本文主要是介绍❤️爬虫截热榜长屏不方便阅读!推荐dominate直接生成报告❤️,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前学委之前写了一篇热榜长榜单爬虫截屏的文章和 快速优雅HTML报表开发
这次玩大一点,我们把热榜直接爬下来存为报告查看。
先看看效果:
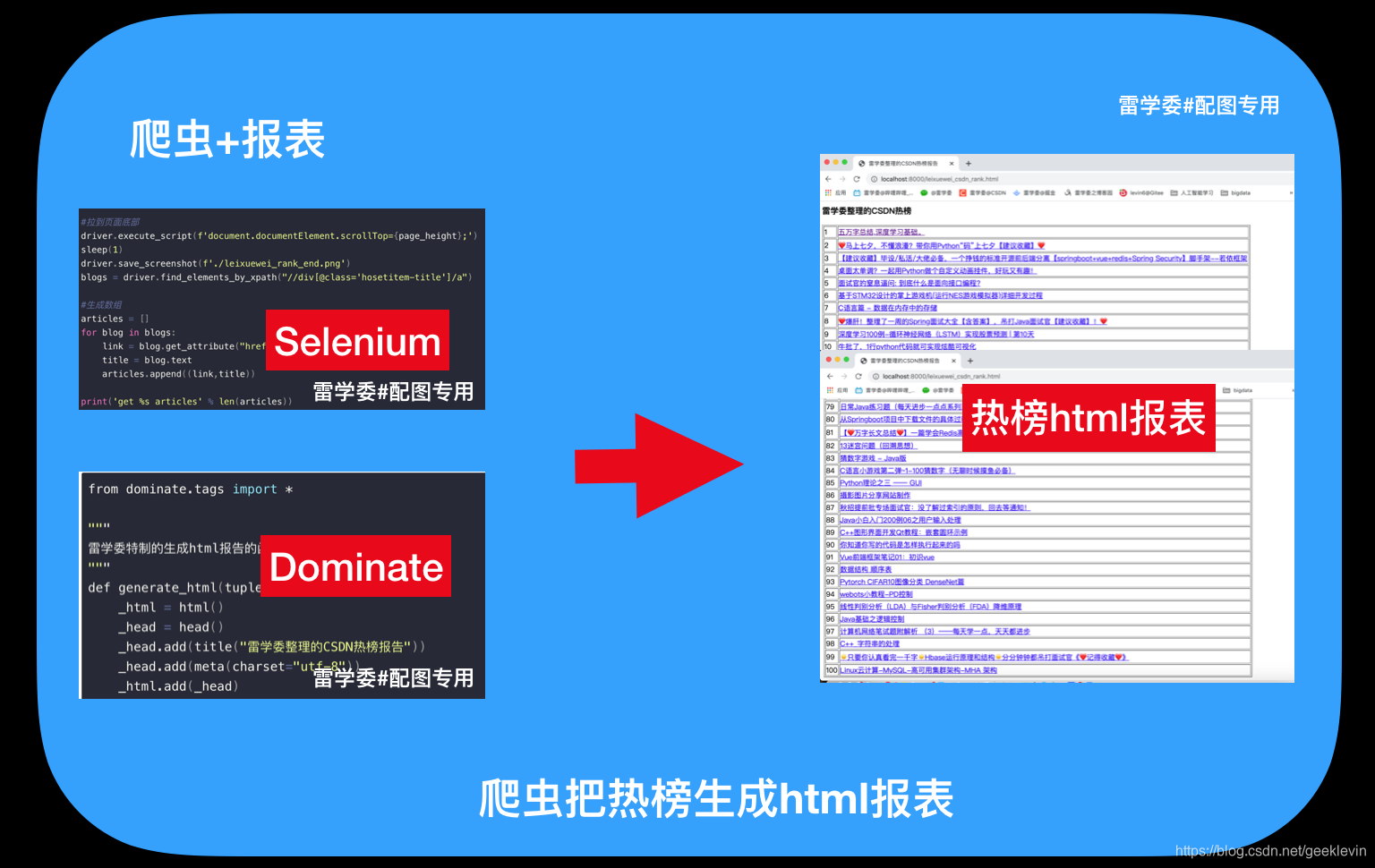
搞起来!
