本文主要是介绍MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CVPR2021 MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection
知识点学习:
多实例学习https://zhuanlan.zhihu.com/p/299819082
练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。
训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别
原因之一是为了解决正样本数目过少,导致普通分类会导致类间不平衡
WS-VAD可以分为两类,编码器无关(The encoder-agnostic)方法和基于编码器(encoder-based methods)的方法。
-
💯 编码器无关方法[23,32,27]利用从表示为E的普通特征编码器中提取的视频的任务不可知特征
-
基于编码器的方法同时训练特征编码器和分类器:
- 最先进的基于编码器的方法是Zhong等人[35],其将WS-VAD表述为标签噪声学习问题,并从标签噪声清洁器网络过滤的噪声标签中学习
-
有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
视频异常行为识别 半监督领域 video-level 注释
-
背景(研究现状、痛点)
-
弱监督视频异常检测(WS-VAD)是基于鉴别表示将异常与正常事件区分开来。
-
大多数现有作品的视频表现不足。因为它需要模型理解正常和异常事件之间的内在差异,特别是罕见且变化很大的异常事件。
-
以前的工作将VAD视为一项无监督的学习任务,仅使用正常训练样本对通常的模式进行编码,然后将不同的编码模式检测为异常。
-
同时,将视频级别标签指定给每个剪辑会产生标签噪声。
-
此外,现有的方法没有考虑有效地训练特定于任务的特征编码器,该编码器为监控摄像机下的事件提供区分表示。
-
-
论文试图解决什么问题?如何解决
解决视频异常行为的弱监督学习。我们的工作也是一种基于编码器的方法,以在线细粒度方式(如何实现)工作(work in an online fine-grained manner),但我们使用伪标签生产器生成伪标签,来优化我们的特征编码器ESGA,而不是直接使用视频级标签作为伪标签。此外,我们设计了一个两阶段自训练方案,以有效地优化我们的特征编码器和伪标签生成器,而不是迭代优化
-
这是否是一个新的问题?
否
-
有什么贡献?

①提出了基于MIL的伪标签生成器,基于MIL的方法可以比那些简单地为每个剪辑分配视频级别标签的方法更准确地生成伪标签(怎么实现的?),采用稀疏连续采样(怎么稀疏采样?)策略,可以迫使网络更加关注最异常(异常连接怎么就可以更加关注更异常的部分,后面有说)部分周围的上下文。
② 提出了Self-guided attention boosted feature encoder自导式注意力增强特征编码器,我们在我们提出的特征编码器中利用提出的自我引导(如何实现自我引导?)注意模块来强调不带任何外部注释的异常区域,而是正常视频的剪辑级注释和异常视频的剪辑级别伪标签。
-
这篇文章要验证一个什么科学假设?
-
论文中提到的解决方案之关键是什么?解决的细节。有什么样的结论?
主要是两个网络,伪标签生成器 和 自导式注意力增强特征编码器

分为两个阶段,
第一个阶段:
Vn,Va首先打包,形成Bn,Ba ,接着通过E,一种训练好的vanilla feature encoder(通常是I3D、C3D,注意这不是EGSA) ,生成特征向量 { f i a } i = 1 N and { f i n } i = 1 N \left\{\mathbf{f}_i^a\right\}_{i=1}^N \text { and }\left\{\mathbf{f}_i^n\right\}_{i=1}^N {fia}i=1N and {fin}i=1N , 接着首先进行稀疏连续采样(如下),接着采用MIL排名损失网络训练得到分数,得到视频clips的异常分数 { s i a } i = 1 N , { s i n } i = 1 N ) \left.\left\{s_i^a\right\}_{i=1}^N,\left\{s_i^n\right\}_{i=1}^N\right) {sia}i=1N,{sin}i=1N) ,这样就是训练伪标签生成器G。
