本文主要是介绍Python将PDF按页拆分为图片,并OCR识别为文本【windows,主要使用模块/工具包括wand、pytesseract、PIL等,附下载及安装】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python将PDF按页拆分为图片,并OCR识别为文本
- 下载所需安装包并完成安装
- 1、下载并安装tesseract-ocr
- 2、下载并安装imagemagic
- 3、下载并安装Ghostscript
- PFD转成jpeg图片,并识别成文本
下载所需安装包并完成安装
1、下载并安装tesseract-ocr
链接:https://pan.baidu.com/s/1FypYuviozcC4J0_1IR6hmQ
提取码:e28y

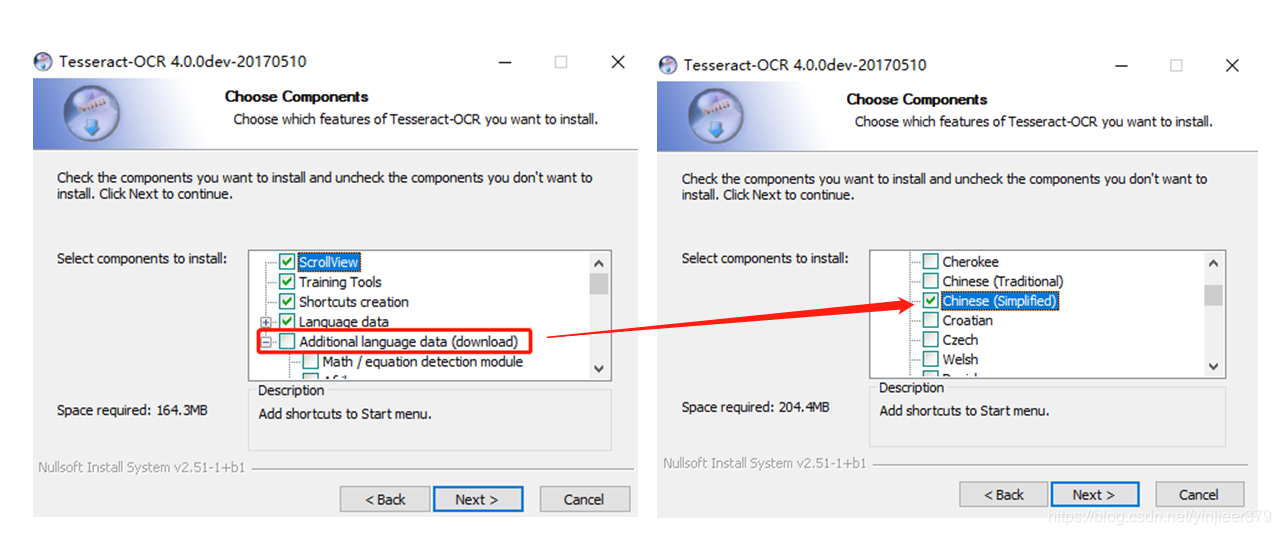
双击安装,默认下一步,并在这里选择简单中文:
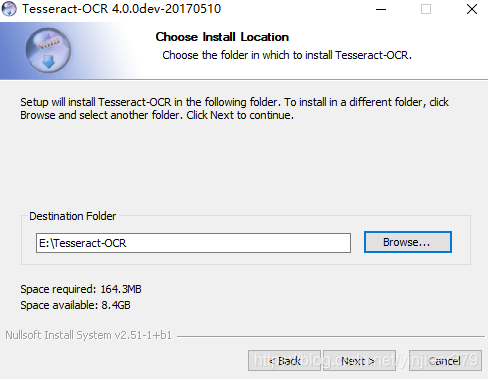
选择安装目录,并记住安装路径,因为后续安装完成之后需要设置环境变量:
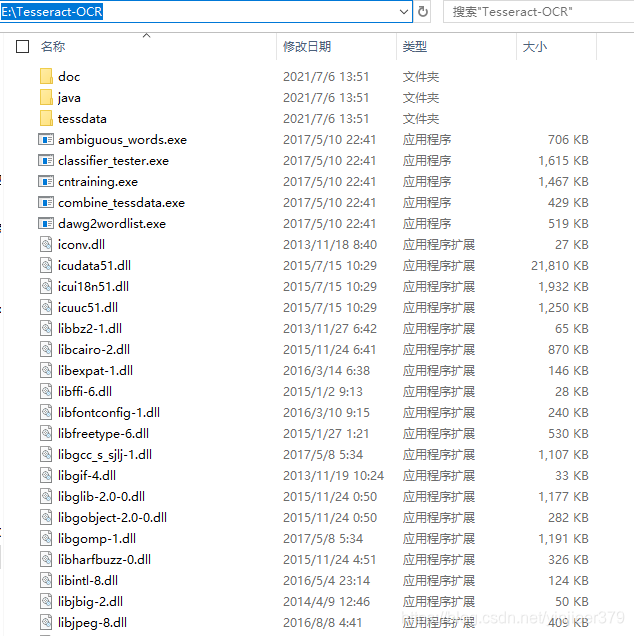
然后一直默认完成安装即可,完成后会在安装目录下看到文件夹:
设置环境变量,“我的电脑”->右键,选择“属性”–>“高级系统设置”–>“环境变量”–>“系统变量”–>找到“path”后点击编辑,然后新建,将刚刚完成的安装目录添加到“path”中:
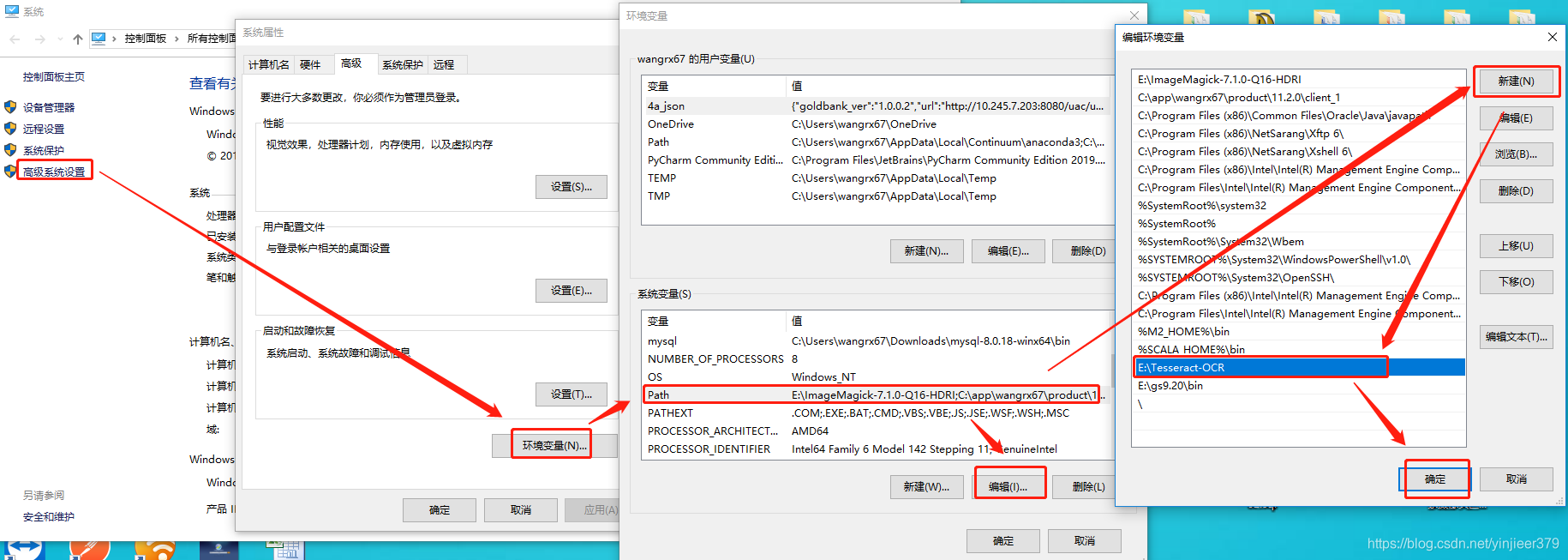
同时新增一条“系统变量”,如下:
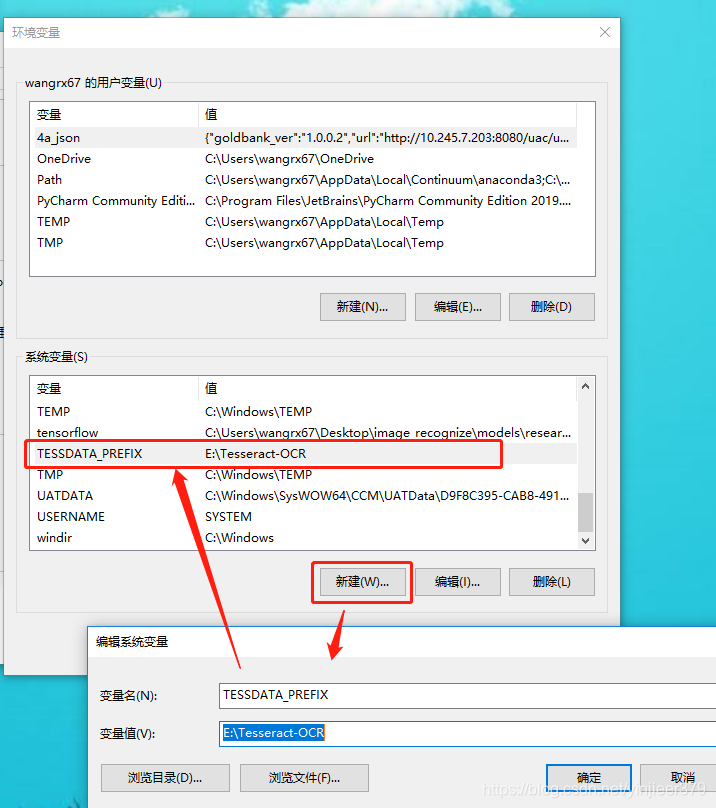