第一步 生成报告
没听错,爬虫先放着,无中生有,随便搞点数据先把报告生成了。
保存下面代码为report.py,后面会用这个名字引入。
from dominate.tags import *"""
雷学委特制的生成html报告的函数
"""
def generate_html(tuples):_html = html()_head = head()_head.add(title("雷学委整理的CSDN热榜报告"))_head.add(meta(charset="utf-8"))_html.add(_head)_body = _html.add(body())_table = table(border=1)with _table.add(tbody()):index = 0for tp in tuples:index += 1leiXW = tr()leiXW += td(str(index))leiXW += td(a(tp[1],href=tp[0]))with _body.add(div(cls="leixuewei")):h3("雷学委整理的CSDN热榜")_body.add(_table)return _html.render()"""
雷学委特制的直接生成保存报告的函数
"""
def lei_report(leixuewei_tuples, path):data = generate_html(leixuewei_tuples)with open(path, "w") as f:f.write(data)if __name__ == "__main__":lxw_tuples = []lxw_tuples.append(("https://blog.csdn.net/geeklevin/article/details/119594295","雷学委Python生成Html报表"))lxw_tuples.append(("https://blog.csdn.net/geeklevin/article/details/116771659","Docker玩腻了,不妨试试用Vagrant"))path = "./csdn_rank.html"lei_report(lxw_tuples, path)代码解析
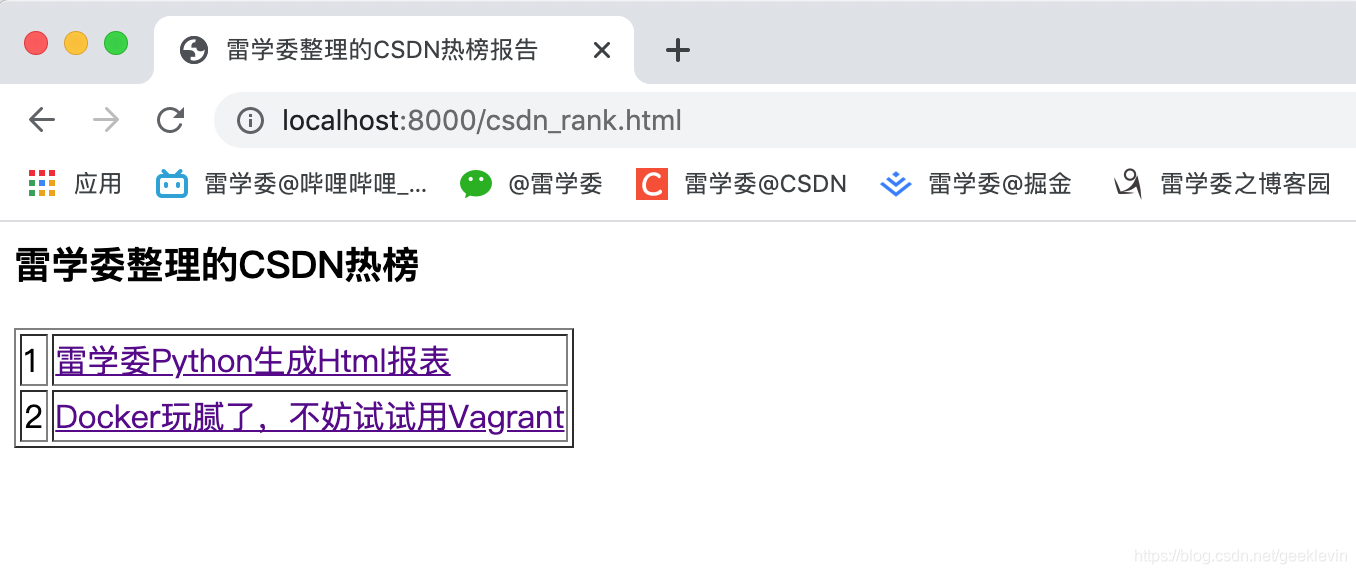
上的代码生成一个html网页,并保存到path变量指定路径。
- 准备一个二元组的数组
- 传入generate_html函数,这个函数构建带head和body。其中body再迭代输入的数组,生成一个表格。
- 将表格内容输出写入到文件中
效果如下:
第二步改造之前的爬虫代码
也就是这篇热榜长榜单爬虫截屏的文章 里面的核心代码,下面直接改造。
'''
雷学委应对流式页面的爬虫解决秘诀
截屏的核心代码:
'''
def resolve_height(driver, pageh_factor=5):js = "return action=document.body.scrollHeight"height = 0page_height = driver.execute_script(js)ref_pageh = int(page_height * pageh_factor)step = 150 max_count = 15 count = 0 while count < max_count and height < page_height:#scroll down to page bottomfor i in range(height, ref_pageh, step):count+=1vh = islowjs='window.scrollTo(0, {})'.format(vh)print('[雷学委 Demo]exec js: %s' % slowjs)driver.execute_script(slowjs)sleep(0.3)if i >= ref_pageh- step:print('[雷学委 Demo]not fully read')breakheight = page_heightsleep(2)page_height = driver.execute_script(js)print("finish scroll")return page_height#获取窗口实际高度
page_height = resolve_height(driver)
print("[雷学委 Demo]page height : %s"%page_height)
sleep(5)
driver.execute_script('document.documentElement.scrollTop=0')
sleep(1)
driver.save_screenshot(img_path)
page_height = driver.execute_script('return document.documentElement.scrollHeight') # 页面高度
print("get accurate height : %s" % page_height)#上面的代码跟源自前一篇#引用报表功能
from report import lei_report#拉到页面底部
driver.execute_script(f'document.documentElement.scrollTop={page_height};')
sleep(1)
driver.save_screenshot(f'./leixuewei_rank_end.png')
blogs = driver.find_elements_by_xpath("//div[@class='hosetitem-title']/a")#生成数组
articles = []
for blog in blogs:link = blog.get_attribute("href")title = blog.textarticles.append((link,title))print('get %s articles' % len(articles))
print('articles : %s ' % str(articles))#给定路径,生成html报告
path = "./leixuewei_csdn_rank.html"
lei_report(articles, path)
print("保存热榜到路径:%s" %path)"""LeiXueWei Demo代码,白嫖这么多了,关注三连支持一下吧!"""
