本文主要是介绍Tachyon0.6.4+Spark1.3+hadoop2.6.0 配置教程详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文在安装前已经配置好了spark1.3和hadoop2.6,因项目需求需要搭建tachyon,但是搭建过程中遇到了很多很多很多的问题,写下本文用来记录这一路上所踩过的坑
吐槽一句:tachyon的官方文档不是很完善啊,完全按照他的做肯定成功不了。。。
单节点安装
先说单点,单点搞定,集群就简单了
安装tachyon,官网(https://github.com/amplab/tachyon/releases)下载了最新版本的二进制包,然后按照官方的教程一步一步来,首先是配置local(http://www.tachyon-project.org/Running-Tachyon-Locally.html)模式的,官网的教程非常的简单,我本以为可以一气呵成搞定tachyon,结果。。。
第一步:将下载好的tachyon-0.6.4-bin.tar.gz解压:
chmod 755 tachyon-0.6.4-bin.tar.gz
tar -xvfz tachyon-0.6.4-bin.tar.gz
第二步:配置conf/tachyon-env.sh:
mv tachyon-env.sh.tmplate tachyon-env.sh
第三步:修改tachyon-env.sh
export JAVA="$JAVA_HOME/bin/java"
export TACHYON_MASTER_ADDRESS=master.hadoop(注:你本机的hostname)
export TACHYON_UNDERFS_ADDRESS=/home/hadoop/tachyon
export TACHYON_WORKER_MEMORY_SIZE=1GB
export TACHYON_UNDERFS_HDFS_IMPL=org.apache.hadoop.hdfs.DistributedFileSystem
第四步: 把conf/slaves 和conf/works 中的localhost都改为master.hadoop
第五步: ./bin/tachyon format
第六步: ./bin/tachyon-start.sh local
注意:若非root用户会出现权限不足的问题,修改/etc/sudoers,在root下面添加你的用户权限:
vim /etc/sudoers
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL(添加这一行)
第一次失败
在运行./bin/tachyon format 的时候报了如下错误:
(如果没遇到可以跳过这一步)
Formatting Tachyon Worker @ master.hadoop
/opt/tachyon-0.6.4-uncomp/bin/tachyon: line 243: /../bin/java: 没有那个文件或目录
咦?是没有安装java吗?不应该啊,因为我的java是手工安装的,所以tachyon去默认的目录下去寻找java没有找到
但是我也配置了JAVA_HOME啊,的确是个很奇怪的问题。接下来咱们看看/conf/tachyon-env.sh文件中脚本是咋写的:
if [ -z "$JAVA_HOME" ]; then
if [ -d /usr/lib/jvm/java-7-oracle ]; then
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
else
# openjdk will set this
if [ -d /usr/lib/jvm/jre-1.7.0 ]; then
export JAVA_HOME=/usr/lib/jvm/jre-1.7.0
fi
fi
fi
这里显示很有可能没有读到JAVA_HOME,在脚本中加入测试代码结果显示确实没有读到JAVA_HOME,目前我也不知道为什么,如果有人知道的话希望能给我留言。
这个问题的解决方法:
在文件开头重新 export JAVA_HOME=/opt/jdf1.7
搞定!
第二次失败
将本地文件系统改为hdfs:
将tachyon-env.sh中的TACHYON_UNDERFS_ADDRESS修改为:
export TACHYON_UNDERFS_ADDRESS=hdfs://master.hadoop:8020/tachyon
其中8020的端口取决于你得hadoop core.site文件中的端口
修改过后format,结果得到如下错误:
Exceptionin thread "main" java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException: Server IPC version 9 cannot communicate with client version 4
之所以有这个错误是因为tachyon目前仅支持hadoop1.x版本的hdfs,因此若想让tachyon支持2.6.0就需要重新编译tachyon,
下载源码(https://github.com/amplab/tachyon/releases),
使用mvn进行编译:
编译之前需要修改tachyon目录下的pom.xml来指定hadoop版本:
<properties>
<test.profile>local</test.profile>
<test.output.redirect>true</test.output.redirect>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.7</java.version>
<hadoop.version>2.6.0</hadoop.version>
<glusterfs-hadoop.version>2.3.13</glusterfs-hadoop.version>
<libthrift.version>0.9.1</libthrift.version>
<cxf.version>2.7.0</cxf.version>
<jetty.version>7.6.15.v20140411</jetty.version>
<slf4j.version>1.7.2</slf4j.version>
<powermock.version>1.5.4</powermock.version>
<log4j.version>1.2.17</log4j.version>
<apache.curator.version>2.1.0-incubating</apache.curator.version>
<license.header.path>build/license/</license.header.path>
<checkstyle.path>build/checkstyle/</checkstyle.path>
<findbugs.path>build/findbugs/</findbugs.path>
</properties>
(或者你不修改pom文件直接在运行的时候加上-Dhadoop.version=2.6.0也可)
然后再源码根目录下运行
mvn clean package -Dmaven.test.skip=true
-Dmaven.test.skip=true 是为了跳过测试,如果你没修改源码可以不用测试
因为国内的网络环境(感谢GFW),中间会出现很多次错误,这些都不用管,反复重新编译就行了,mvn会从上次失败的地方重新编译,所以不用担心。
编译成功后,和之前的配置方法再来一遍
搞定!
