本文主要是介绍Netapp数据恢复—Netapp存储误删除lun的数据恢复过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Netapp存储数据恢复环境:
北京某公司一台netAPP存储,72块SAS硬盘划分了若干个lun。
Netapp存储故障:
工作人员误操作删除了12个lun。
Netapp存储数据恢复过程:
1、将故障存储中所有磁盘编号后取出,以只读方式做全盘镜像后按照编号还原到原存储中,后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
2、基于镜像文件分析底层数据,找到盘头位置的超级块。北亚企安数据恢复工程师通过分析超级块信息获取磁盘组的起始块信息、磁盘组名称、逻辑组起始块号、raid编号等信息。
分析超级块: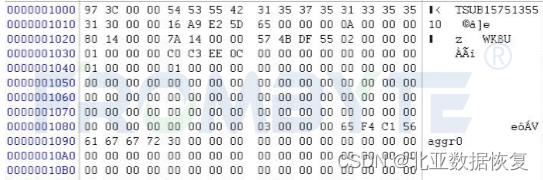
通过分析得知每个数据块占8个扇区,数据块后附加64字节数据块描述信息。根据这些信息判断出作为校验盘的磁盘,在后续的数据恢复过程中需要踢出这些磁盘。
校验块描述信息样例:
3、依据每块磁盘8号扇区的磁盘信息以及磁盘末尾的RAID盘序表确定盘序。首先确定各个磁盘所属aggr组,然后再判断组内盘序。数据指针跳转时不考虑校验盘,只需要确定数据盘的盘序即可。
分析盘序表:
Netapp的节点分布在数量众多的数据块内,在数据块内又被统一组织为节点组。每个节点组的前64字节记录一些系统数据,之后用192字节为一项,记录各个文件节点。节点根据用户级别可分为两类:系统文件节点(MBFP)和用户文件节点(MBFI),数据恢复一般只需要MBFI节点组。
服务器节点样例图: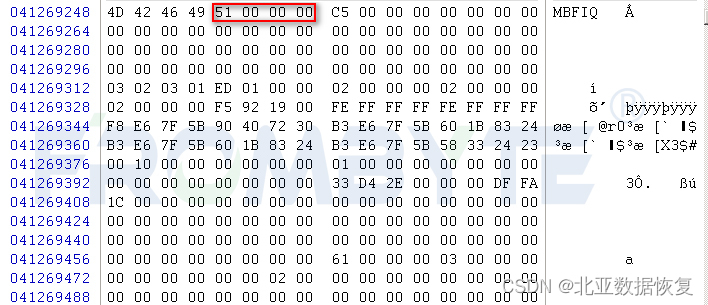
