本文主要是介绍数据结构 - 3(链表12000字详解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:LinkedList的使用
1.1 ArrayList的缺陷
上篇文章我们已经基本熟悉了ArrayList的使用,并且进行了简单模拟实现。由于其底层是一段连续空间,当在ArrayList任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为O(n),效率比较低,因此ArrayList不适合做任意位置插入和删除比较多的场景。因此:java集合中又引入了LinkedList,即链表结构。
1.2 链表的概念及结构
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。

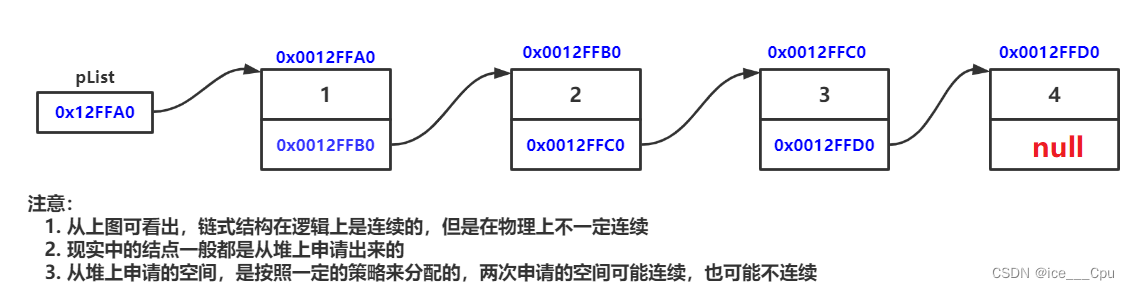
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
- 单向或者双向
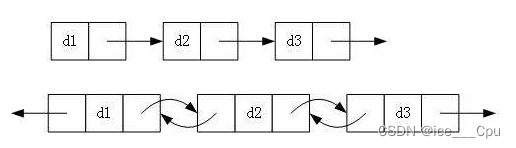
- 带头或者不带头
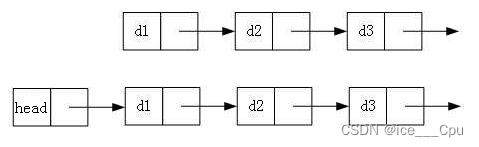
- 循环或者非循环
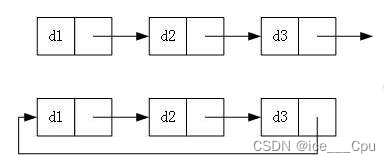
虽然有这么多的链表的结构,但是我们重点掌握两种:
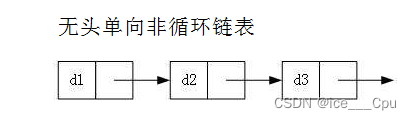
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
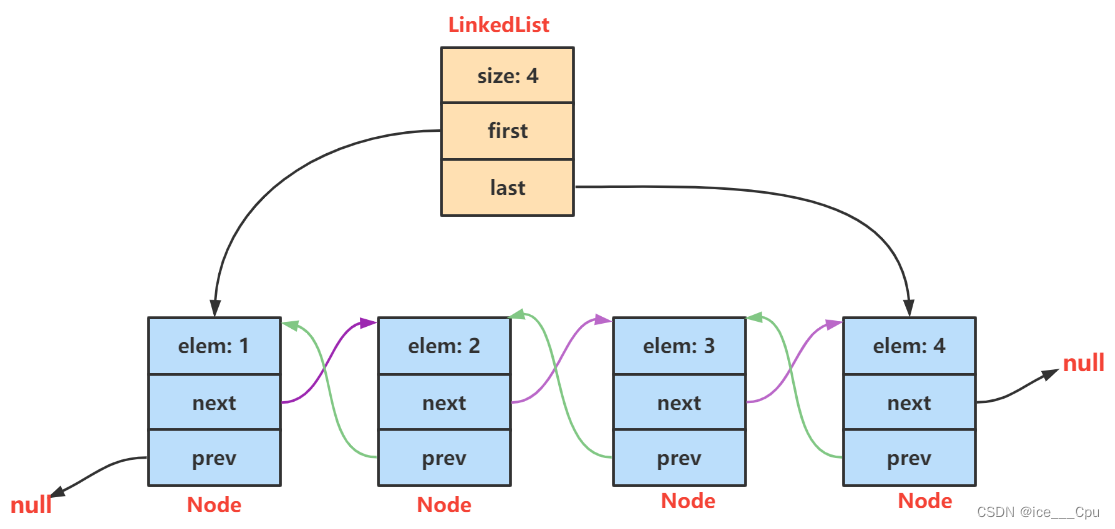
- 无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
1.3 LinkedList的使用
LinkedList的底层是双向链表结构(链表后面介绍),由于链表没有将元素存储在连续的空间中,元素存储在单独的节点中,然后通过引用将节点连接起来了,因此在在任意位置插入或者删除元素时,不需要搬移元素,效率比较高。
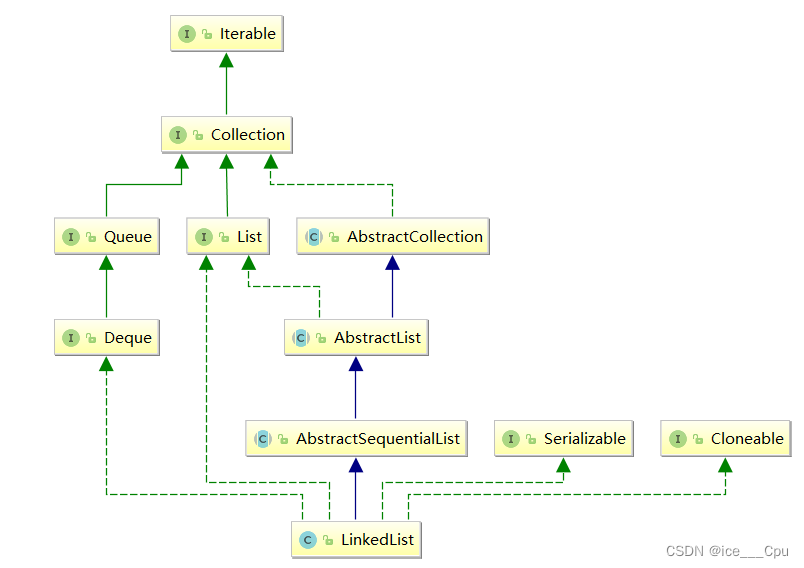
在集合框架中,LinkedList也实现了List接口,具体如下:
【说明】
- LinkedList实现了List接口
- LinkedList的底层使用了双向链表
- LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
- LinkedList的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
- LinkedList比较适合任意位置插入的场景
1.4 LinkedList的构造方法
LinkedList的构造方法
| 方法 | 解释 |
|---|---|
| LinkedList() | 无参构造 |
| public LinkedList(Collection<? extends E> c) | 使用其他集合容器中元素构造List |
public LinkedList(Collection<? extends E> c) 是 Java 中 LinkedList 类的一个构造方法。它的作用是创建一个新的 LinkedList 对象,并将指定集合中的所有元素添加到该链表中。
下面是代码示例:
List<String> list1 = new ArrayList<>();
list1.add("Apple");
list1.add("Banana");
list1.add("Orange");LinkedList<String> linkedList = new LinkedList<>(list1);
在这个例子中,我们先创建了一个 ArrayList 类型的集合 list1,并向其中添加了三个字符串元素。然后我们使用 LinkedList 的构造方法将 list1 转换为一个新的 LinkedList 对象,并将 list1 中的所有元素添加到链表中。
1.5 LinkedList的常用方法
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List subList(int fromIndex, int toIndex) | 截取部分 list |
下面是使用示例:
public static void main(String[] args) {LinkedList<Integer> list = new LinkedList<>();// add(elem): 表示尾插list.add(1); list.add(2);list.add(3);list.add(4);list.add(5);list.add(6);list.add(7);System.out.println(list.size());System.out.println(list);// add(index, elem): 在index位置插入元素elemlist.add(0, 0); System.out.println(list);// remove(): 删除第一个元素,内部调用的是removeFirst()list.remove(); // removeFirst(): 删除第一个元素list.removeFirst(); // removeLast(): 删除最后元素list.removeLast(); // remove(index): 删除index位置的元素list.remove(1); System.out.println(list);// contains(elem): 检测elem元素是否存在,如果存在返回true,否则返回falseif(!list.contains(1)){list.add(0, 1);}
