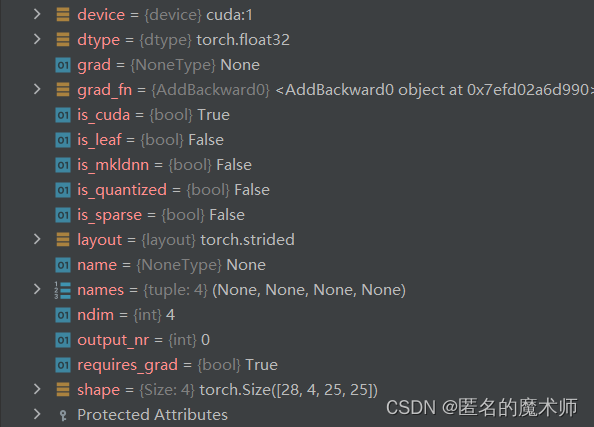
cls (log_softmax)
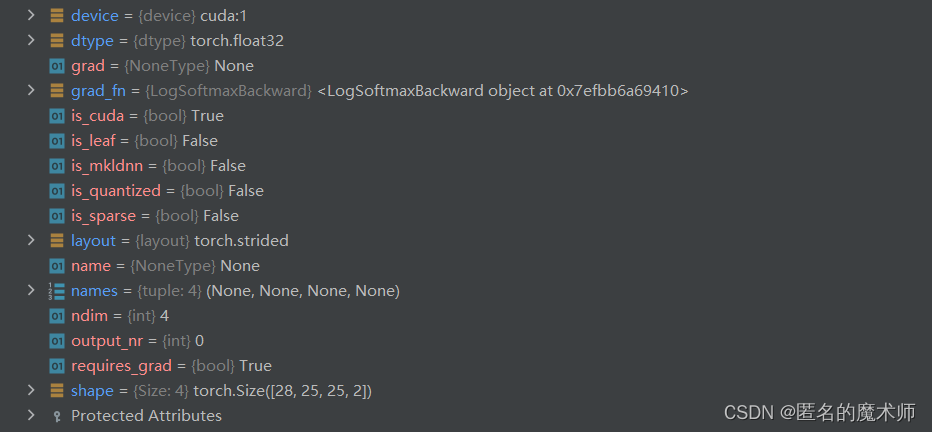
cls_loss
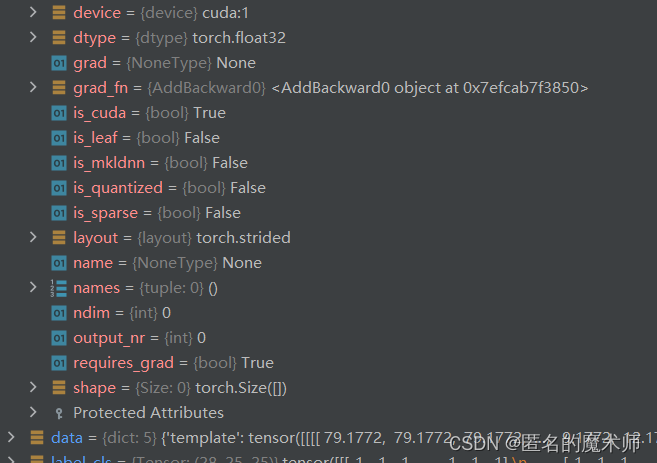
loc_loss
7. augmentation.py
(1) def __call__
corp_bbox
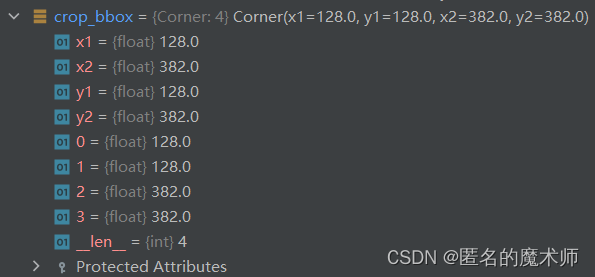
bbox
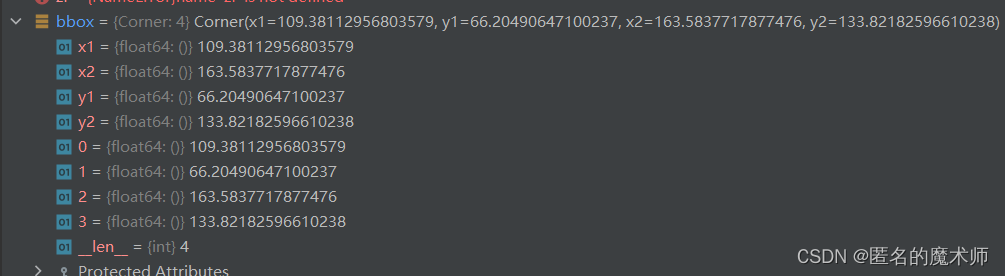
(2) _shift_scale_aug
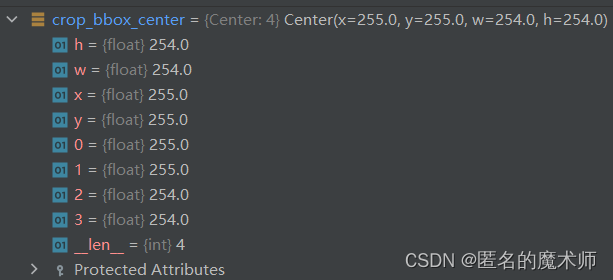
crop_bbox_center (first)
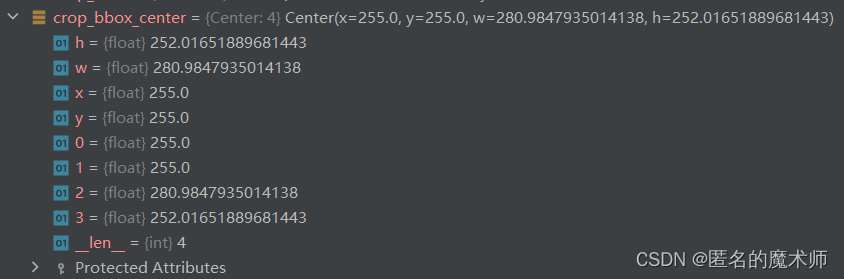
crop_bbox_center (second)
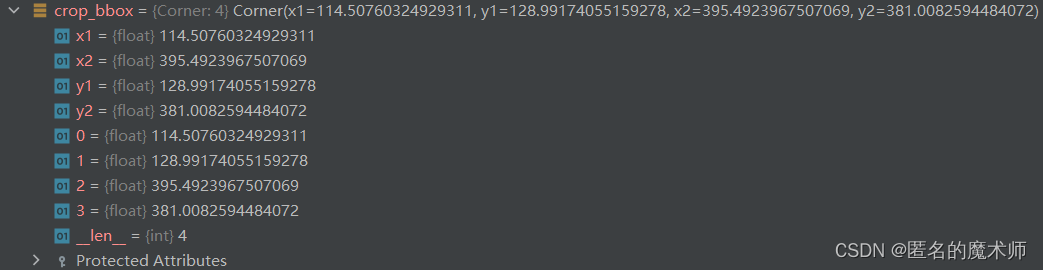
crop_bbox
8.point_target.py
self.point

points
[0]
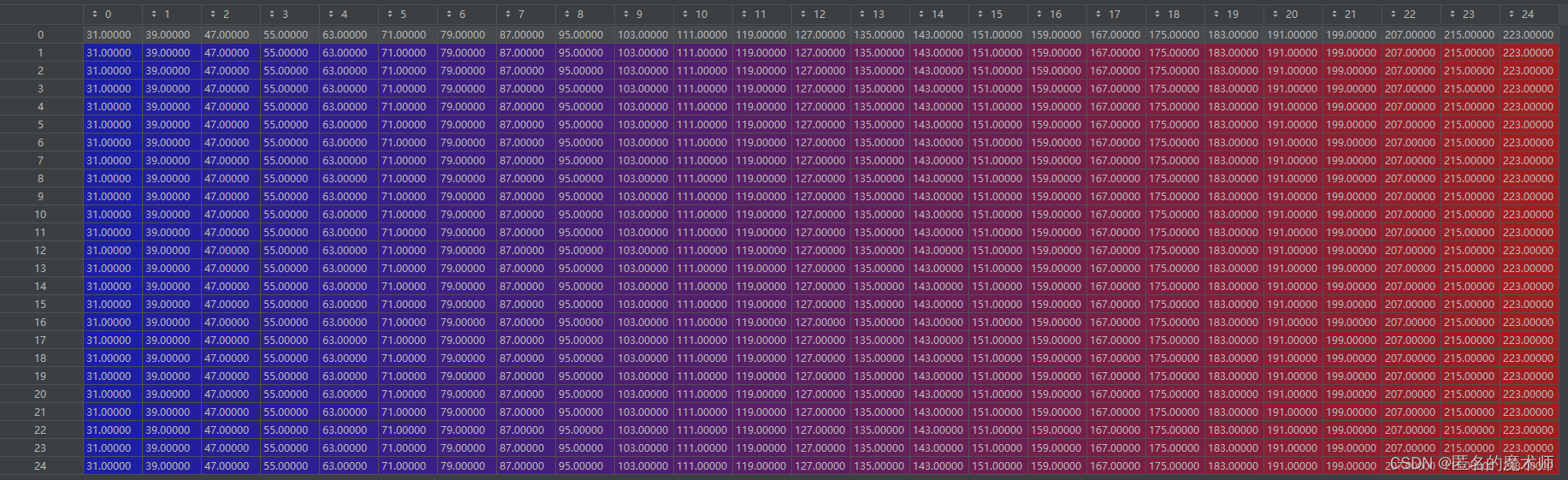
[1]
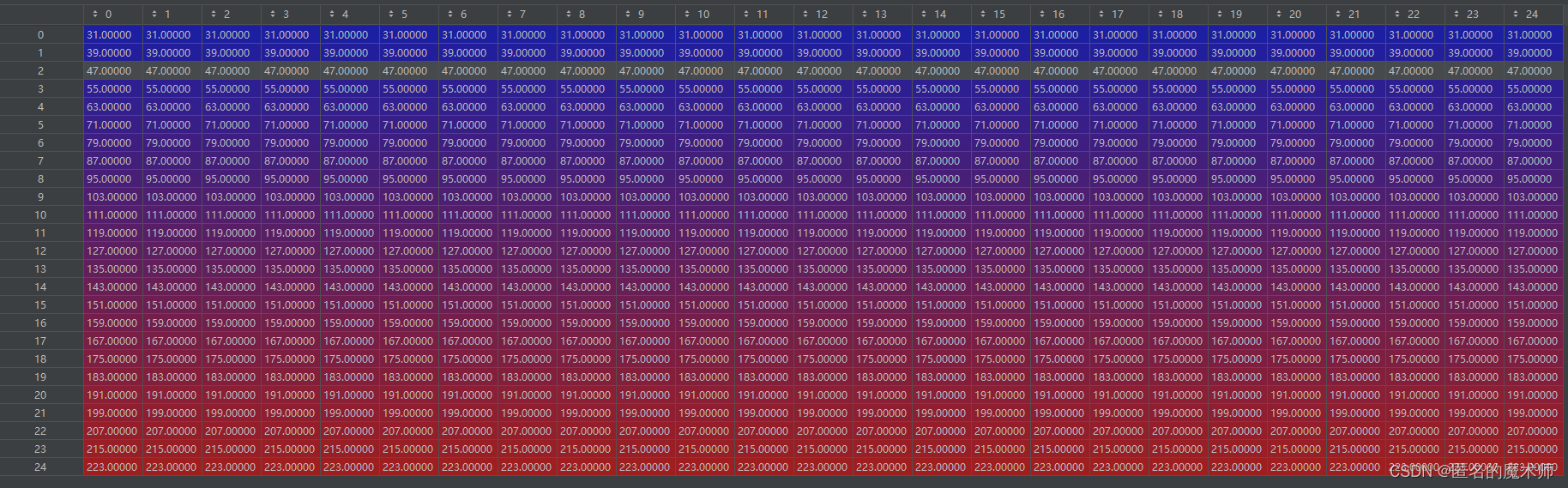
cls (first)
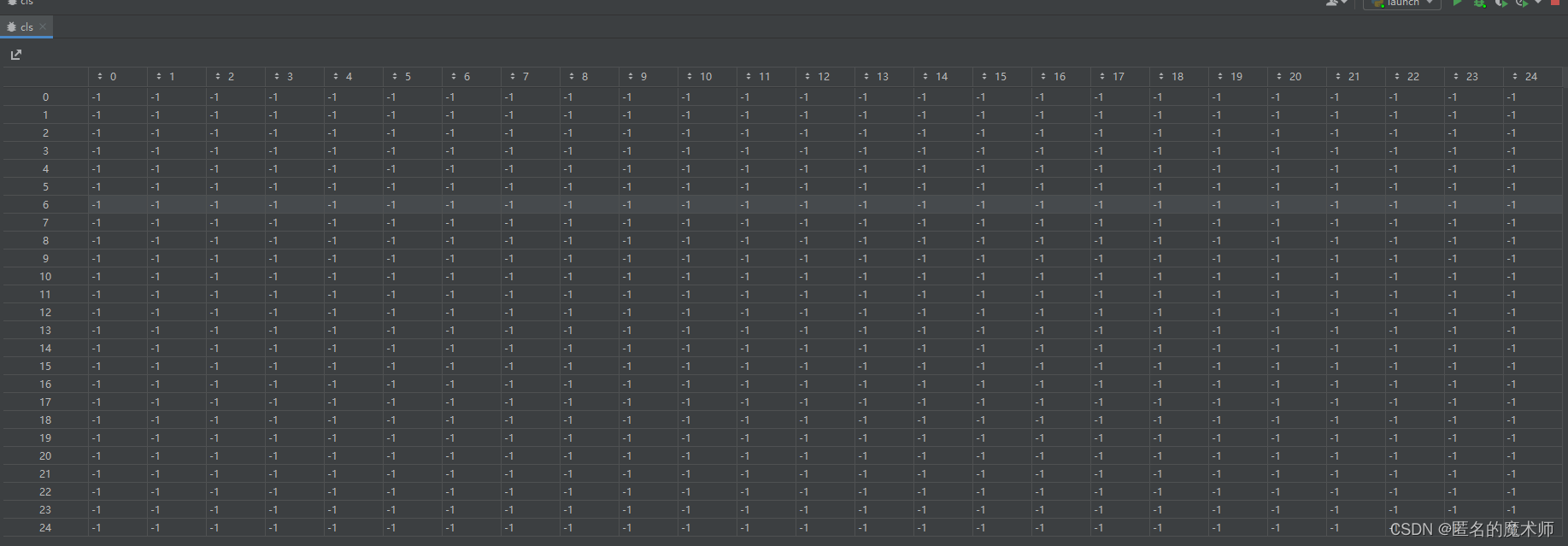
delta (first)

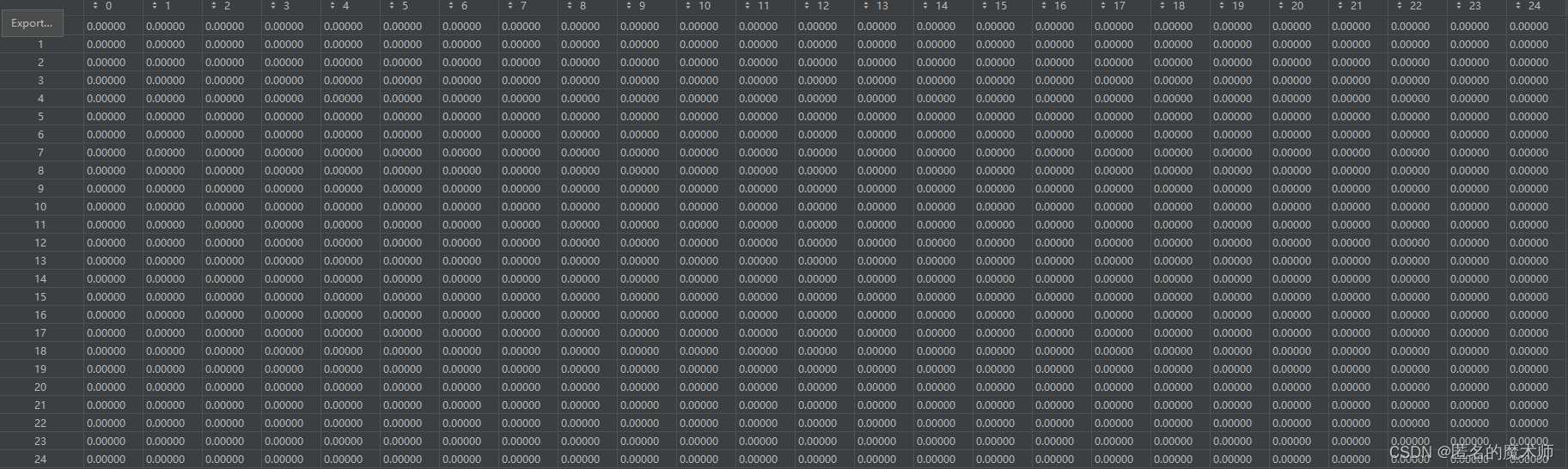
delta (second)
[0]
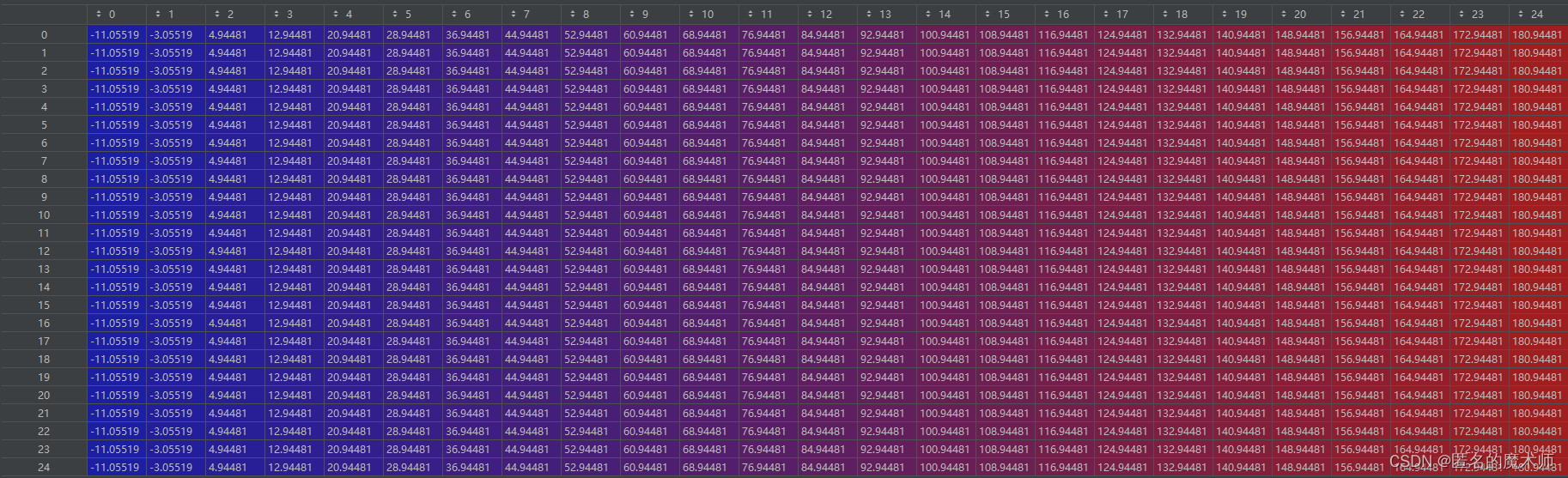
[1]
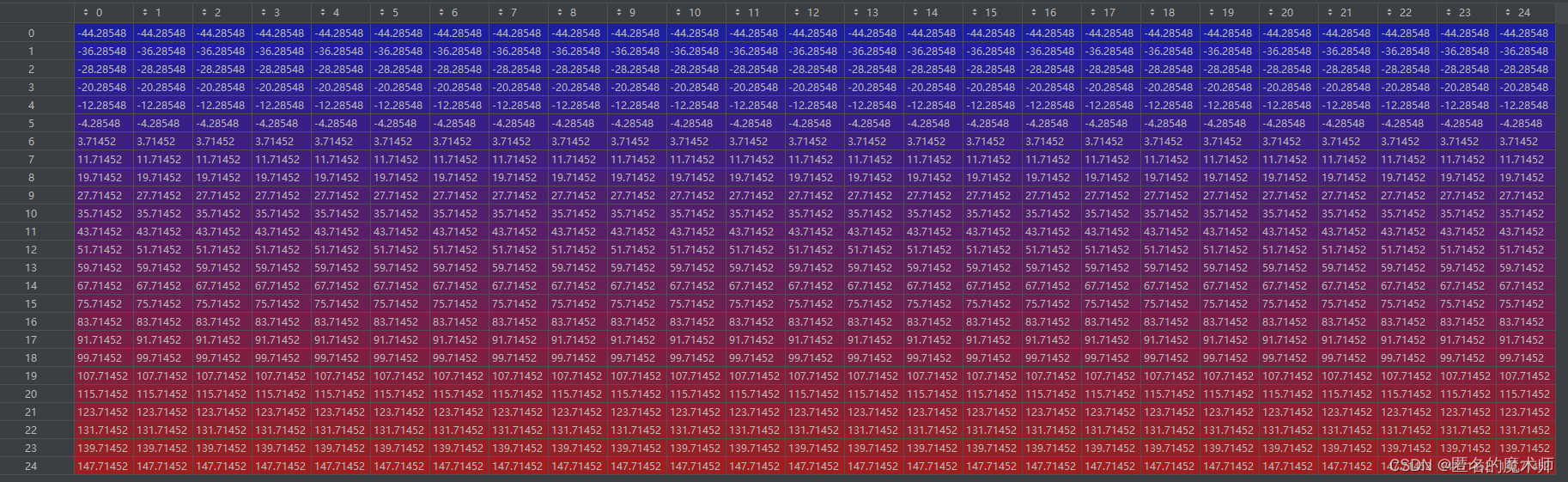
[2]
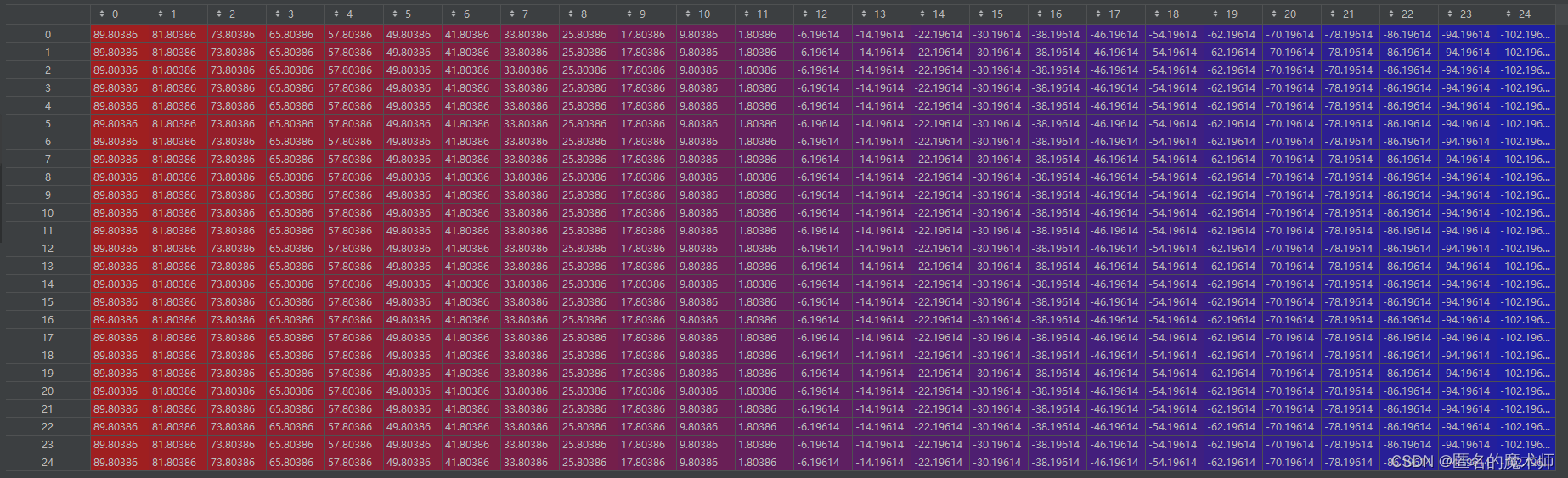
[3]
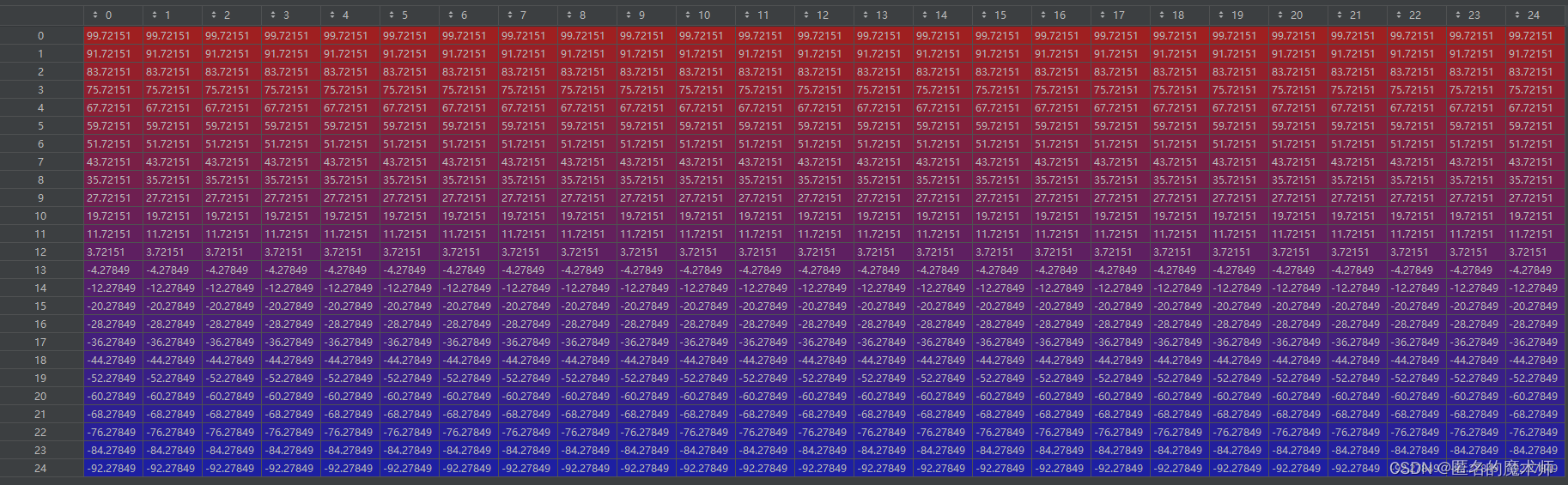
pos

neg

position

cls(second)
二、一些关键部分的入口以及代码
1. 搭建主干网络以及构造模型
train.py------- 267
model = ModelBuilder().cuda().train()2. 加载Rsnet预训练骨干的参数
train.py-----271