稀疏连续采样 3.2
MIL+粗粒度,固定视频分割的长度容易将异常行为隐藏,但是 通过细粒度的方式,网络可能会过度强调异常的最强烈部分,而忽略其周围的环境。在假设异常持续时间最短的情况下,MIL网络被迫更加关注最异常部分周围的环境
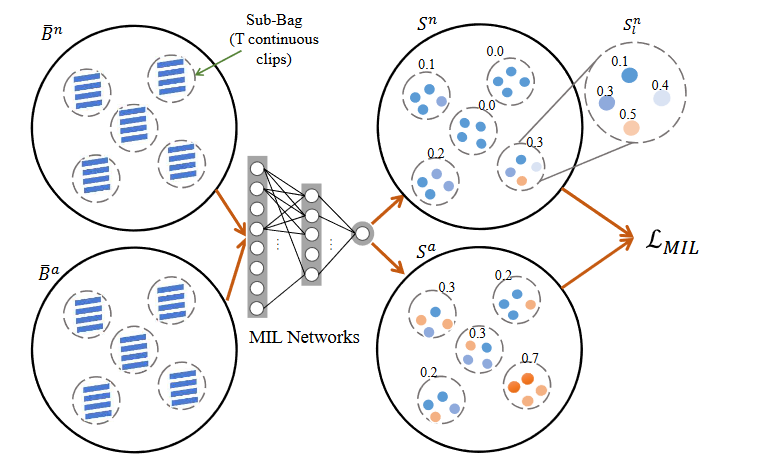
这个是生成器的其中一个环节,左边是两个包,一个是都是正常视频的包,一个是含有异常视频的包,包内有子包(这个有什么作用的吗?) 。将f特征 sample L个子集,每一个子集包含 T个连续的clips 。
中间是基于MIL排名损失网络,右边为输出,是对每个包以及子包的异常评分,其中子包的分数是子包内所有clips的平均分。
生成器:一个3层MLP,其中单元的数量分别为512、32和1,通过每层之间的概率为0.6的丢弃进行正则化
通过使用移动平均滤波器执行时间平滑以缓解核大小为k的异常分数的抖动
s ~ i a = 1 2 k ∑ j = i − k i + k s j a \tilde{s}_i^a=\frac{1}{2 k} \sum_{j=i-k}^{i+k} s_j^a s~ia=2k1j=i−k∑i+ksja
min-max Normalization:
y ^ i a = ( s ~ i a − min S ~ a ) / ( max S ~ a − min S ~ a ) ) , i ∈ [ 1 , N ] \left.\hat{y}_i^a=\left(\tilde{s}_i^a-\min \tilde{S}^a\right) /\left(\max \tilde{S}^a-\min \tilde{S}^a\right)\right), i \in[1, N] y^ia=(s~ia−minS~a)/(maxS~a−minS~a)),i∈[1,N]计算结果y hat 作为软伪标签(这里说一下,软标签是以概率形式存在的,而通常我们见过的是硬标签,非1即0的这种确定性标签。)
接着利用smothing(yperforming smoothing)和BN归一化去生成 标签 Y ^ a = { y ^ i a } i = 1 N \hat{Y}^a=\left\{\hat{y}_i^a\right\}_{i=1}^N Y^a={y^ia}i=1N(其实主要处理的是带有异常行为的视频,而正常的数据集一般最终得到的 Y 向量 是全0 或者接近 0 的向量,但是他是怎么做到的正常视频那里变成了全0 ? 跟我看的smothing的算法不一样,猜测这里作者的用意只是想改变伪标签的值,对于真实标签不会去修改他,保持为0 )
解释一下里面的变量:
Vn,Va 分别是 正常、含有异常的视频片
Bn,Ba 是一个包,把一整个视频V当作包,vi 当做实例,Bn是全正常行为,Ba至少含有一个异常示例va
{ s i a } i = 1 N , { s i n } i = 1 N ) \left.\left\{s_i^a\right\}_{i=1}^N,\left\{s_i^n\right\}_{i=1}^N\right) {sia}i=1N,{sin}i=1N) 是异常得分。
Y是伪标签
smothing
传统的one-hot 编码的标签 ,非黑即白,过于绝对。采用smothing标签平滑后的分布就相当于往真实分布中加入了噪声,避免模型对于正确标签过于自信,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
$$
\hat{y}_i=y \operatorname{hot}(1-\alpha)+\alpha / K \
\hat{y}_i=\left{\begin{array}{lc}
1-\alpha, & i=\text { target } \
\alpha / K, & i \neq \text { target }
\end{array}\right.
$$
知识补充
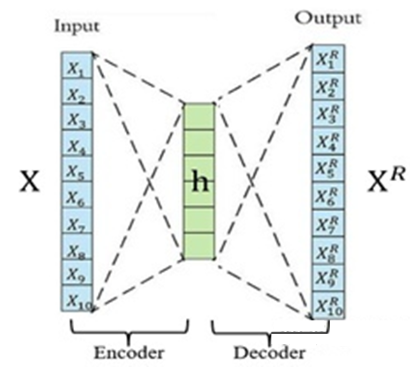
瓶颈层的自编码器又称为香草自编码器,香草自编码器,只有三层网络,即只有一个隐藏层的神经网络。它的输入和输出是相同的,可通过使用 Adam 优化器和均方误差损失函数,来学习如何重构输入。
自编码器的种类:https://cloud.tencent.com/developer/article/2163147
自编码器的作用?