list.add(1);System.out.println(list);// indexOf(elem): 从前往后找到第一个elem的位置System.out.println(list.indexOf(1)); // lastIndexOf(elem): 从后往前找第一个1的位置System.out.println(list.lastIndexOf(1)); // get(index): 获取指定位置元素int elem = list.get(0); // set(index, elem): 将index位置的元素设置为elemlist.set(0, 100); System.out.println(list);// subList(from, to): 用list中[from, to)之间的元素构造一个新的LinkedList返回List<Integer> copy = list.subList(0, 3); System.out.println(list);System.out.println(copy);// 将list中元素清空list.clear(); System.out.println(list.size());
}
1.6ArrayList和LinkedList的区别
| 不同点 | ArrayList | LinkedList |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
二:LinkedList模拟实现
2.1无头单向非循环链表
// 1、无头单向非循环链表实现
public class SingleLinkedList {//头插法public void addFirst(int data){}//尾插法public void addLast(int data){}//任意位置插入,第一个数据节点为0号下标public void addIndex(int index,int data){}//查找是否包含关键字key是否在单链表当中public boolean contains(int key){return false;}//删除第一次出现关键字为key的节点public void remove(int key){}
//删除所有值为key的节点public void removeAllKey(int key){}//得到单链表的长度public int size(){return -1;}//清空链表public void clear() {}//打印链表public void display() {}
}
下面是模拟实现后的代码:
public class SingleLinkedList {private Node head; // 链表头节点// 节点类private class Node {int data;Node next;public Node(int data) {this.data = data;this.next = null;}}// 头插法,在链表头部插入新节点public void addFirst(int data) {Node newNode = new Node(data); // 创建一个新节点newNode.next = head; // 将新节点的next指向当前头节点head = newNode; // 将新节点设置为头节点}// 尾插法,在链表尾部插入新节点public void addLast(int data) {Node newNode = new Node(data); // 创建一个新节点if (head == null) { // 如果链表为空,将新节点设置为头节点并返回head = newNode;return;}Node curr = head; // 从头节点开始遍历链表,找到最后一个节点while (curr.next != null) {curr = curr.next;}curr.next = newNode; // 将新节点链接到最后一个节点的next上}// 任意位置插入,在指定位置插入新节点public void addIndex(int index, int data) {if (index < 0 || index > size()) { // 检查插入位置的合法性throw new IndexOutOfBoundsException("Index out of range"); // 抛出越界异常}if (index == 0) { // 如果插入位置是头部,调用addFirst方法addFirst(data);} else if (index == size()) { // 如果插入位置是尾部,调用addLast方法addLast(data);} else { // 在指定位置插入新节点Node newNode = new Node(data); // 创建新节点Node prev = getNode(index - 1); // 获取插入位置前一个节点newNode.next = prev.next; // 将新节点的next指向插入位置节点的nextprev.next = newNode; // 插入位置节点的next指向新节点}}// 查找是否包含关键字keypublic boolean contains(int key) {Node curr = head; // 从头节点开始遍历链表while (curr != null) {if (curr.data == key) { // 如果节点的data等于关键字key,返回truereturn true;}curr = curr.next; // 继续向下一个节点遍历}return false; // 遍历完链表都没有找到关键字key,返回false}// 删除第一次出现关键字为key的节点public void remove(int key) {if (head == null) { // 如果链表为空,直接返回return;}if (head.data == key) { // 如果头节点的data等于关键字key,将头节点指向下一个节点并返回head = head.next;return;}Node prev = head; // 设置prev指针指向头节点Node curr = head.next; // 设置curr指针指向头节点的下一个节点while (curr != null) { // 从头节点的下一个节点开始遍历链表if (curr.data == key) { // 如果节点的data等于关键字key,将prev节点的next指向当前节点的下一个节点并返回prev.next = curr.next;return;}prev = curr; // prev和curr指针向后移动curr = curr.next;}}// 删除所有值为key的节点public void removeAllKey(int key) {if (head == null) { // 如果链表为空,直接返回return;}// 处理头节点为key的情况while (head != null && head.data == key) { // 如果头节点的data等于关键字key,将头节点指向下一个节点head = head.next;}Node prev = head; // 设置prev指针指向头节点Node curr = head != null ? head.next : null; // 设置curr指针指向头节点的下一个节点while (curr != null) { // 从头节点的下一个节点开始遍历链表if (curr.data == key) { // 如果节点的data等于关键字key,将prev节点的next指向当前节点的下一个节点prev.next = curr.next;} else { // 否则prev指针和curr指针向后移动prev = curr;}curr = curr.next;}}// 得到单链表的长度public int size() {int count = 0; // 计数变量Node curr = head; // 从头节点开始遍历链表while (curr != null) {count++; // 每遍历一个节点,计数器加一curr = curr.next; // 移动到下一个节点}return count; // 返回计数器的值}// 清空链表public void clear() {head = null; // 将头节点置为null}// 获取指定位置上的节点private Node getNode(int index) {if (index < 0 || index >= size()) { // 检查索引的合法性throw new IndexOutOfBoundsException("Index out of range"); // 抛出越界异常}Node curr = head; // 从头节点开始遍历链表for (int i = 0; i < index; i++) { // 遍历到指定位置的节点curr = curr.next;}return curr; // 返回指定位置的节点}// 打印链表public void display() {Node curr = head; // 从头节点开始遍历链表while (curr != null) {System.out.print(curr.data + " "); // 打印当前节点的数据curr = curr.next; // 移动到下一个节点}System.out.println(); // 换行}public static void main(String[] args) {SingleLinkedList list = new SingleLinkedList();list.addFirst(1); // 在链表头部插入节点 1list.addLast(3); // 在链表尾部插入节点 3list.addIndex(1, 2); // 在下标为 1 的位置插入节点 2list.display(); // 