if cfg.BACKBONE.PRETRAINED: # Truecur_path = os.path.dirname(os.path.realpath(__file__)) # cur_path: '/root/data/zjx/siamBAN/siamban_ori/tools'backbone_path = os.path.join(cur_path, '../', cfg.BACKBONE.PRETRAINED) # backbone_path:'/root/data/zjx/siamBAN/siamban_ori/tools/../pretrained_models/resnet50.model'load_pretrain(model.backbone, backbone_path)3. 建立dataset loader
train.py----283
train_loader = build_data_loader()4. 导入数据集的入口
dataset.py -----160
for name in cfg.DATASET.NAMES: # name: 'COCO' 这个就是拿出数据集的地方更精确一点,裁剪后的数据集路径为
dataset.py -----34
self.root = os.path.join(cur_path, '../../', root) # '/root/data/zjx/siamBAN/siamban_ori/siamban/datasets/../../training_dataset/coco/crop511'5. 训练时打印的出处
(1) 刚开始准备的阶段
“======================”
{'000000':[1.08,187.69,612.6700000000001,473.53]}
“======================”dataset.py-----73
for trk, frames in tracks.items(): # trk={str}'00' frames={dict:1}{'000000':[1.08,187.69,612.6700000000001,473.53]}print("===================")print(frames)print("===================")这些都是准备阶段,还没开始对数据集进行训练呢。
(2) 开头时打印的config内容
train.py-----264
