本文主要是介绍Word2vec+textrank---抽取式摘要生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原项目地址:
https://github.com/ztz818/Automatic-generation-of-text-summaries
相关知识介绍:
Word2Vec理论知识:https://blog.csdn.net/Pit3369/article/details/96482304
中文文本关键词抽取的三种方法(TF-IDF、TextRank、word2vec):
https://blog.csdn.net/Pit3369/article/details/95594728
调用summarize(text, n)返回Top N个摘要
-
tokens = cut_sentences(text)按照。!?切分句子,返回给
tokens[[句子1],[句子2]] -
对句子
tokens分词、通用词,返回列表sents:[[句子1分词结果],[句子2分词结果]],分词结果空格隔开 -
sents = filter_model(sents)遍历列表,去除word2vec词向量里未出现的词。
-
graph = create_graph(sents)传入句子列表,返回句子间相似度的图board[n*n],句子个数为n,图元素为i、j句子的相似值
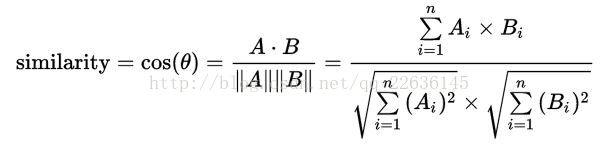
-
循环i、j:
board[i][j] = compute_similarity_by_avg(word_sent[i], word_sent[j])在
compute_similarity_by_avg(sents_1, sents_2)中,把句子中各个词词向量相加,除以句子长度作为句子平均得分,用来计算两个句子的相似度,返回给create_graph -
用句子i、j的
平均词向量进行相似度计算,相似值存储在board[i][j],返回给相似度图矩阵graph[][]
-
-
scores = weight_sentences_rank(graph)
输入相似度图矩阵graph[n*n],返回句子分数数组:scores[i],句子i的分值,初始值为0.5while循环迭代直至句子i分数变化稳定在0.0001:
-
scores[i] = calculate_score(weight_graph, scores, i)计算句子在图中分数,返回句子i的分数。参数j遍历所有句子:
- 计算分子:
fraction = weight_graph[j][i] * scores[j] - 计算分母:
denominator += weight_graph[j][k],参数k遍历句子j、k是否关联 - 分数累加:
added_score += fraction / denominator - 根据PageRank算法中PR值的计算方法,算出最终的分数,并返回:
weighted_score = (1 - d) + d * added_score
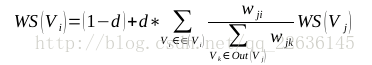
- 计算分子:
-
-
sent_selected = nlargest(n, zip(scores, count()))选取句子分数scores[],Top n的句子,作为摘要。
相似值计算:
使用的计算句子相似度的方式如下:
如计算句子A=[‘word’,‘you’,‘me’],与句子B=[‘sentence’,‘google’,‘python’]计算相似性,从word2vec模型中分别得到A中三个单词的词向量v1,v2,v3取其平均值Va(avg)=(v1+v2+v3)/3。对句子B做同样的处理得到Vb(avg),然后计算Va(avg)与Vb(avg)连个向量的夹角余弦值,Cosine Similarity视为句子A与B的相似度
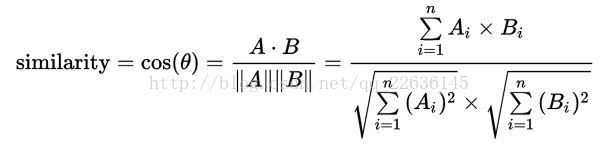
def cut_sentences(sentence):puns = frozenset(u'。!?')#分隔句子tmp = []for ch in sentence:tmp.append(ch)if puns.__contains__(ch):yield ''.join(tmp)tmp = []yield ''.join(tmp)# 句子中的stopwords
def create_stopwords():stop_list = [line.strip() for line in open("G:\1graduate\news_stopwords.txt", 'r', encoding='utf-8').readlines()]return stop_listdef two_sentences_similarity(sents_1, sents_2):'''计算两个句子的相似性:param sents_1::param sents_2::return:'''counter = 0for sent in sents_1:if sent in sents_2:counter += 1return counter / (math.log(len(sents_1) + len(sents_2)))def create_graph(word_sent):"""传入句子链表 返回句子之间相似度的图:param word_sent::return:"""num = len(word_sent)print("句子数量:",num)board = [[0.0 for _ in range(num)] for _ in range(num)]#num*numprint("board大小:",len(board),len(board[0]))"""词向量平均值作为计算句子i,j相似度的依据,保存到数组product(A,B)函数,返回A和B中的元素组成的笛卡尔积的元组"""for i, j in product(range(num), repeat=2):if i != j:board[i][j] = compute_similarity_by_avg(word_sent[i], word_sent[j])return boarddef cosine_similarity(vec1, vec2):'''计算两个向量之间的余弦相似度:param vec1::param vec2::return:(XY对应元素相乘之和)/((X元素平方和开根号)+(Y元素平方和开根号))'''tx = np.array(vec1)ty = np.array(vec2)cos1 = np.sum(tx * ty)cos21 = np.sqrt(sum(tx ** 2))cos22 = np.sqrt(sum(ty ** 2))cosine_value = cos1 / float(cos21 * cos22)return cosine_valuedef compute_similarity_by_avg(sents_1, sents_2):'''对两个句子求平均词向量:param