本文主要是介绍笔趣阁获取文本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
前言
一、目标步骤
二、详细介绍
1.获取小说文本
2.获取文本的txt版本
3.将txt文本合并在一起
三、总结
前言
最近又想听小说了,但是好多小说听不见,但是edge自带阅读插件,就想着用其来读小说。
但是会有以下问题:
- 小说中会有其他内容,影响听书体验,如下图1。
- 听完一章小说后,小说不能自动跳转至下一页。

图1
一、目标步骤
我们的目标有三个:
- 从网页上获取小说文本。
- 从网页上获取文本的txt版本。
- 将txt文本合并在一起。
二、详细介绍
1.获取小说文本
代码如下:
//获取页面中小说的章节标题
var title=document.getElementsByClassName("bookname").item(0).innerText;
//获取文本中包含小说文本的p标签
var c=document.getElementById("content").getElementsByTagName("p");
var content="";
var i;
//将单独的p标签合并为一个字符串文本。
for (i in c){
if(c[i].innerText==undefined || c[i].innerText.indexOf("App")>=0 || c[i].innerText.indexOf("本章完")>=0){
continue;
}
content+=c[i].innerText;
}
var result=`<h1>${title}</h1>\n\t\t<p>${content}</p>\n\t\t`;
console.log(result);
2.获取文本的txt版本
代码如下:
//创建一个<a>元素
var Usea=document.createElement("a");
//创建一个文字节点
var textNode=document.createTextNode("下载");
//将文字节点添加到<a>元素
Usea.appendChild(textNode);
//创建File类对象
var myfile=new File([result],Date.now()+title,{
type: "text/plain",
});
Usea.download=Date.now()+title+".txt";
//创建一个链接,方便后面调用a.click()触发download属性
Usea.href=URL.createObjectURL(myfile);
//调用a.click()触发download属性