logger.info("config \n{}".format(json.dumps(cfg, indent=4)))(3) Epoch 啥的
train.py-----241
for cc, (k, v) in enumerate(batch_info.items()): # cc:索引, (k,v)与之前的一样if cc % 2 == 0:info += ("\t{:s}\t").format(getattr(average_meter, k)) # ’Epoch:[1][20/17857] lr:0.0010000\n\tbatch_time:1.308527(1.368259)\t‘else:info += ("{:s}\n").format(getattr(average_meter, k)) # ’Epoch:[1][20/17857] lr:0.0010000\n\tbatch_time:1.308527(1.368259)\tdata_time:0.488958(0.661270)\n‘logger.info(info)(4) progress 啥的

log_helper.py-----102
logger.info('Progress: %d / %d [%d%%], Speed: %.3f s/iter, ETA %d:%02d:%02d (D:H:M)\n' %(i, n, i / n * 100,average_time,remaining_day, remaining_hour, remaining_min))(5) 模型的模块结构
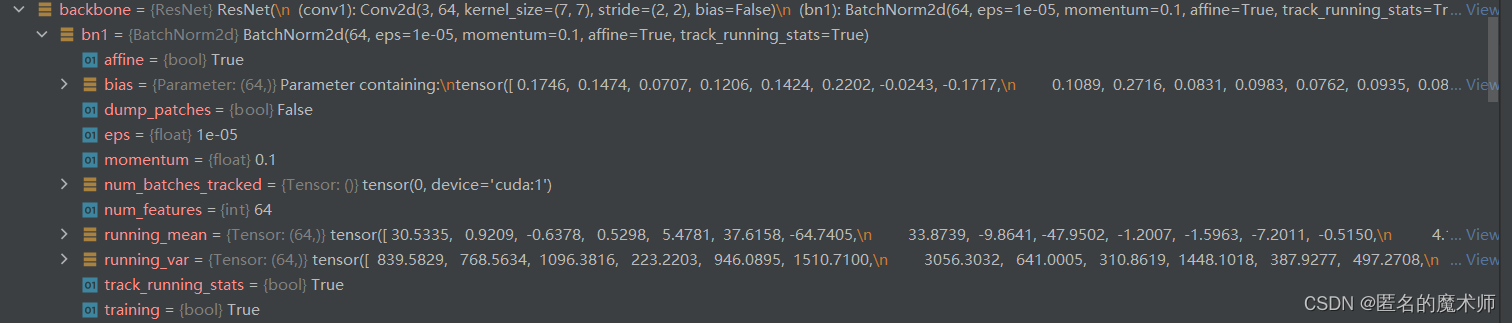
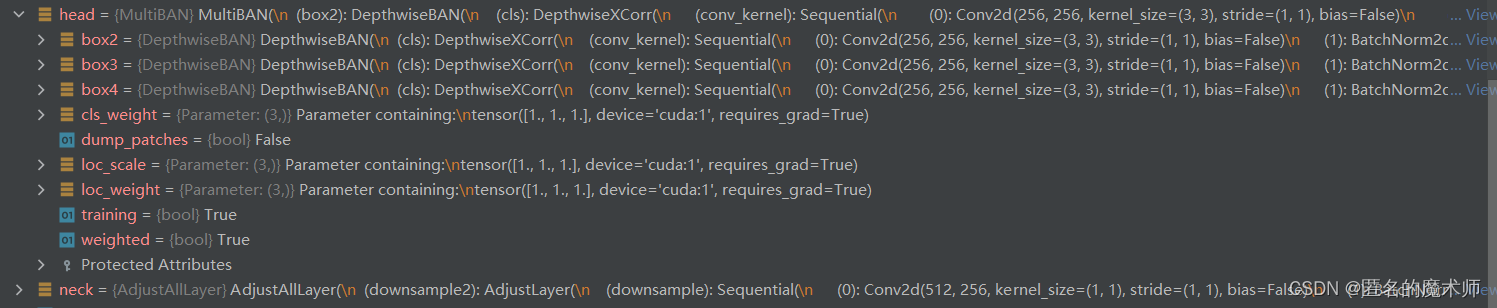
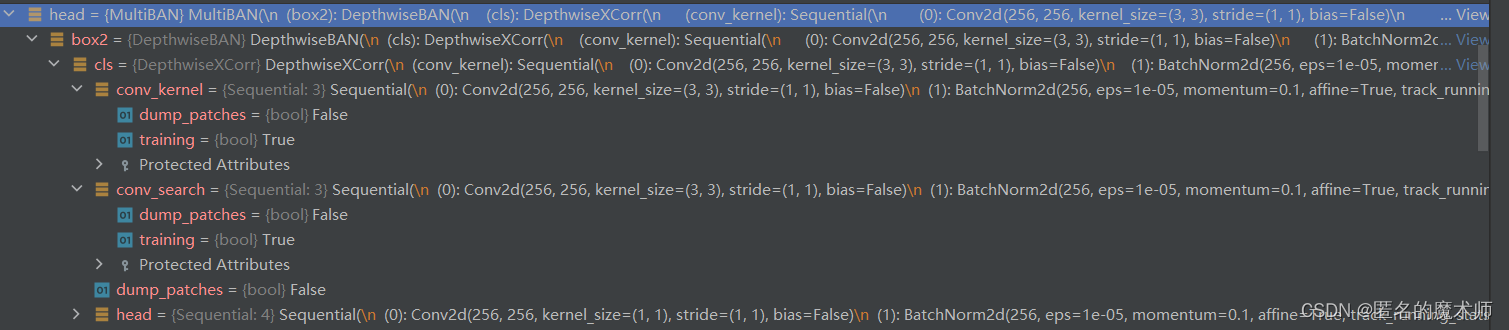
train.py-----166
logger.info("model\n{}".format(describe(model.module)))6. 数据送入模型的入口
train.py-----202
outputs = model(data)7. 分类标签和回归标签的创建
dataset.py-----272
cls, delta = self.point_target(bbox, cfg.TRAIN.OUTPUT_SIZE, neg)8. 损失函数的使用
module_builder.py-----93