头部信息64字节,此头部为数据文件的节点文件块头部,大小为64字节。
根据更新序列值获取到最新节点。解析节点中节点类型、逻辑块号、文件数量、文件大小、所占块数量和数据指针。
获取节点在节点文件中的逻辑块号,从0开始计数。
4、获取目录项,根据其节点编号找到对应节点。
获取服务器内对应节点截图:
5、通过北亚企安自主开发的程序提取服务器数据。
a、扫描节点信息。
扫描服务器节点信息:
节点扫描类: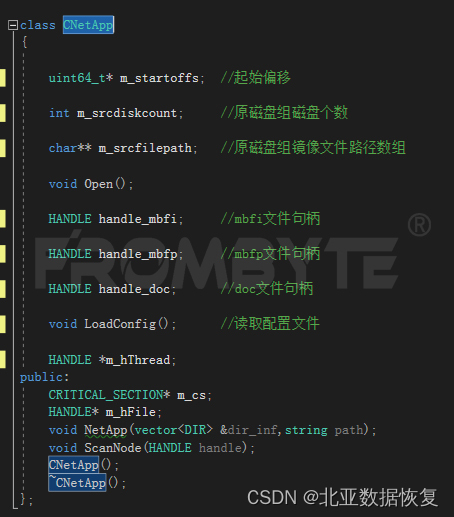
节点扫描程序完整流程: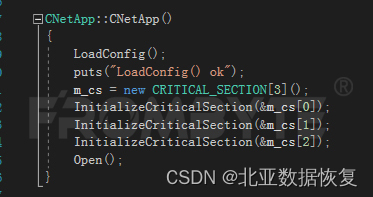
循环扫描完毕之后将所有扫描到的MBFP、MBFI和DOC数据块分别写入到三个文件内,用于后续处理。
b、将节点信息导入到数据库。
此模块主要负责将ScanNode扫描到的MBFI和MBFP、Dir存入数据库以备后续使用。
MBFI导入数据库整体流程: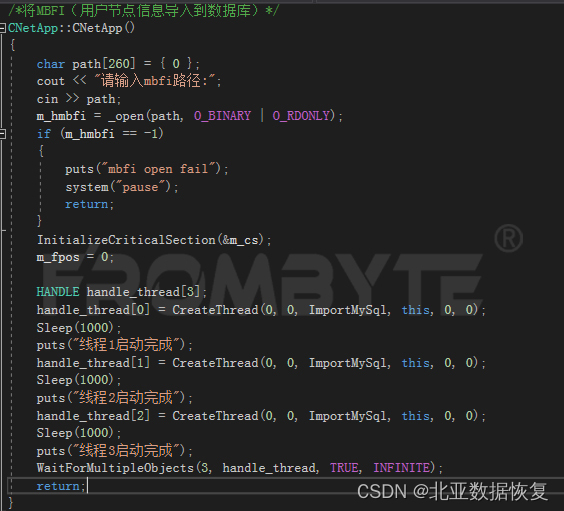
函数执行完毕后查看数据库,得到如下信息:
节点导入信息: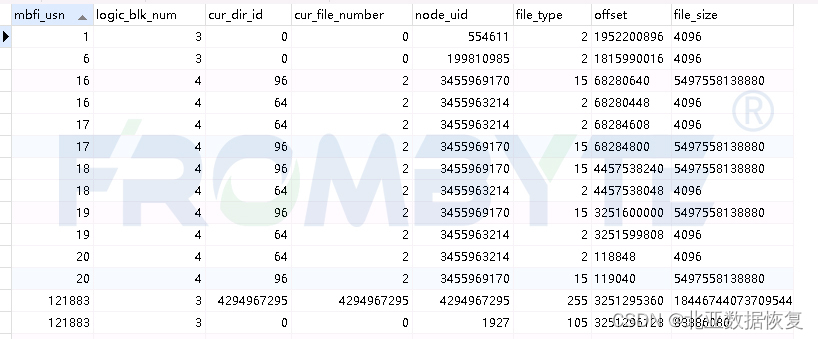
Netapp在更改inode节点时不会直接覆盖而是重新分配inode进行写入。单个文件的节点node_uid是唯一的不会改变,mbfi_usn会随着节点的变化而增大(正常情况下提取某个文件时使用usn最大的节点)。一般情况下存储划分出的单个节点会作为LUN映射到服务器使用,根据file_size可以确定这个文件的大小,按照文件大小分组后再选取usn最大值的节点,跳转到MBFI文件的offset值偏移位置,取出节点。
节点样例图示: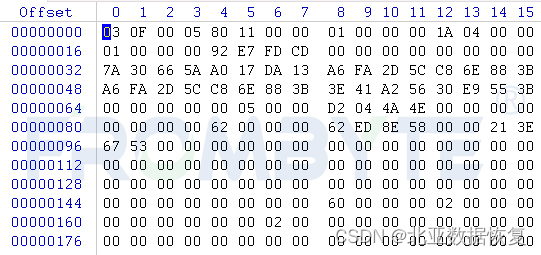
c、提取文件。
