本文主要是介绍pyspark RDD和PairRDD介绍和实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装配置
Windows下pyspark的环境搭建
环境变量:
JAVA_HOME:安装文件夹/bin
HADOOP_HOME:安装文件夹/lib
SPARK_HOME:安装文件夹/bin
SPARK_PYTHON : python安装文件夹/python.exe
python中初始化sparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder \.master("local") \.appName("Word Count") \#.config("spark.some.config.option", "some-value") \.getOrCreate()
sparkSession在后台启动时,不需再创建一个SparkContext,为了获得访问权,可以简单调用sc = spark.sparkContext
python中初始化sparkContext
先创建一个SparkConf()对象配置应用,然后基于这个SparkConf()创建一个SparkContext对象
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('app') #.setMaster('local')
sc = SparkContext(conf = conf)
#sc = spark.sparkContext
RDD
创建RDD
pyspark中有两种方式可以创建RDD
用.parallelize()集合(list或array)
data = sc.parallelize([('Michael',29),('Andy',30),('Justin', 19)])
或者引用本地或者外部的文件
#从文件中读取数据时,每一行形成了RDD的一个元素
data = sc.textFile(r'**\people.txt')
运行结果如下:
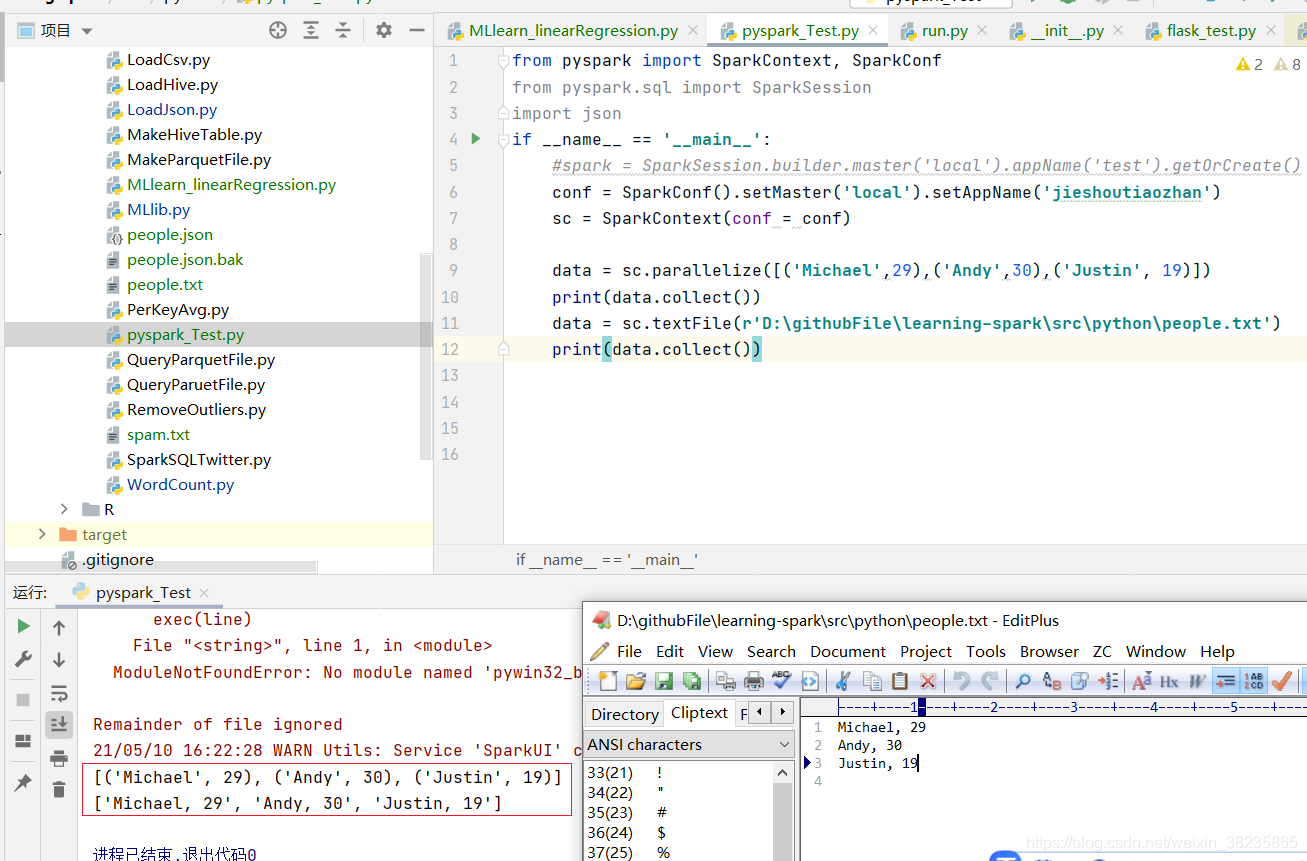
.collect()方法执行把该数据集送回驱动的操作,可以访问对象中的数据。
RDD是无schema的数据结构,所以list中的元素可以混用任何类型的数据结构,元组、列表、字典都能支持,访问数据跟python常用做法一样
data = sc.parallelize([{'Michael':29},('Andy',30),['Justin', 19]]).collect()
print(data[0]['Michael'])
#29
全局作用域和局部作用域
spark可以在两种模式运行,本地模式,集群模式。
集群模式中,驱动程序中有一组变量和方法,以便工作者在RDD上执行任务,这组变量和方法在执行者的上下文中本质时静态的,即每个执行器从驱动程序中获得一份变量和方法的副本。运行任务时,如果改变这些变量或覆盖这些方法,不会影响到其他执行者的副本或者驱动程序的变量和方法
RDD操作
RDD支持两种操作transorm转换和action行动操作。RDD的转换操作是返回一个新的RDD的操作,如map,filter,而行动操作则是向驱动器程序返回结果或把结果写入到外部系统的操作,会触发实际的运算,比如count和first
判断特定函数是返回还是行动操作,可以通过返回值类型判断,返回RDD是转换操作,其他数据类型是行动操作
以下代码是在notebook中执行,命令行运行pyspark会自动打开notebook,会自动创建sparkContext,spark变量等,使用时不必手动创建,要用时直接写sc,spark(其他python IDE自己引入包,创建变量就行)
转换
转换可以调整数据集。包括映射、筛选、连接、转换数据集中的值。
简单介绍几个转换。
filter转换
接受RDD中满足条件的元素,放入新的RDD返回。
filter操作不会改变已有的RDD中的数据,该方法返回一个全新的RDD
data = sc.textFile(r'D:\githubFile\learning-spark\src\python\people.txt')
Michael_RDD = data.filter(lambda x: 'Michael' in x)
print(data.collect(), Michael_RDD.collect())