cls = self.log_softmax(cls) # 先取softmax然后再log,值都为负数, Tensor:(28,25,25,2) <c>
cls_loss = select_cross_entropy_loss(cls, label_cls) # <c> 一个数 tensor(0.7612)# loc loss with iou loss
loc_loss = select_iou_loss(loc, label_loc, label_cls)9. 原输入图片为(511,511,3),resize到输入网络的尺寸的入口
dataset.py----261
template, _ = self.template_aug(template_image,template_box,cfg.TRAIN.EXEMPLAR_SIZE,gray=gray) # ndarry:(127,127,3)search, bbox = self.search_aug(search_image,search_box,cfg.TRAIN.SEARCH_SIZE,gray=gray)augmentation.py-----126
image, bbox = self._shift_scale_aug(image, bbox, crop_bbox, size)10.正样本随机选16个,负样本随机选48个入口
point_target.py---23
def select(position, keep_num=16): # keep_num 16 或 48num = position[0].shape[0] # 举例 569if num <= keep_num:return position, numslt = np.arange(num) # 举例 ndarray:(569:) [0~568]np.random.shuffle(slt) # 打乱slt = slt[:keep_num] # ndarray:(48,)return tuple(p[slt] for p in position), keep_num11. 输入shape 通道转成对应的3通道 (3,255,255)以及(3,127,127)入口
dataset.py----273
template = template.transpose((2, 0, 1)).astype(np.float32) # ndarray:(3,127,127)
search = search.transpose((2, 0, 1)).astype(np.float32) 12 日志文件创建入口