Usea.click();
全部代码如下:【需要使用tampermonkey插件,将js自动触发】将代码放入油猴插件中。
// ==UserScript==
// @name 笔趣阁获取文本
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://www.beqege.cc/1076/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=beqege.cc
// @grant none
// ==/UserScript==
//上面的match后的网址根据需求填写****(function() {'use strict';console.log("开始了");var timeNumber=0window.TextGain=function(){var title=document.getElementsByClassName("bookname").item(0).innerText;var c=document.getElementById("content").getElementsByTagName("p");var content="";var i;for (i in c){if(c[i].innerText==undefined || c[i].innerText.indexOf("App")>=0 || c[i].innerText.indexOf("本章完")>=0){continue;}content+=c[i].innerText;}var result=`<h1>${title}</h1>\n\t\t<p>${content}</p>\n\t\t`;console.log(result);var Usea=document.createElement("a");var textNode=document.createTextNode("下载");Usea.appendChild(textNode);var myfile=new File([result],Date.now()+title,{type: "text/plain",});Usea.download=Date.now()+title+".txt";Usea.href=URL.createObjectURL(myfile);Usea.click();}window.nextPage=function(){document.getElementsByClassName("bottem1")[0].getElementsByTagName("a")[2].click();timeNumber+=1;}window.strat=function(){if(timeNumber==0){setTimeout("TextGain()",800);setTimeout("nextPage()",2000);}}setTimeout("strat()",600);
