本文主要是介绍Caffe——hdf5文件的生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、图片标签工具
- (1)labelimg安装:
- (2)labelme安装:
- 二、hdf5文件的生成
- (1)预准备
- (2)hdf5制作代码实现
- (3)知识点补充
- (4)最后生成效果如下
一、图片标签工具
关键点坐标获取:
尝试一:labelimg(电脑之前把python卸载了,现在需重新安装)
尝试二:labelme
(1)labelimg安装:
方法1:(失败)
1步骤一:
按照下列参考网址进行安装:
https://jingyan.baidu.com/article/5225f26ba428fee6fa090829.html
2步骤二
安装完成后执行labelimg仍然报错如下,需安装PyQt4包

2步骤三
打开镜像库:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
下载对应版本的whl文件,cmd进入下载目录,pip进行安装。
安装完成后可以在D:\Anaconda3\Lib\site-packages进行查看,可以将whl文件删除。
4步骤四
再次输入labelimg,仍然报错

方法2:(重新选择一种方式,安装成功)
下载windows版本的labelimg压缩包:
https://github.com/tzutalin/labelImg/releases
下载完成后,直接双击exe文件即可使用,很方便。将路径配置环境变量,即可在终端直接打开。

(2)labelme安装:
安装时也遇到一些问题,干脆就直接用老师的例子直接生成hdf5文件,其它的先放一放
二、hdf5文件的生成
(1)预准备
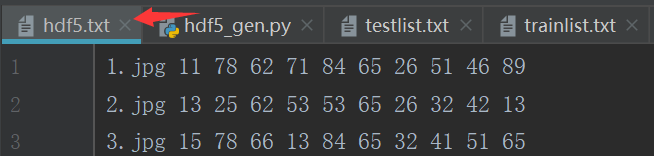
准备好图片及关键点对应的txt文件(此处的图片时人脸,关键点为鼻子、眼睛、嘴,几个关键点xy坐标)
(2)hdf5制作代码实现
import h5py
import os
import cv2
import math
import numpy as np
import random
import reroot_path = "./image"with open("./hdf5.txt", 'r') as f:lines = f.readlines() # ['1.jpg 11 78 62 71 84 65 26 51 46 89\n', '2.jpg 13 25 62 53 53 65 26 32 42 13\n', '3.jpg 15 78 66 13 84 65 32 41 51 65\n']
num = len(lines) # num表示有多少张照片
random.shuffle(lines)imgs = np.zeros([num, 3, 224, 224])
labels = np.zeros([num, 10])
for i in range(num):line = lines[i]segments = re.split('\\s+', line)[:-1] # \\s表示 空格,回车,换行等空白符, +号表示一个或多个的意思print(segments[0])img = cv2.imread(os.path.join(root_path, segments[0]))img = cv2.resize(img, (224, 224))print(img.shape)img = img.transpose(2, 0, 1) # 把224*224*3变成imgs[i, :, :, :] = img.astype(np.float32) # 变成float32for j in range(10):labels[i, j] = float(segments[j + 1]) * 224 / 256 # 原始图片就是256*256batchSize = 1 # batchsize最多8000个数据为好
batchNum = int(math.ceil(1.0 * num / batchSize)) # math.ceil向上取整,进一法
# 每一个文件构造成一个.h5的文件imgsMean = np.mean(imgs, axis=0) # imgs一共又四维,第一维是数量,axis为0也就是对每一张图片求均值
# imgs = (imgs - imgsMean)/255.0
labelsMean = np.mean(labels, axis=0) # 对每一个标签求均值
labels = (labels - labelsMean) / 10 # 减mean值,以0为中心化if os.path.exists('trainlist.txt'):os.remove('trainlist.txt')
if os.path.exists('testlist.txt'):os.remove('testlist.txt')comp_kwargs = {'compression': 'gzip', 'compression_opts': 1}
for i in range(batchNum):start = i * batchSizeend = min((i + 1) * batchSize, num)if i < batchNum - 1:filename = './h5/train{0}.h5'.format(i)else: # 在此处改训练集和测试集的尺寸filename = './h5/test{0}.h5'.format(i - batchNum + 1) # 把最后一个作为测试集print(filename)with h5py.File(filename, 'w') as f:f.create_dataset('data', data=np.array((imgs[start:end] - imgsMean) / 255.0).astype(np.float32), **comp_kwargs)f.create_dataset('label', data=np.array(labels[start:end]).astype(np.float32), **comp_kwargs)if i < batchNum - 1:with open('./h5/trainlist.txt', 'a') as f:f.write(os.path.join(os.getcwd(), 'train{0}.h5').format(i) + '\n')else:with open('./h5/testlist.txt', 'a') as f:f.write(os.path.join(os.getcwd(), 'test{0}.h5').format(i - batchNum + 1) + '\n')imgsMean = np.mean(imgsMean, axis=(1, 2))
with open('mean.txt', 'w') as f:f.write(str(imgsMean[0]) + '\n' + str(imgsMean[1]) + '\n' + str(imgsMean[2]))
(3)知识点补充
# 补充1
import re
line = '\n'
print(re.split('\\s+', line)) # ['', '']
line = '1.jpg 11 78 62 71 84 65 26 51 46 89\n'
print(re.split('\\s+', line)) # ['1.jpg', '11', '78', '62', '71', '84', '65', '26', '51', '46', '89', '']
# \\s表示 空格,回车,换行等空白符, +号表示一个或多个的意思,所以# 补充2
*args 是可变参数, args 接收的是一个 tuple;
**kw 是关键字参数, kw 接收的是一个 dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入: func(1, 2, 3),又可以先组装 list 或 tuple,再通过*args 传入:
func(*(1, 2, 3));
关键字参数既可以直接传入: func(a=1, b=2),又可以先组装 dict,再通过**kw 传入: func
(**{'a': 1, 'b': 2})。
(4)最后生成效果如下
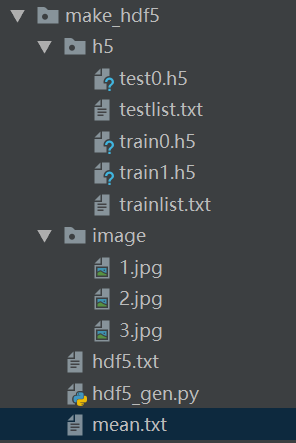
trianlist.txt、testlist里面存放的是h5文件所在的地址,在下图中红色箭头位置替换掉train.txt即可使用

这篇关于Caffe——hdf5文件的生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