打印链表:1 2 3System.out.println("Contains 2: " + list.contains(2)); // 判断链表是否包含关键字 2,结果为 truelist.remove(2); // 删除首次出现的关键字为 2 的节点list.display(); // 打印链表:1 3list.addLast(1);list.addLast(2);list.addLast(3);list.display(); // 打印链表:1 3 1 2 3list.removeAllKey(1); // 删除所有值为 1 的节点list.display(); // 打印链表:3 2 3System.out.println("Size: " + list.size()); // 获取链表长度,结果为 3list.clear(); // 清空链表list.display(); // 打印链表:空}
}2.2 无头双向非循环链表
// 2、无头双向链表实现
public class MyLinkedList {//头插法public void addFirst(int data){ }//尾插法public void addLast(int data){}//任意位置插入,第一个数据节点为0号下标public void addIndex(int index,int data){}//查找是否包含关键字key是否在单链表当中public boolean contains(int key){}//删除第一次出现关键字为key的节点public void remove(int key){}//删除所有值为key的节点public void removeAllKey(int key){}//得到单链表的长度public int size(){}public void display(){}//清空public void clear(){}
}
下面是模拟实现后的代码:
// 2、无头双向链表实现
public class MyLinkedList {// 节点类private class Node {private int data; // 节点存储的数据private Node prev; // 前一个节点的引用private Node next; // 下一个节点的引用public Node(int data) {this.data = data; // 初始化节点的数据为传入的datathis.prev = null; // 初始化前一个节点的引用为nullthis.next = null; // 初始化下一个节点的引用为null}}private Node head; // 头节点private Node tail; // 尾节点private int size; // 链表长度// 头插法public void addFirst(int data) {Node newNode = new Node(data); // 创建一个新节点,存储传入的数据if (head == null) { // 如果头节点为null,说明链表为空head = newNode; // 将头节点指向新节点tail = newNode; // 将尾节点指向新节点} else { // 链表不为空newNode.next = head; // 将新节点的下一个节点指向当前头节点head.prev = newNode; // 将当前头节点的前一个节点指向新节点head = newNode; // 将头节点指向新节点}size++; // 链表长度加1}// 尾插法public void addLast(int data) {Node newNode = new Node(data); // 创建一个新节点,存储传入的数据if (tail == null) { // 如果尾节点为null,说明链表为空head = newNode; // 将头节点指向新节点tail = newNode; // 将尾节点指向新节点} else { // 链表不为空tail.next = newNode; // 将当前尾节点的下一个节点指向新节点newNode.prev = tail; // 将新节点的前一个节点指向当前尾节点tail = newNode; // 将尾节点指向新节点}size++; // 链表长度加1}// 任意位置插入,第一个数据节点为0号下标public void addIndex(int index, int data) {if (index < 0 || index > size) { // 如果索引小于0或者大于链表长度,抛出索引超出范围的异常throw new IndexOutOfBoundsException("Index out of bound");}if (index == 0) { // 如果要插入的位置是头节点前面,即插入为头节点addFirst(data); // 使用头插法} else if (index == size) { // 如果要插入的位置是尾节点后面,即插入为尾节点addLast(data); // 使用尾插法} else { // 在中间位置插入节点Node newNode = new Node(data); // 创建一个新节点,存储传入的数据Node currNode = goToIndex(index); // 