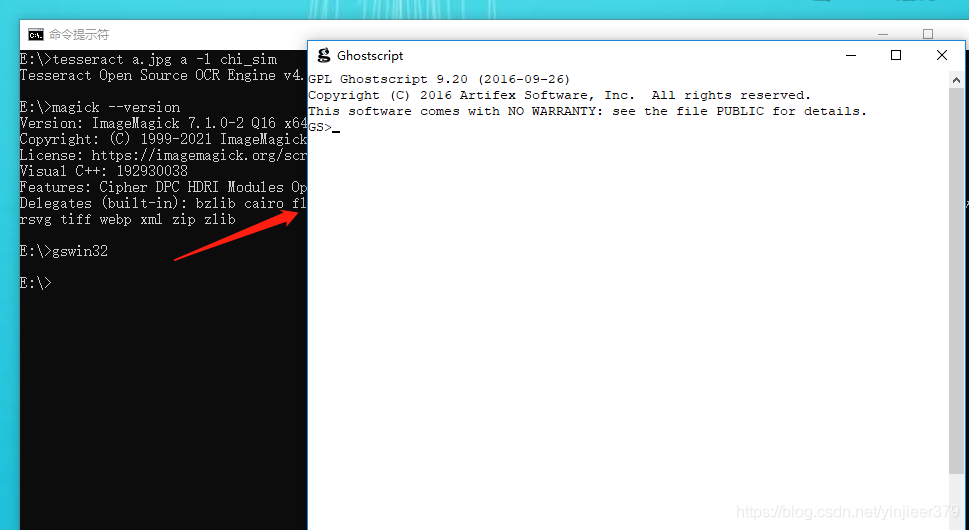
打开cmd,输入tesseract -V查看,若显示如下则表示安装成功:
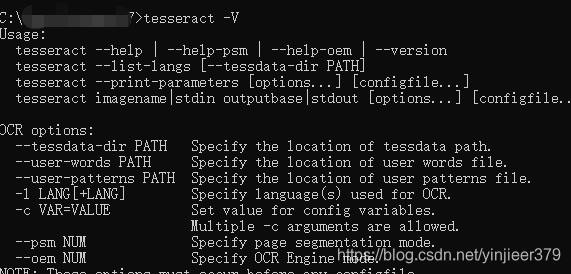
使用tesseract a.jpg a -l chi_sim测试一下识别效果:
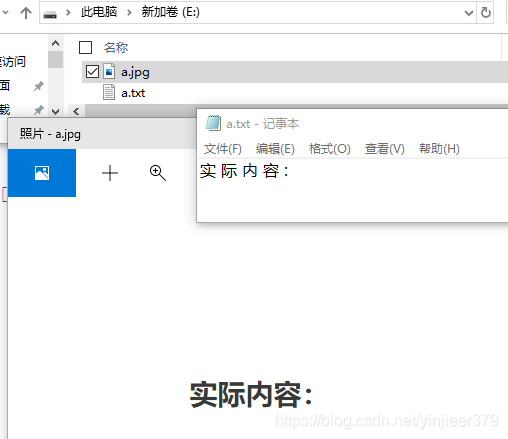
会生成一个名为a.txt的文件,里面保存有文本信息:
最后,为了在python中可以使用tesseract,需要安装pytesseract包来实现对Tesseract的调用(在命令行中使用tesseract,在python脚本中使用pytesseract)。使用 pip 安装 pytesseract; Pillow ,用于加载磁盘中的图像;pyocr,tesseractPython接口中的另一个:
pip install pillow
pip install pytesseract
pip install pyocr
示例:用python调用识别图片,有直接的函数:
text=pytesseract.image_to_string(PI.open(r'E:\a.jpg'),lang='chi_sim')
print(text)

2、下载并安装imagemagic
链接:https://pan.baidu.com/s/1monXyx3u5EH2FIeDa3waEQ
提取码:qbac

双击开始安装,点击下一步,注意在这里选择添加环境变量,否则要手动添加环境变量:
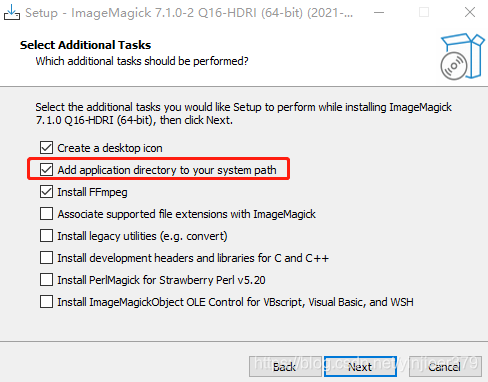
然后跟上面安装tesseract-ocr类似一直点击下一步完成安装即可(注意,大家根据具体情况可以选择安装目录):
