本文主要是介绍诺亚方舟实验室提出数值特征自动离散框架AutoDis用于CTR预估,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AutoDis: Automatic Discretization for Embedding Numerical Features in CTR Prediction
Huifeng Guo, Bo Chen, Ruiming Tang, Zhenguo Li, Xiuqiang He
Noah’s Ark Lab
https://arxiv.org/pdf/2012.08986v1.pdf
推荐系统中,学习特征交互在CTR预估中非常重要。很多深层CTR模型遵循embedding 和 特征交互的范式。
大多数模型集中在特征交互模块,设计网络结构来更好的对特征交互进行建模。embedding模块,作为数据和特征交互模块的桥梁,被忽略了。
数值特征进行embedding常用的方法是归一化和离散化。前者在多个特征之间共享一个embedding,后者通过多种离散化方法,将数值特征转换为类别特征。
但是,第一种方法表达能力有限,第二种也是性能有限,因为离散化不能随着CTR模型的最终目标而优化。
为了解决数值特征的表达能力的问题,这篇文章提出一种自动离散化框架,AutoDis,它可以自动将数值特征离散化,并且以端到端的形式跟CTR模型一起优化。
具体而言,作者们为每一个数值域引入一个元embedding集合,可以对跨域的特征之间的关系进行建模,提出一种自动微分离散化和聚合方法,可以捕捉数值特征和元embedding之间的关联性。
两个公开数据集和一个工业界数据集上的实验表明,AutoDis相对STOA方法效果更优。
数值型特征不太容易利用embedding方法


这篇文章提出的AutoDis具有以下两个特性

这篇文章的主要贡献如下

目前大多数深层CTR模型基本都包含了下面两个模块

特征交互主要分为以下几类

现有的数值特征处理方法主要有以下几种
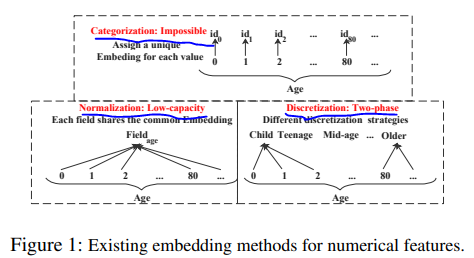
其中最常用的是离散化方法,主要分为以下几种

离散化方法存在下面三个问题

上述三个问题图示如下

AutoDis可以作为深层CTR模型的组成部分融入进去
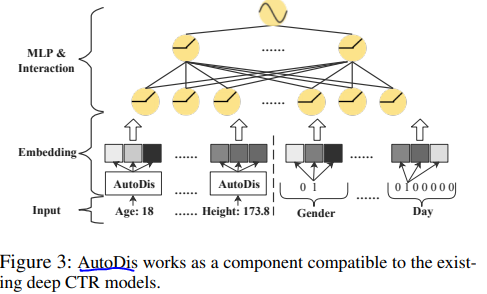
AutoDis 框架图示如下
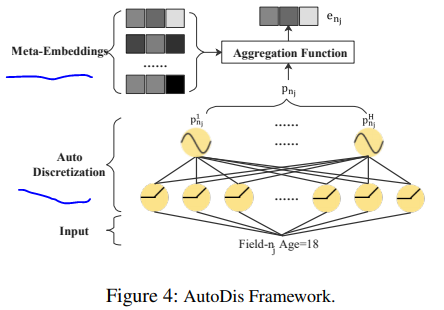
部分聚合函数以及优缺点如下


