本文主要是介绍使用docker搭建kafka集群、可视化操作台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
单机搭建
1 拉取zookeeper镜像
docker pull wurstmeister/zookeeper
2 启动zookeeper容器
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper
3 拉取kafka镜像
docker pull wurstmeister/kafka
4 启动kafka镜像
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.56.103:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.103:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
5 拉取kafka-map镜像
docker pull dushixiang/kafka-map:latest
6 启动kafka-map容器
docker run -d --name kafka-map \
-p 9001:8080 \
-v /opt/kafka-map/data:/usr/local/kafka-map/data \
-e DEFAULT_USERNAME=admin \
-e DEFAULT_PASSWORD=admin \
dushixiang/kafka-map:latest
7 访问:http://192.168.56.103:9001
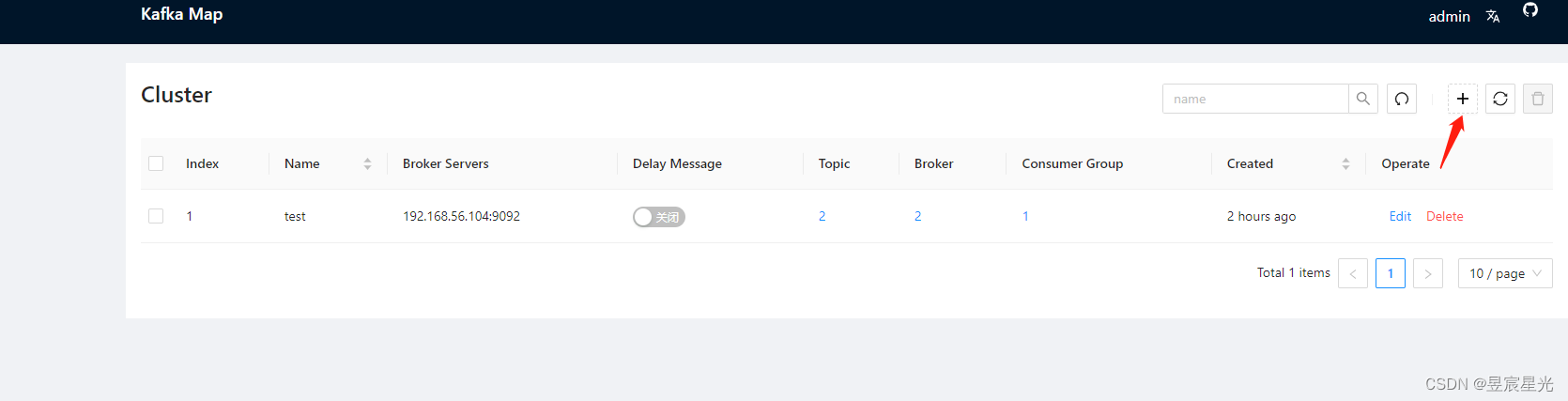
点击右上角+号完成kafka的接入:
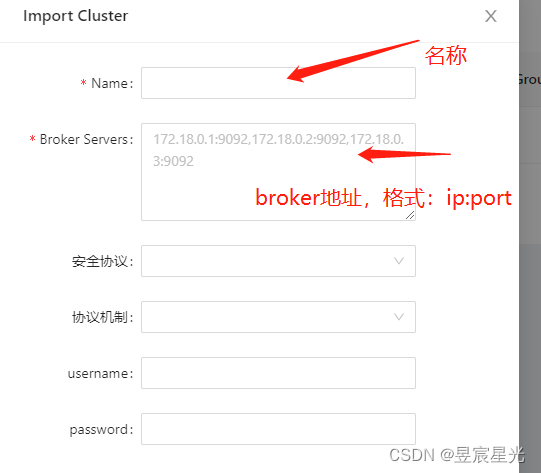
9 kafka常用命令
docker exec -it kafka /bin/bash
cd /opt/kafka_2.13-2.8.1/bin
创建主题:
./kafka-topics.sh --create --bootstrap-server 192.168.56.103:9092,192.168.56.104:9092 --partitions 2 --replication-factor 2 --topic first-create
作为消费端:
./kafka-console-consumer.sh --bootstrap-server 192.168.56.103:9092,192.168.56.104:9092 --topic test-4 --from-beginning
作为生产者:
./kafka-console-producer.sh --bootstrap-server 192.168.56.103:9092,192.168.56.104:9092 --topic test-4
集群搭建
本次基于docker搭建kafka集群,zookeeper使用单实例
1 准备2台虚拟机,ip分别是:192.168.56.103,192.168.56.104
2 104 上操作
a 拉取zookeeper镜像
docker pull wurstmeister/zookeeper
b 启动zookeeper容器
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper
c 拉取kafka镜像
docker pull wurstmeister/kafka
d 启动kafka容器
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.56.104:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.104:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
e 拉取kafka-map镜像
docker pull dushixiang/kafka-map:latest
f 启动kafka-map容器
docker run -d --name kafka-map \
-p 9001:8080 \
-v /opt/kafka-map/data:/usr/local/kafka-map/data \
-e DEFAULT_USERNAME=admin \
-e DEFAULT_PASSWORD=admin \
dushixiang/kafka-map:latest
3 103上操作
a 拉取kafka镜像
docker pull wurstmeister/kafka
b 启动kafka容器
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=192.168.56.103:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.103:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
注意:103和104启动kafka的区别就是指定不同的KAFKA_BROKER_ID,如果是以配置文件启动的,在配置文件中修改即可
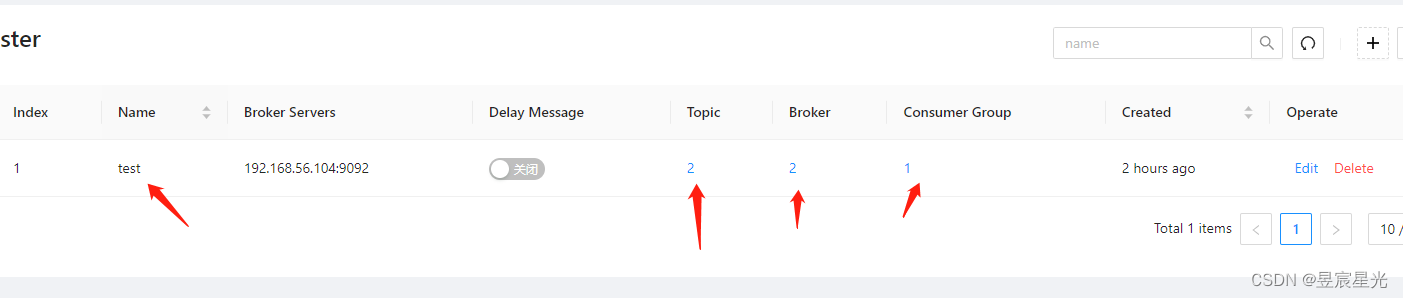
4 登录到kafka-map上创建对应的kafka集群信息,实现界面化操作
这篇关于使用docker搭建kafka集群、可视化操作台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