map转换
该函数应用于每个RDD元素上
nums = sc.parallelize([1, 2, 3, 4])
squard = nums.map(lambda x: x * x).collect()
for num in squard:print(num)

flatmap
应用与RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD。常用来切分单词
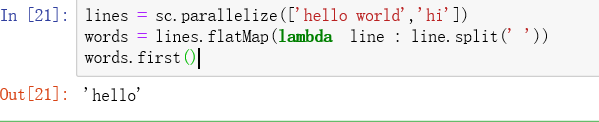
lines = sc.parallelize(['hello world','hi'])
words = lines.flatMap(lambda line : line.split(' '))
words.first()
简单的集合操作:
distinct()方法可以生成一个只包含不同元素的RDD.rdd.distinct()
union()返回包含两个RDD中所有元素的RDD,rdd.union(other)
intersection()只返回两个RDD共有的元素
subtract()返回一个由只存在第一个RDD而不存在与第二个RDD中所有元素组成的RDD
cartesian()计算两个RDD的笛卡尔积
sample()对RDD进行采样,以及是否替换rdd.sample(false,0.5)
操作action
taken方法
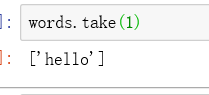
该方法优于collect()方法,只返回单个数据分区的前n行,而collect返回整个RDD
words.take(1)
如果想要随机记录,可以使用takeSample方法,该方法有3个参数,采样是否应该被替换,指定要返回的记录数,伪随机数发生的种子
words.takeSample(False,1,667)
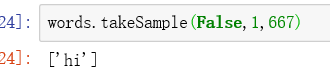
collect()方法
将所有RDD的元素返回给驱动程序
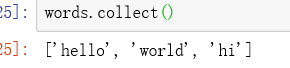
reduce()方法
使用指定的方法减少RDD元素中个数
接受一个函数作为参数,这个函数要操作两个RDD的元素并返回一个同样类型的新元素
nums = sc.parallelize([1, 2, 3, 4])
sum = nums.reduce(lambda x,y :x+y)
print(sum)
count()方法
统计RDD中元素的数量
data.count()

该方法不需要把整个数据集移动到驱动程序里
saveAsTextFile()
让RDD保存文本文件,每个文件一个分区
rdd.saveAsTextFile('***.txt')
foreach方法
对RDD每个元素,迭代,该方法对每条记录应用一个定义好的函数
nums = sc.parallelize([1, 2, 3, 4])
nums.foreach(lambda x:x*2)
当执行完foreach,发现并没有打印出来结果。
这个foreach方法是一个Action方法,而且任务执行的时候是在executor端执行的,所以它会将结果打印到executor端。
向spark传递函数
首先可以用lambda函数
也可以传递顶层函数或是定义的局部函数
word = data.filter(lambda x : 'A' in x)
def containA(s):return 'A' in s
word = data.filter(containA)
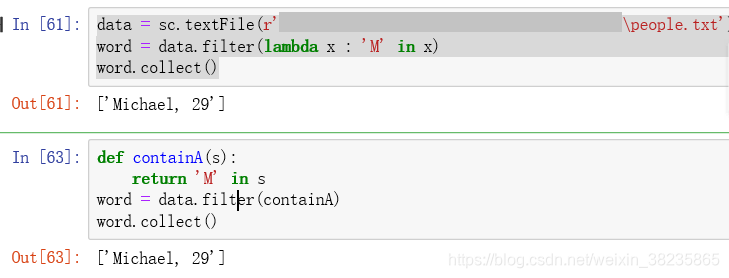
传递不带字段引用的python函数