train.py-----259
if cfg.TRAIN.LOG_DIR: # Trueadd_file_handler('global',os.path.join(cfg.TRAIN.LOG_DIR, 'logs.txt'),logging.INFO)13. 更改数据集导入路径啥的设置
config.py-----129
__C.DATASET.NAMES = ('VID', 'YOUTUBEBB', 'DET', 'COCO', 'GOT10K', 'LASOT')__C.DATASET.VID = CN()
__C.DATASET.VID.ROOT = 'training_dataset/vid/crop511'
__C.DATASET.VID.ANNO = 'training_dataset/vid/train.json'
__C.DATASET.VID.FRAME_RANGE = 100
__C.DATASET.VID.NUM_USE = 100000__C.DATASET.YOUTUBEBB = CN()
__C.DATASET.YOUTUBEBB.ROOT = 'training_dataset/yt_bb/crop511'
__C.DATASET.YOUTUBEBB.ANNO = 'training_dataset/yt_bb/train.json'
__C.DATASET.YOUTUBEBB.FRAME_RANGE = 3
__C.DATASET.YOUTUBEBB.NUM_USE = 200000__C.DATASET.COCO = CN()
__C.DATASET.COCO.ROOT = 'training_dataset/coco/crop511'
__C.DATASET.COCO.ANNO = 'training_dataset/coco/train2017.json'
__C.DATASET.COCO.FRAME_RANGE = 1
__C.DATASET.COCO.NUM_USE = 100000__C.DATASET.DET = CN()
__C.DATASET.DET.ROOT = 'training_dataset/det/crop511'
__C.DATASET.DET.ANNO = 'training_dataset/det/train.json'
__C.DATASET.DET.FRAME_RANGE = 1
__C.DATASET.DET.NUM_USE = 200000__C.DATASET.GOT10K = CN()
__C.DATASET.GOT10K.ROOT = 'training_dataset/got_10k/crop511'
__C.DATASET.GOT10K.ANNO = 'training_dataset/got_10k/train.json'
__C.DATASET.GOT10K.FRAME_RANGE = 100
__C.DATASET.GOT10K.NUM_USE = 200000__C.DATASET.LASOT = CN()
__C.DATASET.LASOT.ROOT = 'training_dataset/lasot/crop511'
__C.DATASET.LASOT.ANNO = 'training_dataset/lasot/train.json'
__C.DATASET.LASOT.FRAME_RANGE = 100
__C.DATASET.LASOT.NUM_USE = 200000__C.DATASET.VIDEOS_PER_EPOCH = 100000014. 截取训练数据的入口
训练数据所用的图片(这里对应处理前的单张图片,处理后成为一个文件夹,依据所包含目标数量多少下面可能包含多张图片)的数量为设置的,self.use_num,若大于这个数则随机截取,小于这个则随机会重复选取直至满足
dataset.py-----66 、98
self.pick = self.shuffle() def shuffle(self):lists = list(range(self.start_idx, self.start_idx + self.num)) # {list:117266} 从0到117265,并且转成列表 <c>pick = []while len(pick) < self.num_use: # 小于 使用的数量则循环 。若self.num_use小于lists 的长度则一次循环结束,截取这么长;若大于,则循环执行直至满足np.random.shuffle(lists) # 随机打乱列表中的 索引顺序pick += listsreturn pick[:self.num_use]15 .最终训练数据的每轮epoch的大小
可以一次性使用多个训练数据集,因为每轮epoch的总batch训练大小为20000000个,个数不够循环来凑。
dataset.py-----198