sents_1::param sents_2::return:'''# print("计算句子相似度:",sents_1, sents_2)if len(sents_1) == 0 or len(sents_2) == 0:return 0.0"""句子中各个词向量相加,再平均,作为相似度计算依据if判断,避免了for循环vec1作为空值的异常"""if sents_1[0] in model:vec1 = model[sents_1[0]]else:vec1=model['中国']for word1 in sents_1[1:]:if word1 in model:vec1 = vec1 + model[word1]else:vec1 = vec1 + model['中国']if sents_2[0] in model:vec2 = model[sents_2[0]]else:vec2=model['中国']for word2 in sents_2[1:]:if word2 in model: vec2 = vec2 + model[word2]else:vec2 = vec2 + model['中国']# 词向量元素均除以句子长度similarity = cosine_similarity(vec1 / len(sents_1), vec2 / len(sents_2))return similaritydef calculate_score(weight_graph, scores, i):"""计算句子在图中的分数:param weight_graph::param scores::param i::return:"""length = len(weight_graph)d = 0.85added_score = 0.0for j in range(length):fraction = 0.0denominator = 0.0# 计算分子,第j个句子的词语ifraction = weight_graph[j][i] * scores[j]# 计算分母for k in range(length):denominator += weight_graph[j][k]if denominator == 0:denominator = 1added_score += fraction / denominator# 根据PageRank算法中PR值的计算方法,算出最终的分数weighted_score = (1 - d) + d * added_scorereturn weighted_scoredef weight_sentences_rank(weight_graph):'''输入相似度的图(矩阵)返回各个句子的分数:param weight_graph::return:'''# 初始分数设置为0.5scores = [0.5 for _ in range(len(weight_graph))] # 根据句子数量建立的矩阵,存储每个句子的得分old_scores = [0.0 for _ in range(len(weight_graph))]print("scores矩阵:",len(scores))# 开始迭代# 判断前后分数有无变化while different(scores, old_scores):for i in range(len(weight_graph)):old_scores[i] = scores[i]for i in range(len(weight_graph)):# 句子序号i,计算每个句子的词向量得分scores[i] = calculate_score(weight_graph, scores, i)return scoresdef different(scores, old_scores):'''判断前后分数有无变化:param scores::param old_scores::return:'''flag = Falsefor i in range(len(scores)):if math.fabs(scores[i] - old_scores[i]) >= 0.0001:flag = Truebreakreturn flagdef filter_symbols(sents):stopwords = create_stopwords() + ['。', ' ', '.']_sents = []for sentence in sents:for word in sentence:if word in stopwords:sentence.remove(word)if sentence:_sents.append(sentence)return _sentsdef filter_model(sents):_sents = []for sentence in sents:for word in sentence:if word not in model:sentence.remove(word)if sentence:_sents.append(sentence)else:print("移除句子",sentence)return _sentsdef summarize(text, n):# 按照。!?分句tokens = cut_sentences(text)sentences = []sents = []for sent in tokens:sentences.append(sent)sents.append([word for word in jieba.cut(sent) if word])# 按句分词,得到列表套列表,1句子,2按句分词print(len(sents))# print((sents))# sents = filter_symbols(sents)# 移除模型中没有的词sents = filter_model(sents)print("过滤模型后句子数量",len(sents))graph = create_graph(sents)print("词向量图矩阵建立完毕~")print("词向量图矩阵:",len(graph))# 句子个数,每行元素为该句子中词的词向量scores = weight_sentences_rank(graph)sent_selected = nlargest(n, zip(scores, count()))sent_index = []print("sent_selected=",(sent_selected))# 句子分数,句子编号for i in range(n):
# sent_index.append(sent_selected[i][1])sent_index.append(sent_selected[i][1])return [sentences[i] for i in sent_index]这篇关于Word2vec+textrank---抽取式摘要生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