})();
使用步骤:
先打开笔趣阁的相关章节,如下图:
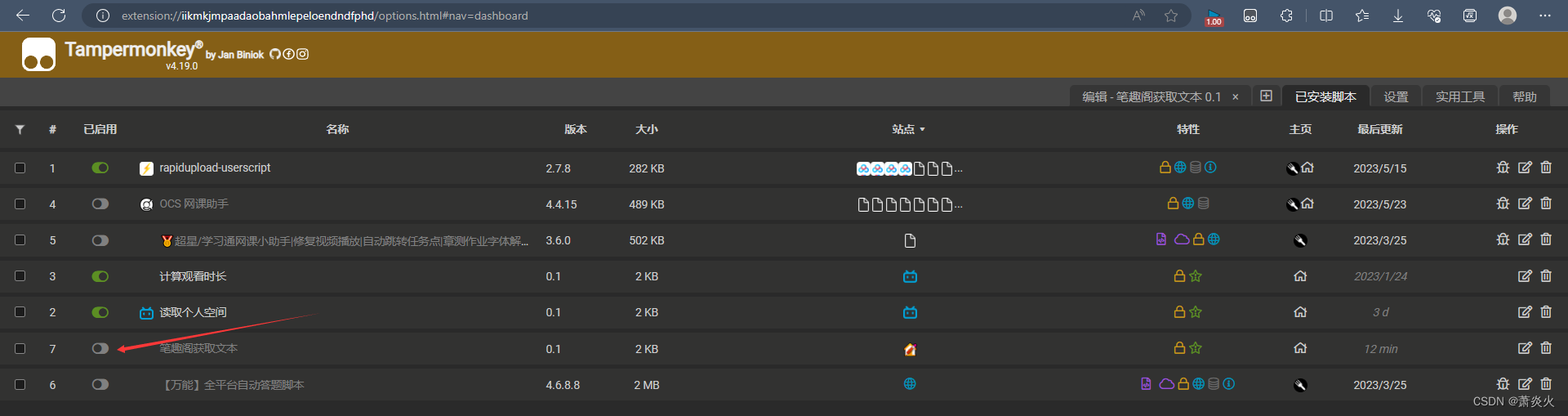
然后激活我们自制的脚本,如下图:
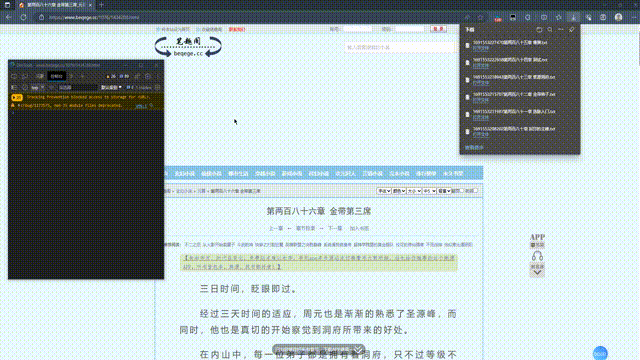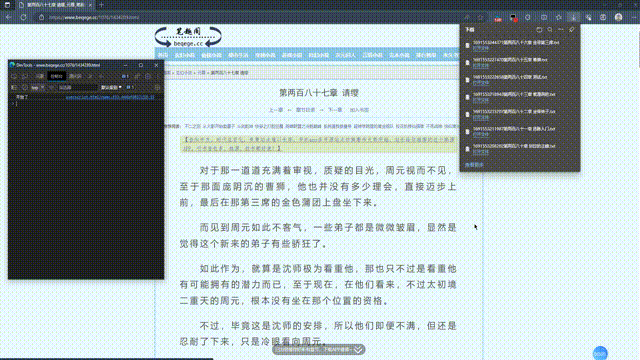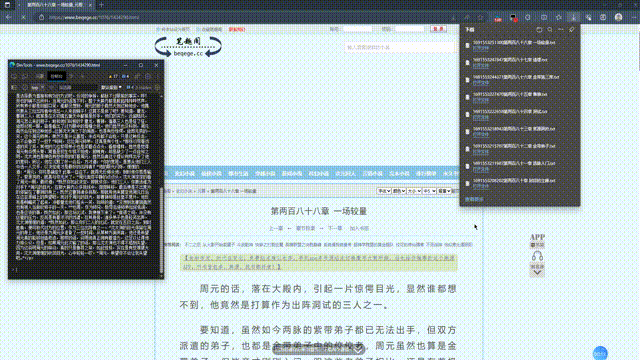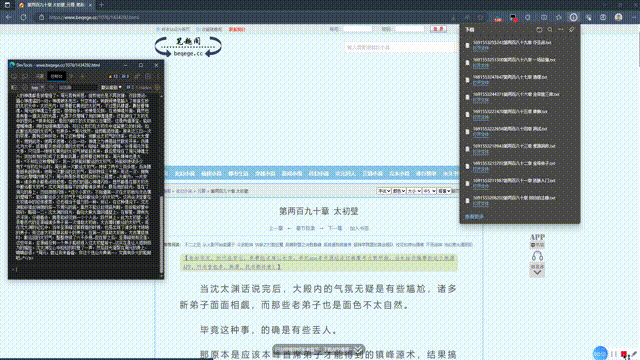
最后刷新笔趣阁网页即可触发下载脚本:
3.将txt文本合并在一起
这时我们下载文本的文件夹中的情况如下:
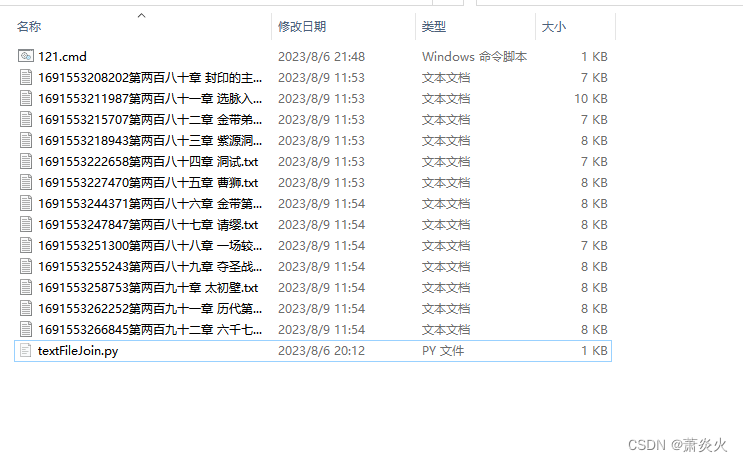
这时用到了python了。
代码如下:
import os
import pyautogui
import pyperclip
import keyboard
import time#获取当前文本的名字列表
listFileName=os.listdir(os.path.dirname(__file__))
listFileName.sort()
p=Nonedef autoWrite():
time.sleep(1)
for i in listFileName:
if(i.find("txt")!=-1):
p=open(file=r".\%s"%(i),mode="+r",encoding="utf-8")
pyperclip.copy("".join(p.readlines()))
pyautogui.hotkey("ctrl","v")
print("完成%s"%(i))
time.sleep(0.3)if __name__=="__main__":
keyboard.add_hotkey("alt+x",callback=autoWrite)
keyboard.wait("esc")
Now!将我们做的小说html打开:
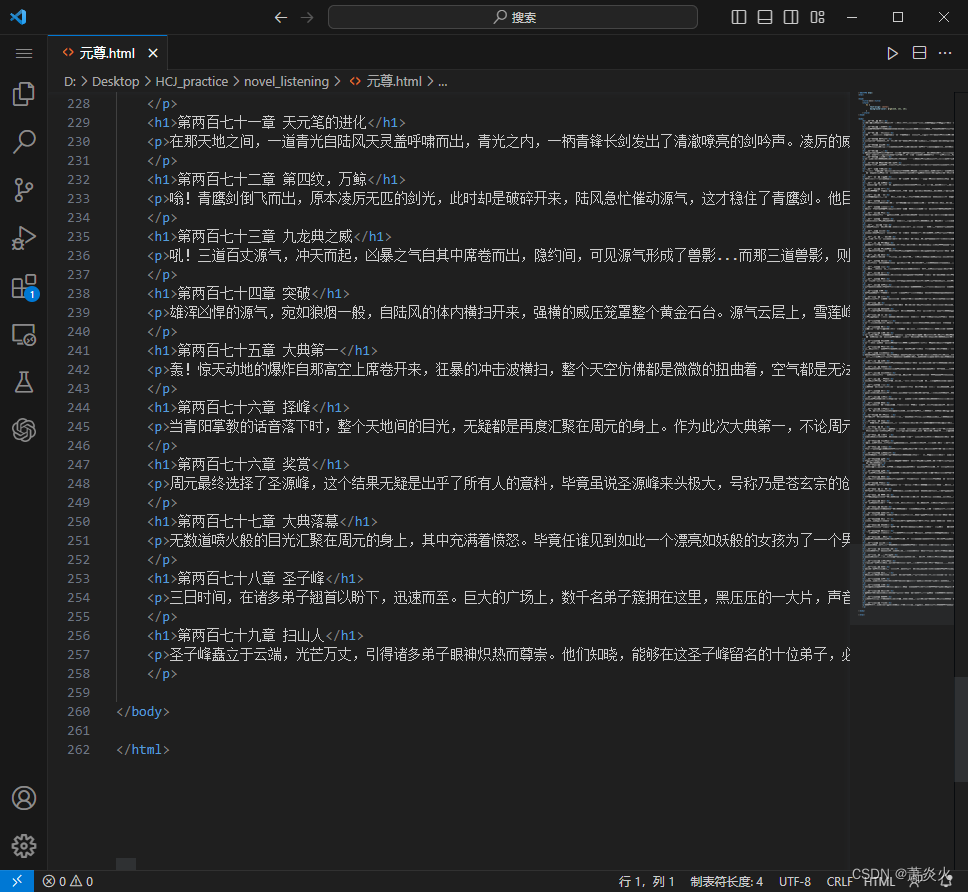
运行我们的py脚本,点击“alt+x”即可开始合并文件。
三、总结
最后,我们点击我们制作的html文件【用edge】,然后点击“ctrl+shift+u”即可激活阅读功能。
这篇关于笔趣阁获取文本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