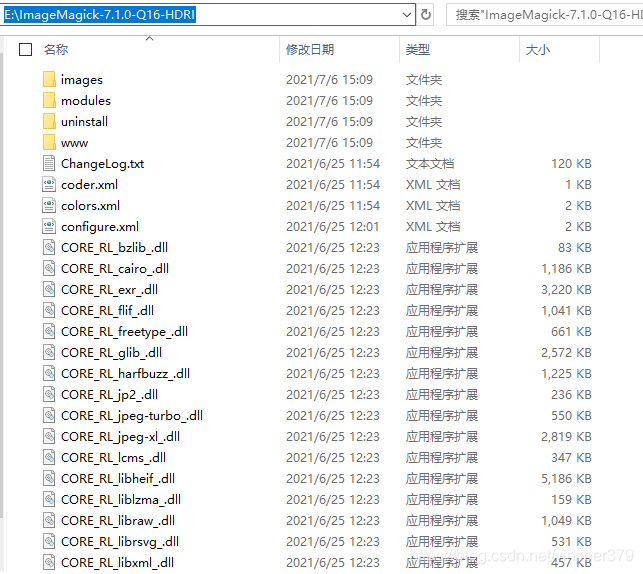
可以去环境变量中查看到安装过程中已经自动配置好了环境变量。
打开cmd,使用magick --version 查看是否安装成功:

如上所示,安装成功。
为了使python能够调用成功,这里需要在python中安装模块wand
pip install wand
3、下载并安装Ghostscript
imagemagic在调用的时候会使用到Ghostscript这个依赖,如果没有的话会报错。
链接:https://pan.baidu.com/s/1HqzgSczZsRjF7oCj7ENZvg
提取码:32ql

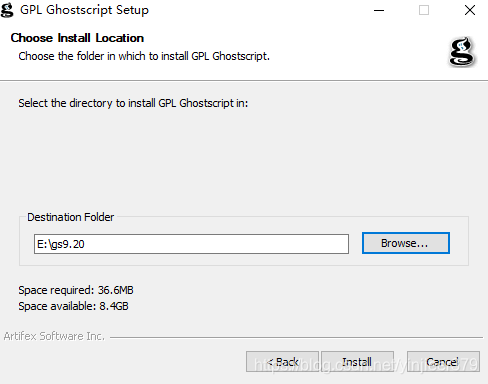
双击安装,选择安装路径:
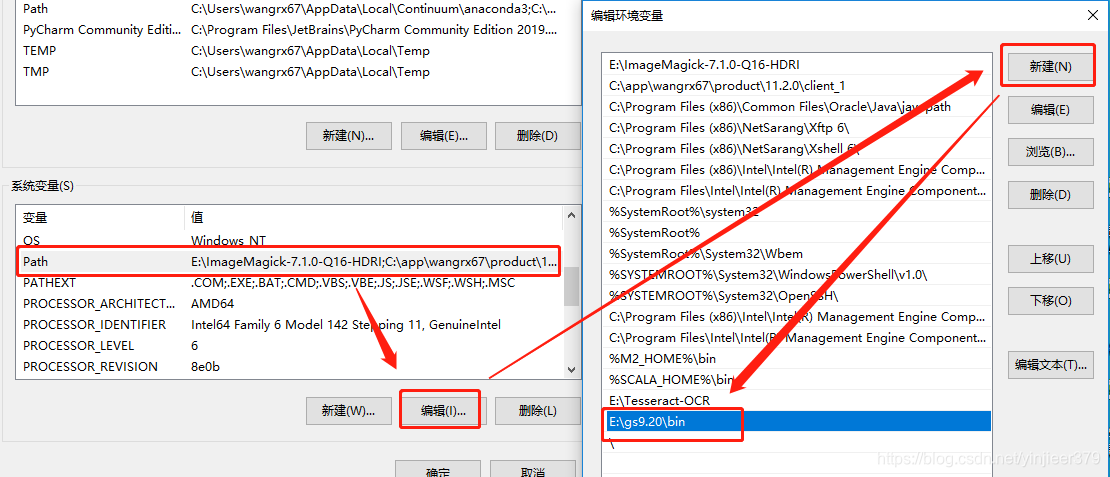
完成安装后,需要手动配置环境变量:
打开cmd,使用gswin32或者gswin64查看是否安装成功,若跳出如下右边窗口则说明安装成功:
PFD转成jpeg图片,并识别成文本
以上所需要的模块完成安装后,准备工作完成。
下面是PFD转成jpeg图片,并识别成文本的代码:
import io
from wand.image import Image #需要提前手动安装imagemagic,可从百度云下载,手动安装Ghostscript
from PIL import Image as PI
import pyocr#pip install
import pyocr.builders
