本文主要是介绍Easysearch压缩模式深度比较:ZSTD+source_reuse的优势分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战。Easysearch 具备多种压缩模式,各有千秋。本文将重点探讨一种特别的压缩模式:zstd + source_reuse,我们最近重新优化了 source_reuse,使得它在吞吐量和存储效率方面都表现出色。
测试概览
测试条件选用了 esrally 工具和 geonames 数据集来进行压力测试。数据集包含了 11396503 条记录,往单个 shard 写入,对以下几种压缩模式进行压测对比:
-
default -
best_compression -
zstd -
zstd + source_reuse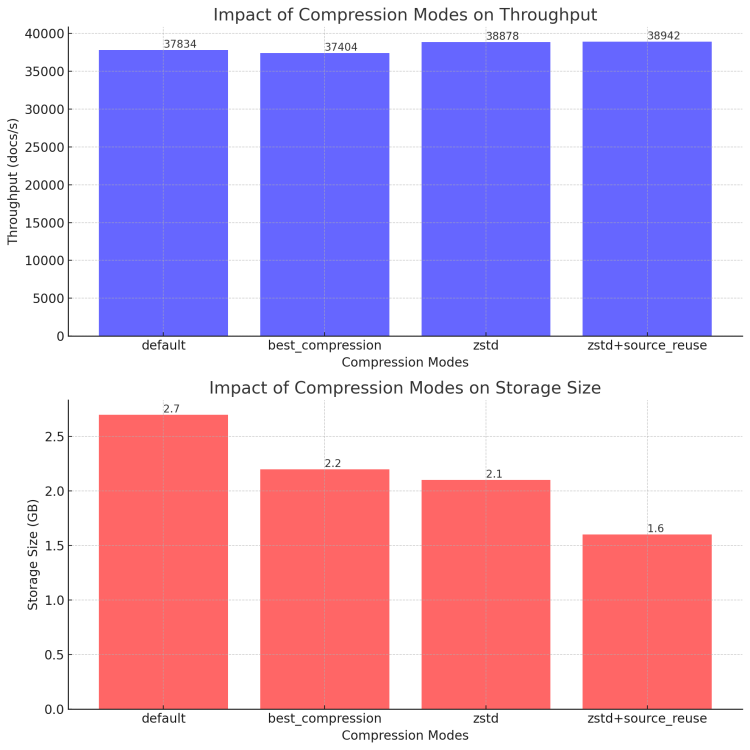
下图是对 CPU 的监控,可以看到各个模式对 CPU 的使用是基本相近的。
default
best_compression
zstd
zstd+reuse
关键数据点
测试结果主要围绕两个指标:
- 中位吞吐量:单位为“每秒操作数”,数值越大表示性能越好。
- 存储大小:单位为 “GB”,数值越小表示存储更加高效。
测试数据如下:
| 压缩模式 | 中位吞吐量 (docs/s) | 存储大小 (GB) |
|---|---|---|
| default | 37834 | 2.7 |
| best_compression | 37404 | 2.2 |
| zstd | 38878 | 2.1 |
| zstd + source_reuse | 38942 | 1.6 |
zstd + source_reuse:压缩原理
该模式采用了 source_reuse 压缩算法,该算法通过对 keyword、long、int、short、boolean 等类型的字段值进行复用,并结合 zstd 压缩算法,大大提高了存储效率。
压缩效率
zstd + source_reuse 在存储大小上的表现尤为出色,针对 geonames 数据集只需 1.6 GB 的存储空间,相比于 best_compression 模式的 2.2 GB,压缩效率显著提高。
吞吐量表现
高压缩率并没有让 zstd + source_reuse 在吞吐量上做出妥协,因为高压缩率使得其需要持久化的数据大大减小,其中位吞吐量为 38942 docs/s,在 4 种模式中表现最好。
结论
zstd + source_reuse 压缩模式在存储效率和查询性能之间找到了一种极佳的平衡,强烈推荐各位在使用 Easysearch 时,当存储成本比较敏感时,考虑使用 zstd + source_reuse 压缩模式。无论是在存储成本还是写入性能方面,它都能为你带来显著的优势。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
这篇关于Easysearch压缩模式深度比较:ZSTD+source_reuse的优势分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