注意:python会把函数所在对象也序列化传出去,所以只把你需要的字段从对象中拿出来放到一个局部变量中,然后传递局部变量即可避免spark将整个对象发到工作节点,因为太大,或者pthon不知道任何序列化传输的对象就会报错
计算词频实践
wordCount.py
import sysfrom pyspark import SparkContextif __name__ == "__main__":master = "local"if len(sys.argv) == 2:master = sys.argv[1]sc = SparkContext(master, "WordCount")lines = sc.parallelize(["高血压 和 糖尿病", "手术治疗 和 高血压"])result = lines.flatMap(lambda x: x.split(" ")).countByValue()print(result,type(result))# defaultdict(<class 'int'>, {'高血压': 2, '和': 2, '糖尿病': 1, '手术治疗': 1}) <class 'collections.defaultdict'>for key, value in result.items():print("%s %i" % (key, value))# 高血压 2# 和 2# 糖尿病 1# 手术治疗 1
Pair RDD
spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为pair RDD,是很多程序的构成元素,因为他们提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
创建RDD
很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的pair RDD,当需要把一个普通RDD转为pair RDD,可以调用map()函数实现,传递的函数需要返回键值对。
#为了让提取键之后的数据能够在函数中使用,需要返回一个二元组组成的RDD
pairs = lines.map(lambda x:(x.split(" ")[0],x))
转换操作
pair RDD可以使用所有标准RDD上可以的转换操作。


筛选长度小于20的数据
result = pairs.filter(lambda keyValue:len(keyValue[1]) < 20)
如果只想访问pair RDD的值部分,可以使用mapValues函数,功能类似map(case(x,y):(x,func(y))}
聚合操作
reduceByKey()与reduce()类似:接受一个函数,并用该函数对值进行合并。reduceByKey()会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。返回一个由键和对应键归约出来的结果组成新的RDD。
rdd.mapValues(lambda x:(x,1)).reduceByKey(lambda x,y :(x[0]+y[0],x[1]+y[1])

单词计数
lines = sc.parallelize(["高血压 和 糖尿病", "手术治疗 和 高血压"])
words = lines.flatMap(lambda x: x.split(" "))#.countByValue()
result = words.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
combineByKey()有多个参数分别对应聚合操作的各个阶段
计算每个键对应的平均值

并行度调优
分区数决定了在RDD上执行操作时的并行度
大多数操作符都能接受第二个参数,这个参数用来指定分组结果或聚合结果的RDD的分区数
spark也提供了repartition()函数,它会把数据通过网络进行混洗,并创建出新的分区集合。重新分区代价比较大,可以用优化版repartition() —coalesce().可以用rdd.getNumPartitions查看RDD的分区数
数据分组
groupByKey()会使用RDD中的键来对数据进行分组。对于一个由类型K的键和类型V的值组成的RDD,所得到的结果RDD类型时[K,Iterable[V]]
groupBy()可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。他可以接受一个函数,对源RDD中的每个元素使用该函数,将返回的结果作为键进行分组
连接
将有键的数据与另一组有键的数据一起使用是对数据执行很有用的操作。连接方式有:右外连接、左外连接、交叉连接、内连接
scala


数据排序
可以使用sortByKey()函数,可以接受一个ascending的参数,表示将结果升序(默认true)。
也可以使用自定义的比较函数
以字符串顺序对整数进行自定义排序
rdd.sortByKey(ascending=True,numPartitions=None,keyfunc = lambda x:str(x))Pair RDD的行动操作

数据分区
分布式程序中,通信利用的代价通常很大。可以调用partitionBy()转换操作,将表转为哈希分区,这样在连接操作时就可以利用该RDD是根据键的哈希值来分区的。由于partitionBy()是转换操作,总是返回新的RDD,应该对partitionBy()的结果进行持久化保存。
获取RDD的分区方式
在scala和Java中,可以使用RDD的partitioner属性获取RDD的分区方式

pagerank
PageRank是一种从RDD分区中获益的复杂算法。
介绍:
PagRank是一种从RDD分区中获益的更复杂的算法,我们以它为例进行分析.
PageRank算法是以Google的拉里:佩吉(Larry Page)的名字命名的,用来根据外部文档指向一个会文档的链接,对集合中每个文档的重要程度赋一个度量值。该算法可以用于对网页进行排序,当然,也可以用于排序科技文章或社交网络中有影响的用户。
PgeRank是执行多次连接的一个迭代算法,因此它是RDD分区操作的一个很好的用例。算法会维护两个数据集:一个(pageID,linkLlist)的元素组成,包含每个页面的相邻页面的列表;另一个由(pageTD, rank) 元索组成,包含每个页面的当前排序值,它按如下步骤进行计算.
原理:

代码:
scala



这篇关于pyspark RDD和PairRDD介绍和实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