import pytesseract #pip install,需要提前手动安装tesseract,可从百度云下载#重要!如果有报错tesseract环境变量的问题,说明发现两个环境变量的设置没有起作用,因此在python中可以重新设置一下
import os
#os.environ["PATH"] #查看在PATH中有没有tesseract相关路径,没有则添加,注意改为你的相应安装路径
os.environ["PATH"] += os.pathsep + 'E:\Tesseract-OCR'
#'TESSDATA_PREFIX' in os.environ #查看是否有新增TESSDATA_PREFIX的这个环境变量,没有则添加,注意改为你的相应安装路径
os.environ['TESSDATA_PREFIX']='E:\Tesseract-OCR'#设置识别识别工具
tool = pyocr.get_available_tools()[0]
#设置使用的语言,因为我们要识别的PDF是中文的,因此这里选择chi_sim
lang = tool.get_available_languages()[0]#定义列表用于存储图像与文本
req_image = []
final_text = []#采用wand将一个PDF文件转成jpeg文件,并将PDF中所有的独立页面都转成了独立的二进制图像对象
image_pdf = Image(filename=r"C:\Users\wangrx67\Desktop\审计项目\上下家合同样例1\下家合同.pdf",resolution=300)
with image_pdf.convert('jpeg') as converted:image_jpeg=image_pdf.convert('jpeg')#converted.save(filename='converted.jpeg') #按页进行拆分,并将每一页保存为jpeg格式的图片#遍历这个大对象,并把它们加入到req_image序列中去。
for img in image_jpeg.sequence:img_page = Image(image=img)req_image.append(img_page.make_blob('jpeg'))#在图像对象req_image序列上运行OCR进行识别,按页面变成一个列表
for img in req_image:txt = tool.image_to_string(PI.open(io.BytesIO(img)),lang=lang,builder=pyocr.builders.TextBuilder())final_text.append(txt)#可以将按页的识别列表整合成一个字符串
out_text=''
for i in final_text:out_text += i
out_text=out_text.replace("\n","") # 因为我识别的文本中有很多空格,所以我将这些特殊“/n”字符都删除
print(out_text) #out_text即为识别出的字符串文本
最终输出如下所示:

当然,如果你需要将pdf拆分转存为图片,或者按页识别等等,可以对代码稍微做修改实现。
参考
https://www.jb51.net/article/89955.htm
这篇关于Python将PDF按页拆分为图片,并OCR识别为文本【windows,主要使用模块/工具包括wand、pytesseract、PIL等,附下载及安装】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