def shuffle(self):pick = []m = 0while m < self.num: # 当m 小于时一直执行这个循环p = []for sub_dataset in self.all_dataset:sub_p = sub_dataset.pick # {list:100000}p += sub_p # 如果是单个数据集的话,p每次都是那些np.random.shuffle(p)pick += pm = len(pick)logger.info("shuffle done!")logger.info("dataset length {}".format(self.num))return pick[:self.num]16 . 保存模型参数
train.py -----172
if get_rank() == 0: # 只在进程0上保存就行了,避免重复,而且保存的参数为 model.moduletorch.save({'epoch': epoch,'state_dict': model.module.state_dict(),'optimizer': optimizer.state_dict()},cfg.TRAIN.SNAPSHOT_DIR+'/checkpoint_e%d.pth' % (epoch))三、 网络结构
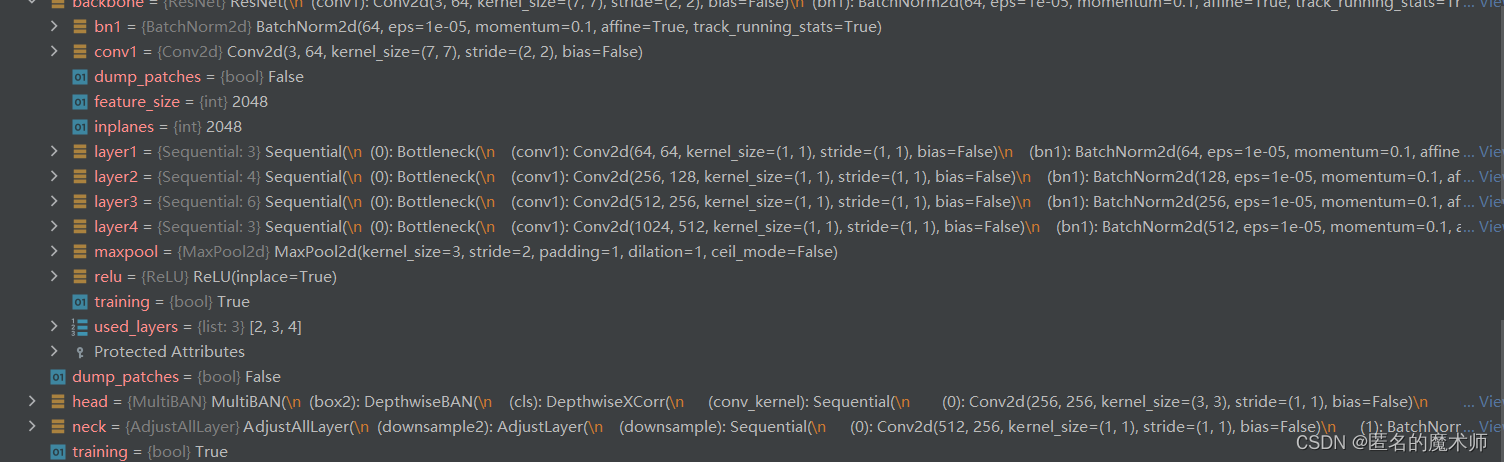
ModelBuilder((backbone): ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): Bottleneck((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): Bottleneck((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(4): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(5): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer4): Sequential((0): Bottleneck((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))))(neck): AdjustAllLayer((downsample2): AdjustLayer((downsample): Sequential((0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(downsample3): AdjustLayer((downsample): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(downsample4): AdjustLayer((downsample): Sequential((0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(head): MultiBAN((box2): DepthwiseBAN((cls): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))))(loc): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 4, kernel_size=(1, 1), stride=(1, 1)))))(box3): DepthwiseBAN((cls): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))))(loc): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 4, kernel_size=(1, 1), stride=(1, 1)))))(box4): DepthwiseBAN((cls): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))))(loc): DepthwiseXCorr((conv_kernel): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(conv_search): Sequential((0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(head): Sequential((0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 4, kernel_size=(1, 1), stride=(1, 1))))))
)这篇关于SiamBAN 训练过程debug记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