找到要插入位置的前一个节点newNode.prev = currNode.prev; // 将新节点的前一个节点指向要插入位置的前一个节点newNode.next = currNode; // 将新节点的下一个节点指向要插入位置的节点currNode.prev.next = newNode; // 将要插入位置的前一个节点的下一个节点指向新节点currNode.prev = newNode; // 将要插入位置的节点的前一个节点指向新节点size++; // 链表长度加1}}// 查找是否包含关键字key是否在单链表当中public boolean contains(int key) {Node currNode = head; // 从头节点开始查找while (currNode != null) { // 当前节点不为nullif (currNode.data == key) { // 如果当前节点的数据等于关键字return true; // 返回true}currNode = currNode.next; // 继续下一个节点}return false; // 没找到关键字,返回false}// 删除第一次出现关键字为key的节点public void remove(int key) {Node currNode = head; // 从头节点开始查找while (currNode != null) { // 当前节点不为nullif (currNode.data == key) { // 如果当前节点的数据等于关键字if (currNode == head) { // 如果当前节点是头节点head = currNode.next; // 将头节点指向当前节点的下一个节点if (head != null) {head.prev = null; // 如果头节点不为null,将新头节点的前一个节点设置为null}if (currNode == tail) { // 如果当前节点是尾节点tail = null; // 将尾节点置为null}} else if (currNode == tail) { // 如果当前节点是尾节点tail = currNode.prev; // 将尾节点指向当前节点的前一个节点tail.next = null; // 将新尾节点的下一个节点设置为null} else { // 在中间位置删除节点currNode.prev.next = currNode.next; // 将要删除节点的前一个节点的下一个节点指向要删除节点的下一个节点currNode.next.prev = currNode.prev; // 将要删除节点的下一个节点的前一个节点指向要删除节点的前一个节点}size--; // 链表长度减1return; // 删除完成,结束方法}currNode = currNode.next; // 继续下一个节点}}// 删除所有值为key的节点public void removeAllKey(int key) {Node currNode = head; // 从头节点开始查找while (currNode != null) { // 当前节点不为nullif (currNode.data == key) { // 如果当前节点的数据等于关键字if (currNode == head) { // 如果当前节点是头节点head = currNode.next; // 将头节点指向当前节点的下一个节点if (head != null) {head.prev = null; // 如果头节点不为null,将新头节点的前一个节点设置为null}if (currNode == tail) { // 如果当前节点是尾节点tail = null; // 将尾节点置为null}currNode = head; // 将当前节点指向新的头节点} else if (currNode == tail) { // 如果当前节点是尾节点tail = currNode.prev; // 将尾节点指向当前节点的前一个节点tail.next = null; // 将新尾节点的下一个节点设置为nullcurrNode = null; // 将当前节点置为null,用于结束循环} else { // 在中间位置删除节点currNode.prev.next = currNode.next; // 将要删除节点的前一个节点的下一个节点指向要删除节点的下一个节点currNode.next.prev = currNode.prev; // 将要删除节点的下一个节点的前一个节点指向要删除节点的前一个节点Node tempNode = currNode.next; // 保存需要删除的节点的下一个节点的引用currNode.next = null; // 将要删除节点的下一个节点置为nullcurrNode.prev = null; // 将要删除节点的前一个节点置为nullcurrNode = tempNode; // 将当前节点指向保存的下一个节点}size--; // 链表长度减1} else {currNode = currNode.next; // 继续下一个节点}}}// 得到双向链表的长度public int size() {return size; // 返回链表的长度}// 