代码解析
前篇的流式处理的爬虫代码删去了截屏合并代码段。
然后,重点来了。如下步骤:
- 爬虫直接拉到底部,获取链接,生成数组
- 接着截图页面尾部,以后可以留作纪念
- 导入调用lei_report 函数,生成页面
比较简单的,不一行一行解读了。
效果如下:
报表太长了截图截了个头尾,看看。
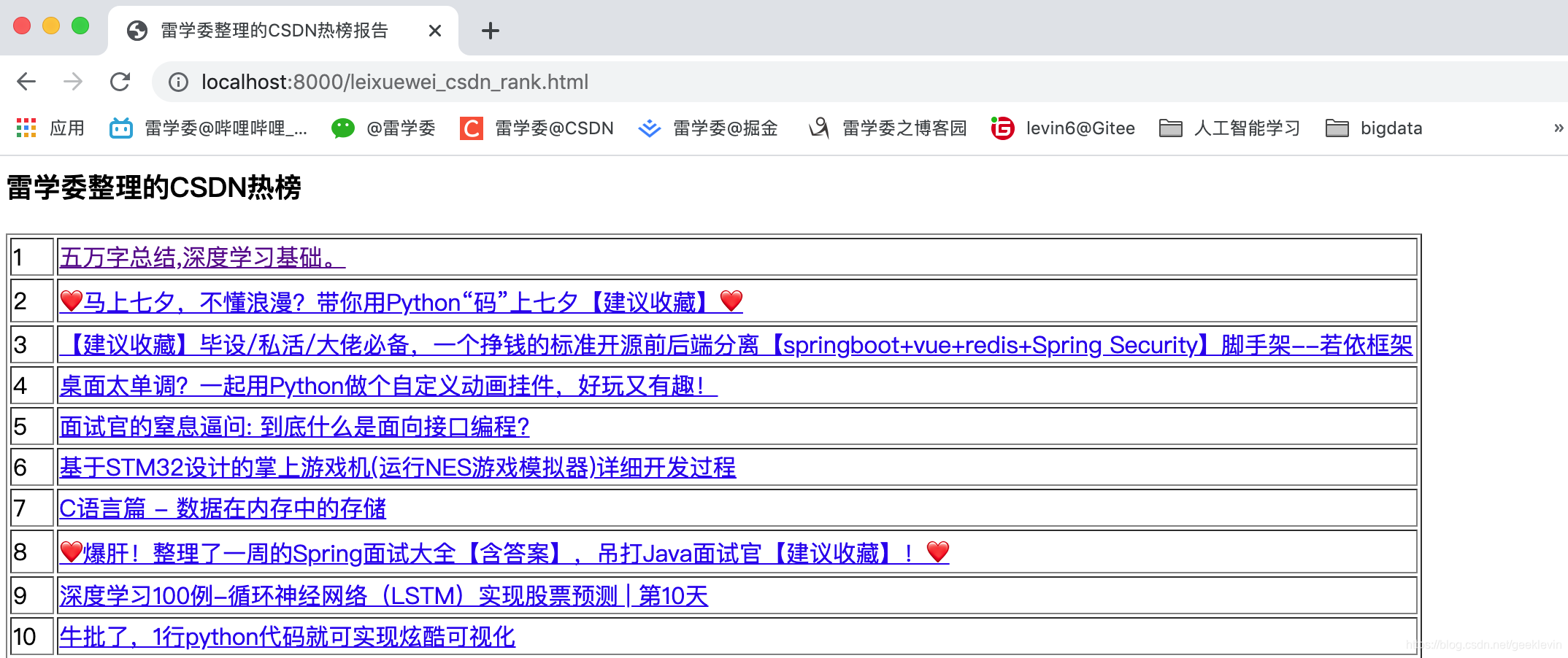
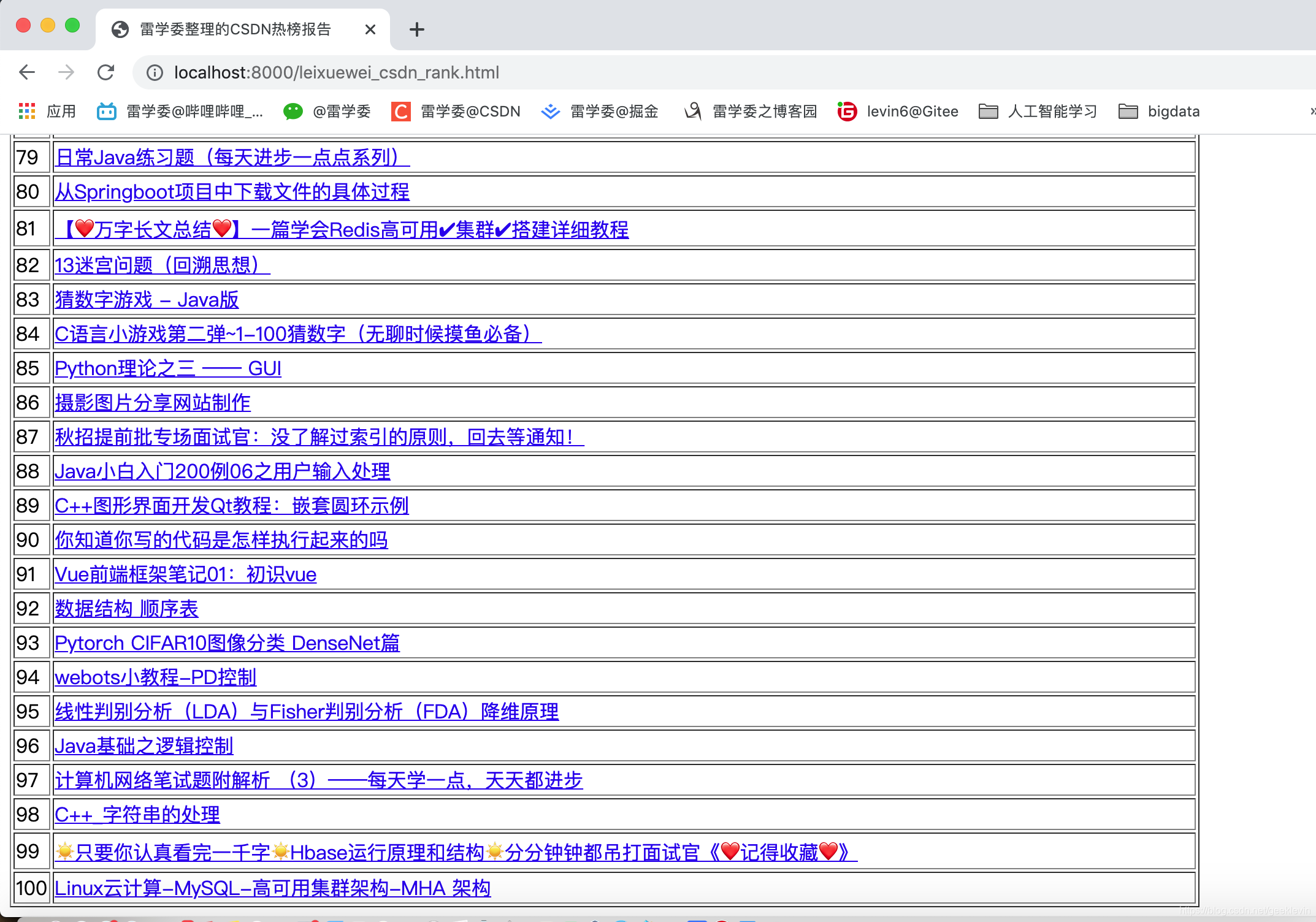
总结:这篇多看看
本文仅作展示目的,对于演示网站有任何异议,请告知修改。
最后使用爬虫必须谨慎,不要当做儿戏去爬机构网站。你学习也不能拿严肃的网络来刷,这个行为会让你吃上LAO饭!
对了,学委还有这个可以关注长期阅读 =>雷学委趣味编程故事汇编
或者=> 雷学委NodeJS系列
持续学习持续开发,我是雷学委!
编程很有趣,关键是把技术搞透彻讲明白。
创作不易,请多多支持,点赞收藏支持学委吧!
这篇关于❤️爬虫截热榜长屏不方便阅读!推荐dominate直接生成报告❤️的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