在获取到要提取的文件的Node之后,开始提取块设备文件。
提取块设备文件:
初始化完毕后,开始提取文件的各级MAP,在本次提取过程中文件大小均大于1T,MAP层级为4,所以需要提取4次。第一级MAP默认只占用1个块,所以在程序内直接提取,后三级MAP在GetAllMap函数内进行提取。通过块号计算数据块位置时,由于NetApp使用JBOD组织LVM,直接用块号除以每块磁盘上的块数可得到当前块所在的磁盘序号(计算机整数除法,丢弃小数部分);再使用块号取余块数,得到数据块在此磁盘上的物理块号,物理块号乘以块大小,得到数据块偏移位置。
6、解析块设备文件系统。
故障存储块设备中5T大小的lun使用的是aix小机的jfs2文件系统。因此要解析jfs2文件系统,提取里面的数据库备份文件。
a、找到记录lvm描述信息的扇区,解析pv大小和pv序号;找到vg描述区,解析lv数和pv数;找到pv描述区,解析pp序号和pp数。
解析文件系统块信息:
LV类型及LV挂载信息区域: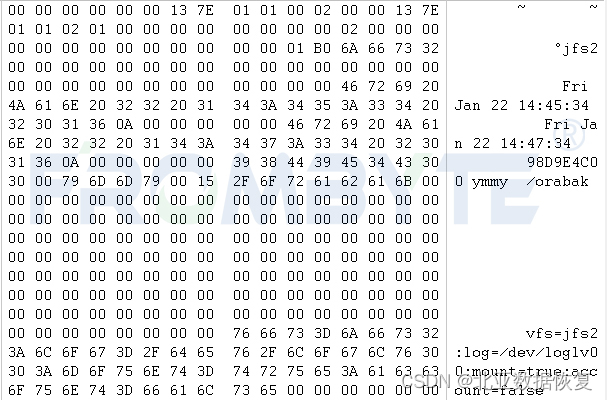
b、解析8个1T大小lun组成的oralce ASM文件系统,提取其中的数据库文件。
添加8个lT的lun: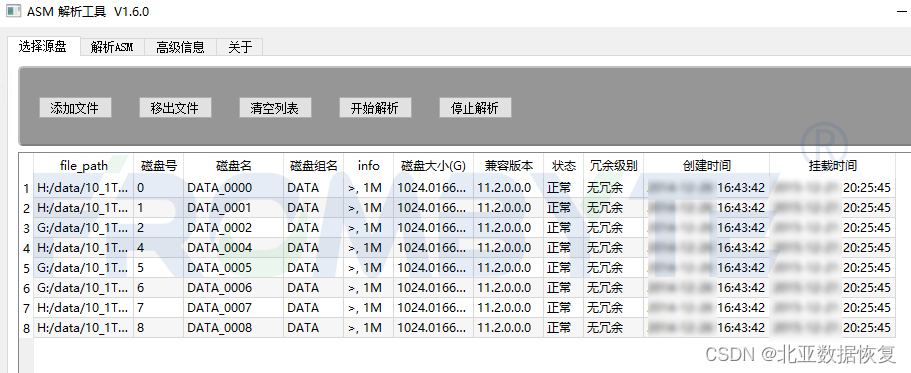
解析asm文件系统,提取出数据库文件: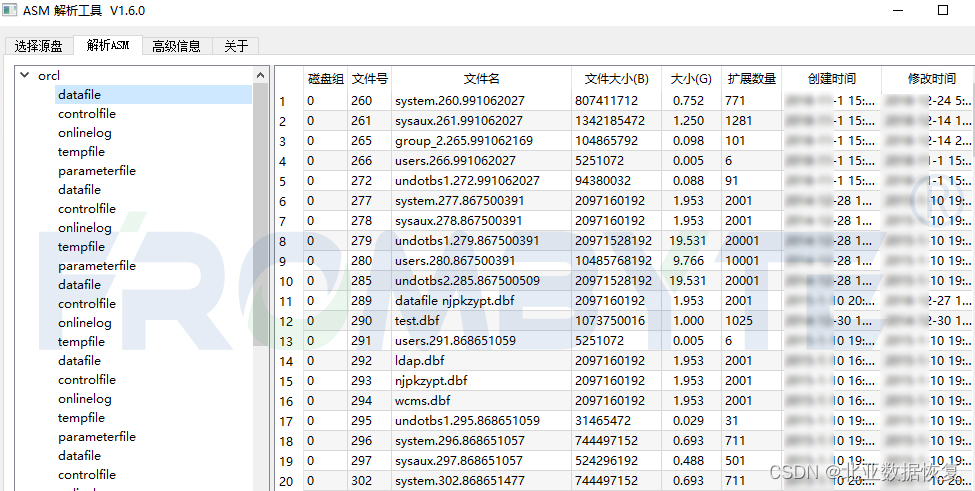
7、对提出的数据进行检测,没有发现异常。交由用户方进行验证,经过用户方相关工作人员的共同验证,确认恢复出来的数据完整有效。本次数据恢复工作完成。
这篇关于Netapp数据恢复—Netapp存储误删除lun的数据恢复过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