AE算法?
Auto-Encoder,中文称作自编码器,是一种无监督式学习模型。它基于反向传播算法与最优化方法(如梯度下降法),利用输入数据 X XX 本身作为监督,来指导神经网络尝试学习一个映射关系,从而得到一个重构输出 X^R 。编码器阶段将信息进行压缩,墙皮网络学习最有用的信息量的特征,而解码器就是还原,期望最好的状态就是输入与输出一样。
作用:可以实现数据降维
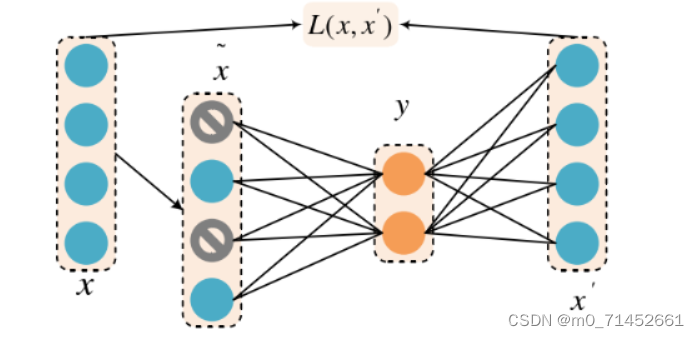
DAE深度自编码器:Denoising Auto Encoder, DAE
首先以一定概率将原始数据x矩阵中的部分数据置0,得到丢失数据的残缺输入矩阵x,然后以x为输入,一层一层编码得到压缩后的矩阵y,再通过一层一层编码得到输出x,根据x’和x之间的误差进行网络参数学习和迭代,这样就得到想要的压缩后的编码y。这种原理类似于深度神经网络中的Dropout,通过看似不全的训练过程,实际上能够得到泛化能力和鲁棒性更好的模型。降噪自动编码器结构如图。
第二阶段:3.3
将打好伪标签的数据输入到 Esga 编码网络,通过伪标签进行预测与网络训练
下面这幅图实际上是对上面两阶段式的阶段二的详细框架:
主要有 左上角自编码器E的输出特征为输出、SGA模块(绿色虚线框内,根据上文以及代码的含义,用红色线进行了一下修正),Hc 模块
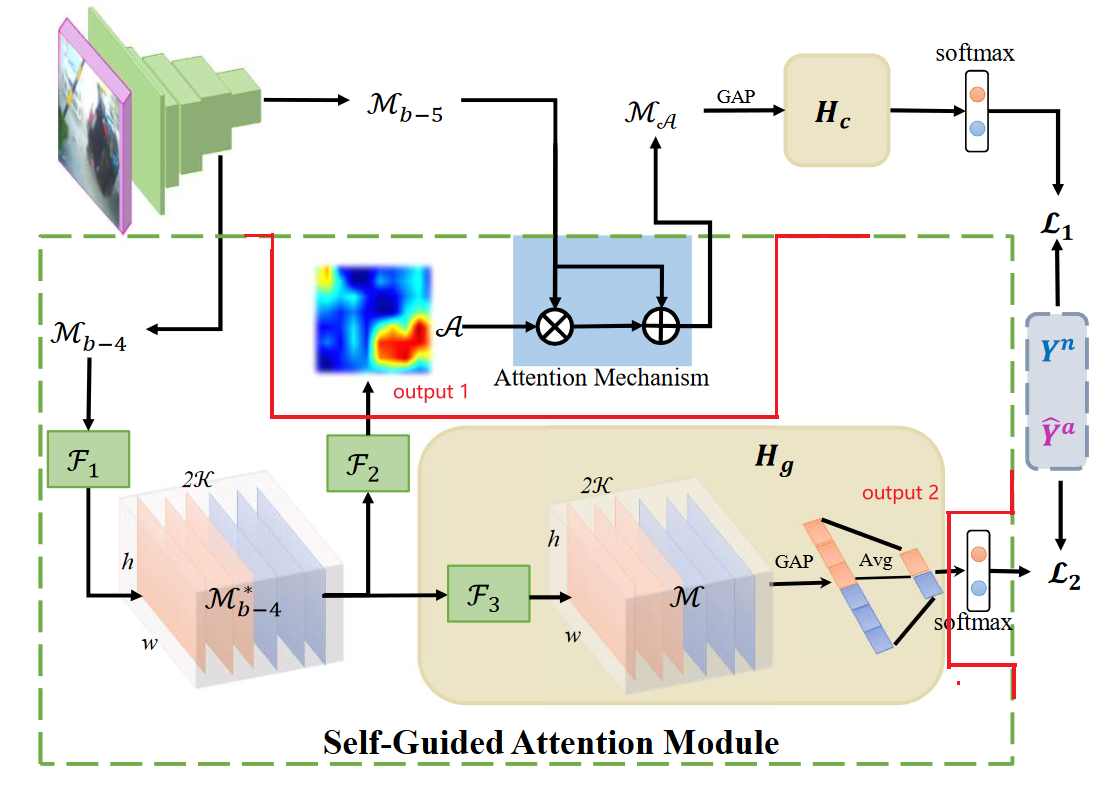
最上角是自编码器E(C3D等) 预训练模型的输出特征feat_map
Mb-5 、Mb_4 分别是自编码器E的第5、4层输出 (在代码中,也是最后两层)
💯 为什么要用 第四、五层? (在代码中,也是最后两层)
我个人感觉实际上是在最后两层之间加了类似self-attention,但是呢,又不是那种简单的attention,是作者自己研究的SGAttention 模块https://blog.csdn.net/daige123/article/details/125750345
F1 F2 F3 是卷积层编码单元,每一个形式如下:(基本类似),他们的作用是编码?怎么能实现编码呢?
nn.Conv3d(in_channels,self.num_headers,kernel_size=(1,1,1)),nn.ReLU()
M b − 4 ∗ M^{*}_{b-4} Mb−4∗ 就是 M b − 4 M^{}_{b-4} Mb−4 编码后的,然后应用于注意力图(attention map)A生成,表示为
A = F 1 ( F 2 ( M b − 4 ) ) . \mathcal{A}=\mathcal{F}_1\left(\mathcal{F}_2\left(\mathcal{M}_{b-4}\right)\right) . A=F1(F2(Mb−4)).
Finally, we obtain M A \mathcal{M}_A MA通过注意力机制可以表示为:
M A = M b − 5 + A ∘ M b − 5 , \mathcal{M}_{\mathcal{A}}=\mathcal{M}_{b-5}+\mathcal{A} \circ \mathcal{M}_{b-5}, MA=Mb−5+A∘Mb−5,
这里的 ∘ \circ ∘ is 逐元素乘法, and M A \mathcal{M}_{\mathcal{A}} MA是通过加权分类头Hc(一个完全连接的层)应用于最终异常分数预测
在后面的Hg是作者提出的一个可以帮助学习注意力吐的模块,它使用伪标签作为监督。然后,在M和Softmax激活上部署时空平均池、K通道平均池,以获得每个类的引导异常分数。
Deep MIL Ranking Loss损失函数:
为什么要用这种形式的损失函数,可能与多实例学习MIL有关(Real-world Anomaly Detection in Surveillance Videos CVPR 2018说明了这个由来 https://blog.csdn.net/weixin_43889476/article/details/127951266)
将异常检测作为回归问题。我们希望异常视频片段具有比正常片段更高的异常分数。直接的方法是使用排序损失,这会鼓励异常视频片段与正常片段相比获得高分
S l n < S l a \mathcal{S}_l^n<\mathcal{S}_l^a Sln<Sla
在缺少视频片段级别注释的情况****下,上述公式不成立。提出了以下多实例排序目标函数
max 1 ≤ l ≤ L S l n < max 1 ≤ l ≤ L S l a \max _{1 \leq l \leq L} \mathcal{S}_l^n<\max _{1 \leq l \leq L} \mathcal{S}_l^a 1≤l≤LmaxSln<1≤l≤LmaxSla
为了在异常分数方面将正实例和负实例分得更开**。因此,利用铰链(hinge)损失公式中的排名损失如下
L M I L = ( ϵ − max 1 ≤ l ≤ L S l a + max 1 ≤ l ≤ L S l n ) + + λ L ∑ l = 1 L S l a \mathcal{L}_{M I L}=\left(\epsilon-\max _{1 \leq l \leq L} \mathcal{S}_l^a+\max _{1 \leq l \leq L} \mathcal{S}_l^n\right)_{+}+\frac{\lambda}{L} \sum_{l=1}^L \mathcal{S}_l^a LMIL=(ϵ−1≤l≤LmaxSla+1≤l≤LmaxSln)++Lλl=1∑LSla
最后一项是稀疏正则化,表明只有少数子包可能包含异常,而λ是用于平衡排序损失和稀疏正则化的另一个超参数。
实验部分:
-
论文中的实验是如何设计的?