作者们提出一种新的聚合函数

在数据预处理阶段,作者们对于数值型特征利用了minmax归一化方法。

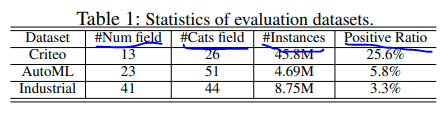
数据集信息统计如下
几种方法的效果对比如下
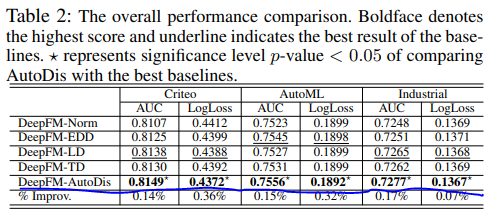
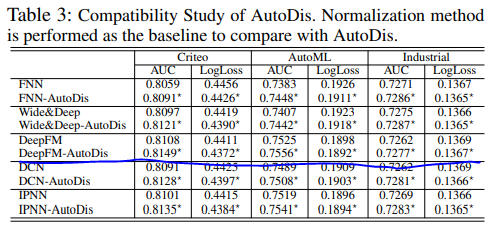
不同模型与autoDis结合的效果对比如下
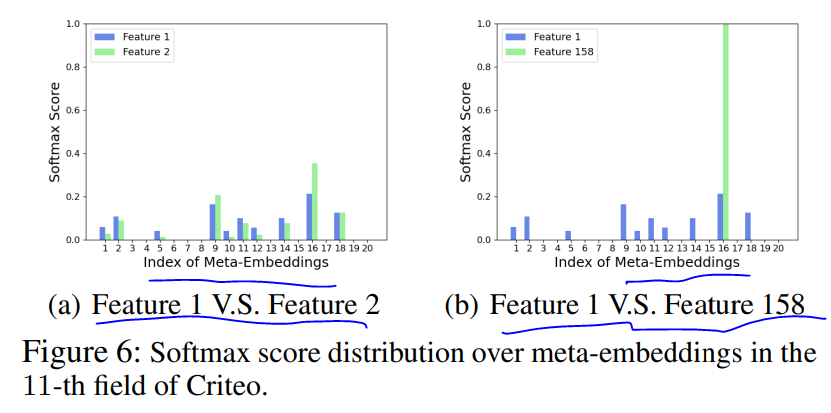
embedding可视化效果对比如下

不同的特征值元embedding softmax分布图示如下
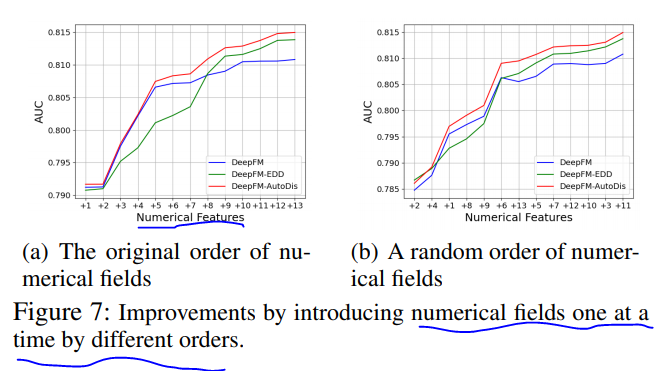
数值特征个数以及顺序对autodis的影响图示如下
不同模型的复杂度对比如下

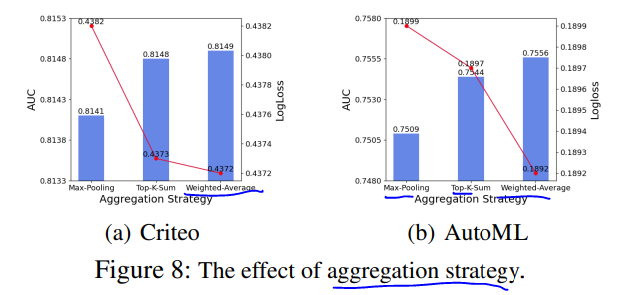
不同的聚合策略效果对比如下
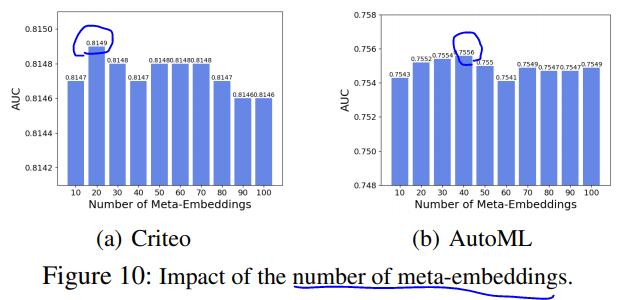
元embedding的个数对模型效果影响如下
 我是分割线
我是分割线
您可能感兴趣
乔治亚理工提出基于GAN的强化学习算法用于推荐系统
民宿平台airbnb是如何动态定价的
密歇根州立大学联合领英提出基于AutoML的Embedding框架AutoDim
密歇根州立大学联合字节提出AutoEmb用于流式推荐
深度学习在CTR预估中的应用
伊利诺伊大学联合中科院提出动态图协同过滤算法DGCF(已开源)
加州大学提出对偶注意力RNN用于时间序列预估
宾大微软联合提出深层强化学习框架用于新闻推荐
中科大等提出深度注意力网络DAM用于捆绑推荐
浙大中科院微软等提出分层注意力网络SHAN用于序列推荐系统
加州大学提出时间间隔自注意力模型用于序列推荐(已开源)
普渡大学提出轻量级特征交互算法deeplight大幅加速ctr预估在线服务(已开源)
这篇关于诺亚方舟实验室提出数值特征自动离散框架AutoDis用于CTR预估的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