辅助函数,用于定位到指定索引的节点private Node goToIndex(int index) {Node currNode = head; // 从头节点开始int count = 0; // 计数器,记录已经遍历的节点个数while (count < index) { // 当计数器小于索引时currNode = currNode.next; // 继续下一个节点count++; // 计数器加1}return currNode; // 返回找到的节点}// 清空双向链表public void clear() {head = null; // 将头节点置为nulltail = null; // 将尾节点置为nullsize = 0; // 链表长度置为0}// 打印双向链表public void display() {Node currNode = head; // 从头节点开始while (currNode != null) { // 当前节点不为nullSystem.out.print(currNode.data + " "); // 打印当前节点的数据currNode = currNode.next; // 继续下一个节点}System.out.println(); // 换行}public static void main(String[] args) {MyLinkedList list = new MyLinkedList(); // 创建一个新的双向链表对象list.addFirst(1); // 在链表头插入数据1list.addLast(2); // 在链表尾插入数据2list.addIndex(1, 3); // 在索引1处插入数据3list.display(); // 输出:1 3 2System.out.println(list.contains(2)); // 输出:truelist.remove(3); // 删除数据3list.display(); // 输出:1 2list.removeAllKey(2); // 删除所有值为2的节点list.display(); // 输出:1list.clear(); // 清空链表System.out.println(list.size()); // 输出:0}
}2.3LinkedList的遍历
当我们使用Java中的LinkedList类时,有几种方式可以进行遍历。我们可以使用foreach循环,也可以使用迭代器对链表进行正向和反向遍历。下面是代码示例:
首先,让我们创建一个LinkedList对象并向其添加一些元素
import java.util.LinkedList;public class LinkedListTraversal {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("Apple");linkedList.add("Banana");linkedList.add("Cherry");linkedList.add("Durian");}
}
- 使用foreach循环遍历
使用foreach循环可以直接遍历LinkedList中的元素。在每次迭代中,我们可以通过一个变量来访问当前元素。下面是使用foreach循环遍历LinkedList的示例代码:
for (String fruit : linkedList) {System.out.println(fruit);
}
输出结果为:
Apple
Banana
Cherry
Durian
- 使用迭代器进行正向遍历
LinkedList实现了Iterable接口,因此我们可以使用迭代器在链表上进行正向遍历。通过调用iterator()方法,我们可以获取一个Iterator对象,然后使用hasNext()和next()方法来迭代遍历链表中的元素。下面是使用迭代器进行正向遍历的示例代码:
Iterator<String> iterator = linkedList.iterator();
while (iterator.hasNext()) {String fruit = iterator.next();System.out.println(fruit);
}
输出结果为:
Apple
Banana
Cherry
Durian
- 使用迭代器进行反向遍历
LinkedList还提供了一个descendingIterator()方法,返回一个逆向迭代器,使我们可以反向遍历链表中的元素。通过调用hasNext()和next()方法,我们可以从尾部开始向前迭代遍历LinkedList。下面是使用迭代器进行反向遍历的示例代码:
Iterator<String> descendingIterator = linkedList.descendingIterator();
while (descendingIterator.hasNext()) {String fruit = descendingIterator.next();System.out.println(fruit);
}
输出结果为:
Durian
Cherry
Banana
Apple
以上就是LinkedList遍历的三种方式!
这篇关于数据结构 - 3(链表12000字详解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