跟不同算法对比,说明自己比别人优秀(控制变量)
做了消融实验
最后举例说明算法的正确性(比距聚焦在哪里)
-
用于定量评估的数据集是什么?代码有没有开源?
UCF-Crime、ShanghaiTech
-
论文中的实验及结果有没有很好地支持需要验证的科学假设?
消融实验:
探究了伪标签技术、自引导注意力模块SGA以及特征编码器SGA中Hg的影响
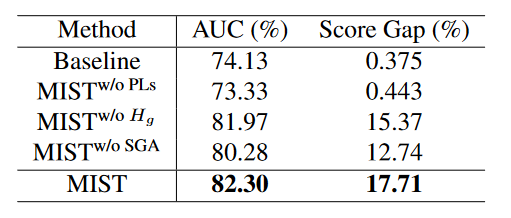
基线是使用视频级别标签训练的原始I3D
当使用生成的伪标签时,我们的MIST实现了显著的改进。特别是,我们观察到AUC提高了8.17%,得分差距约为17%,这表明了我们的多实例伪标签生成器与稀疏连续采样策略的有效性。
此外,SGA增强了特征编码器在强调信息区域和区分异常事件与正常事件方面的能力。与M IST w/oSGA相比,MIST AUC增加2%,得分差距增加5%。
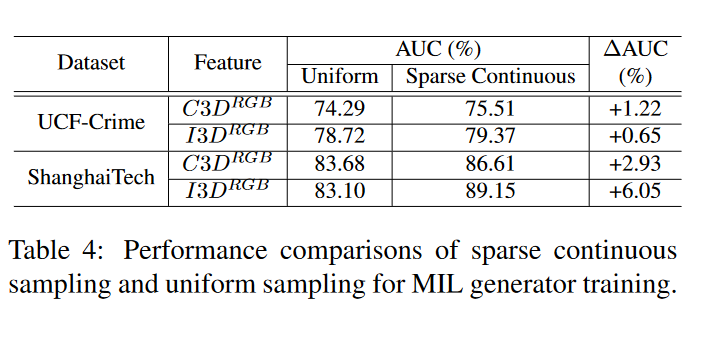
还对UCF犯罪和ShanghaiTech采用C3DRGB和I3DRGB特征的稀疏连续采样策略进行了消融研究。如表4所示,当为一个包采样相同数量的剪辑并选择相同数量的顶部剪辑来表示该包时,我们的稀疏连续采样策略更加关注上下文,比均匀采样做得更好。
下面是均匀采样和稀疏采样的差别:
总结部分,思考:
为什么要分成两个阶段?
首先,我们的目的是什么?希望能够输入一小段视频(没有任何标签,包括视频级别的),然后经过一个复杂的神经网络,最后预测得到视频异常的概率,
而单纯的第一阶段,是一个多实例的学习,输入的数据是带有视频级别的视频,输出是clips级别的异常得分。但是测试阶段,没法实现上面的目的,或者说预测正确的概率非常低。并且,作者设置第一阶段的目的是为了产生伪标签,为第二阶段做好准备。
而第二阶段,可以实现这个目的。在训练过程中,每一小段视频,有标签和伪标签,经过网络输出每一小段异常的得分,做类似的监督训练。
为什么要分成两个阶段?
首先,我们的目的是什么?希望能够输入一小段视频(没有任何标签,包括视频级别的),然后经过一个复杂的神经网络,最后预测得到视频异常的概率,而单纯的第一阶段,是一个多实例的学习,输入的数据是带有视频级别的视频,输出是clips级别的异常得分。但是测试阶段,没法实现上面的目的,或者说预测正确的概率非常低。并且,作者设置第一阶段的目的是为了产生伪标签,为第二阶段做好准备。而第二阶段,可以实现这个目的。在训练过程中,每一小段视频,有标签和伪标签,经过网络输出每一小段异常的得分,做类似的监督训练。在测试过程中,测试数据视频没有标签,经过第二阶段训练好的网络得到异常概率得分(当然,测试阶段其实也只是用了一部分网络。)
这篇关于MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