第三次失败
现在tachyon和hadopp之间已经兼容了,下面在spark中使用tachyon:
第一步:在hadoop/etc/hadoop/core-site.xml文件,加入如下内容:
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>
第二步:测试,将文件存到hdfs:
将hdfs中的文件存储到tachyon中:
val s = sc.textFile("hdfs://master.hadoop:8020/你的文件")
s.saveAsTextFile("tachyon://master.hadoop:19998/")
第三步:在spark-default中添加;
spark.tachyonStore.url=tachyon://master.hadoop:19998
第四步:测试,将RDD cache 到tachyon中:
val rdd = sc.textFile(inputPath)
rdd.persist(StorageLevel.OFF_HEAP)
注意:千万不要按照官网所说,在spark的conf下创建core-site.xml
,而是要在hadoop的etc/hadoop/core-site.xml添加,不然会覆盖了hadoop的配置文件,后果会很严重
但是,在用spark和tachyon交互的时候,发生了如下错误:
15/05/20 13:35:48 ERROR : Invalid method name: 'getDataFolder'
15/05/20 13:35:48 ERROR : Invalid method name: 'user_getFileId'
15/05/20 13:35:48 ERROR TachyonBlockManager: Failed 10 attempts to create tachyon dir in /tmp_spark_tachyon/spark-95f8e8e1-f8f8-4172-8371-b9ba36c277a3/<driver>
找不到方法,这个错误的原因是,spark的版本又和tachyon不兼容,我们有两个解决方法:
1.对spark重新编译,修改tachyon的版本
2.使用tachyon0.5.0,亲测可用哦
集群安装
到目前为止,单机版的环境就全部跑通了,对于集群那就很简单了:
1.修改slaves文件,添加你的work节点的hostname
2.将整个tachyon文件分别拷贝到各个机器上
3.运行./bin/tachyon format
4./bin/tachyon-start.sh all SudoMount
注意:别忘了在每台slave上修改sudoers,此外,如果你是非root用户就要用 all SudoMount,否则就算修改了sudoers也会提示:
无法创建目录"/mnt/ramdisk": 权限不够
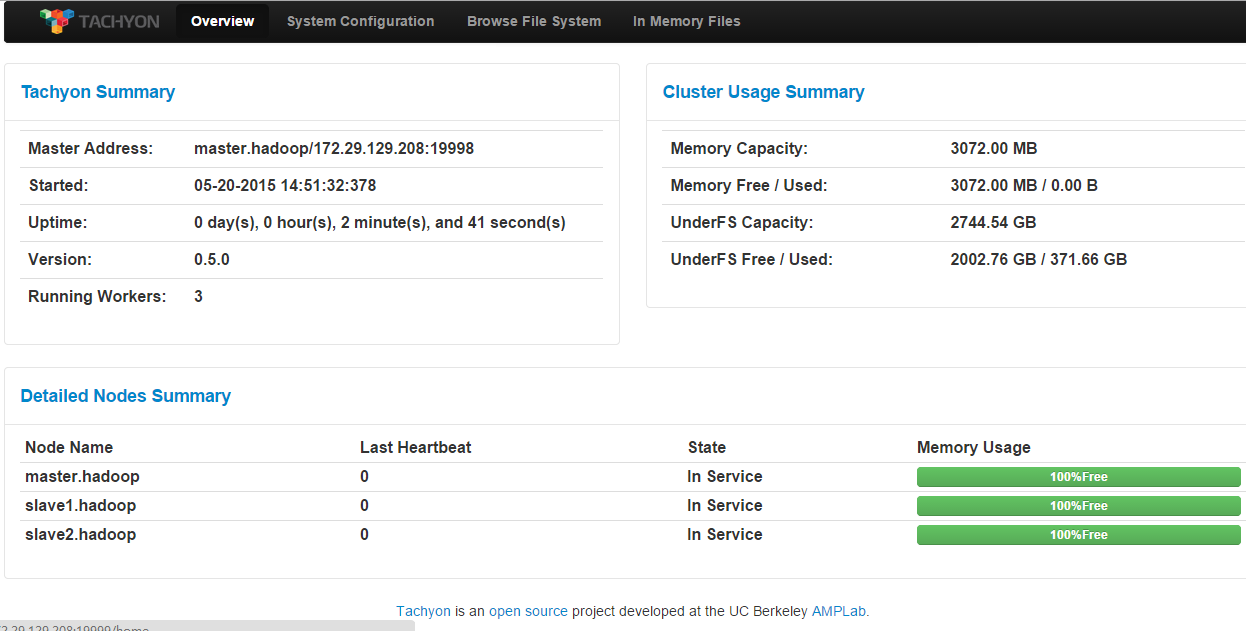
最后来一张:最终的ui:
http://blog.csdn.net/wzq294328238/article/details/45868711
这篇关于Tachyon0.6.4+Spark1.3+hadoop2.6.0 配置教程详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






