本文主要是介绍深度学习之CSPNet分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、提出原因
二、CSPNet结构分析
1、基本思想
2、对比实验:
3、综述设计思想
一、提出原因
CSPNet是从网络结构体系角度提出的跨阶段局部网络,主要有以下几个目的:
(1)增强CNN的学习能力,并且在轻量化的同时保持准确性
神经网络推理过程中计算量过高是网络优化中的梯度信息重复所导致的。CSPNet将梯度的变化从头到尾集成到特征图中,这样就可以在减少了计算量的同时可以保证准确率。
(2)降低计算瓶颈
过高的计算瓶颈会导致更多的周期来完成神经网络的推理过程,或者一些算术单元经常处于空闲状态。因此,如果能在CNN的每一层上均匀地分配计算量,就能有效地提高每个计算单元的利用率,从而减少不必要的能耗。
(3)降低内存成本
在特征金字塔生成过程中采用跨通道池来压缩特征映射,可以减少内存使用。
二、CSPNet结构分析
CSPNet不单单是一个网络,更是一种可移植的思想方法,可以与多种网络结构结合。
1、基本思想
(1)将之前所有层的输出特征连接起来,作为下一层的输入,最大化 cardinality(分支路径的数量)。
(2)由梯度信息结合的思想,让高 cardinality 和稀疏连接来提升网络的学习能力。
2、对比实验:
上图中的Transition Layer代表过渡层,主要包含瓶颈层(1×1卷积)和池化层(可选)
(1)先concat再transition
上图为原始的DenseNet的特征融合方式,下图为Fusion First。
DenseNet网络简介:其每一阶段包含一个dense block和一个transition layers(放在两个Dense Block中间,是因为每个Dense Block结束后的输出通道数很多,要使用1*1的卷积核来降维),每个dense block由多个dense layer组成。(优点:特征重复使用)
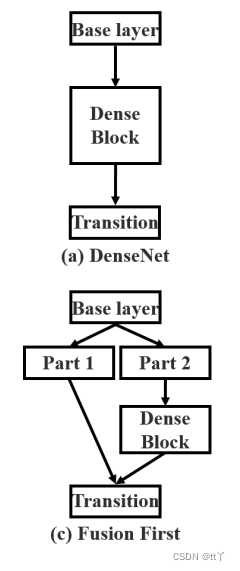
Fusion First :将两个分支生成的特征映射连接(concat)起来,然后进行转换操作(Transition)。如果采用这种策略,将会重用大量的梯度信息。
(2)先transition再concat
左图为原始的DenseNet的特征融合方式,右图为Fusion Last。
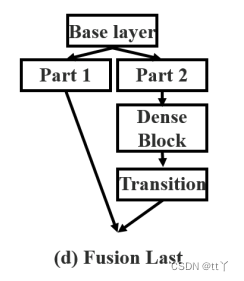
Fusion Last:稠密块(Dense Block)的输出将经过过渡层,然后与第一部分的feature map进行拼接,由于梯度流被截断,梯度信息将不再被重用,计算量显著降低。
3、综述设计思想
一半的特征进入dense layer,通过通道拆分来减少计算量,是一种网络优化的方法,但是对精度的提升好像帮助并不大。
Partial Dense Block
(1)增加了渐变路径:采用拆分合并的思想,拆成两部分,让渐变路径的数目翻倍
(2)均衡各层的计算:因为在局部密集块中参与密层操作的基层通道只有原来数量的一半,因此可以减少近一半的计算瓶颈
(3)减少内存流量
Partial Transition Layer
(分析对应上面的对比试验)
它是一种层次化的特征融合机制,采用了截断梯度流的策略(就是对半拆)来防止不同的层学习重复的梯度信息,最大化梯度组合的差异。
这篇关于深度学习之CSPNet分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







