本文主要是介绍参照有赞TMC框架原理简单实现多级缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我叫大鸡腿,大家可以关注下我,会持续更新技术文章还有人生感悟,感谢~

文章目录
- 项目场景:
- 解决方案:
- 个人简单实现相关原理
- 本地变量
- 获取本地缓存的数据
- 数据一致性问题
- 设置缓存的值
- 删除缓存
- 统一获取缓存的方法
- 重点
- 优化
- 所有代码
项目场景:
有位同事因为缓存被后台删除,导致一堆高并发请求直接怼到DB上,导致数据库cpu 100%
解决方案:
- 处理缓存击穿问题:像布隆过滤器,或者说提前设置热点key
- 就是热点key检测,这里谈到了有赞TMC框架多级缓存以及它的热点key的发现
个人简单实现相关原理
本地变量
像热点key储存,本地缓存以及相关参数设置设置。
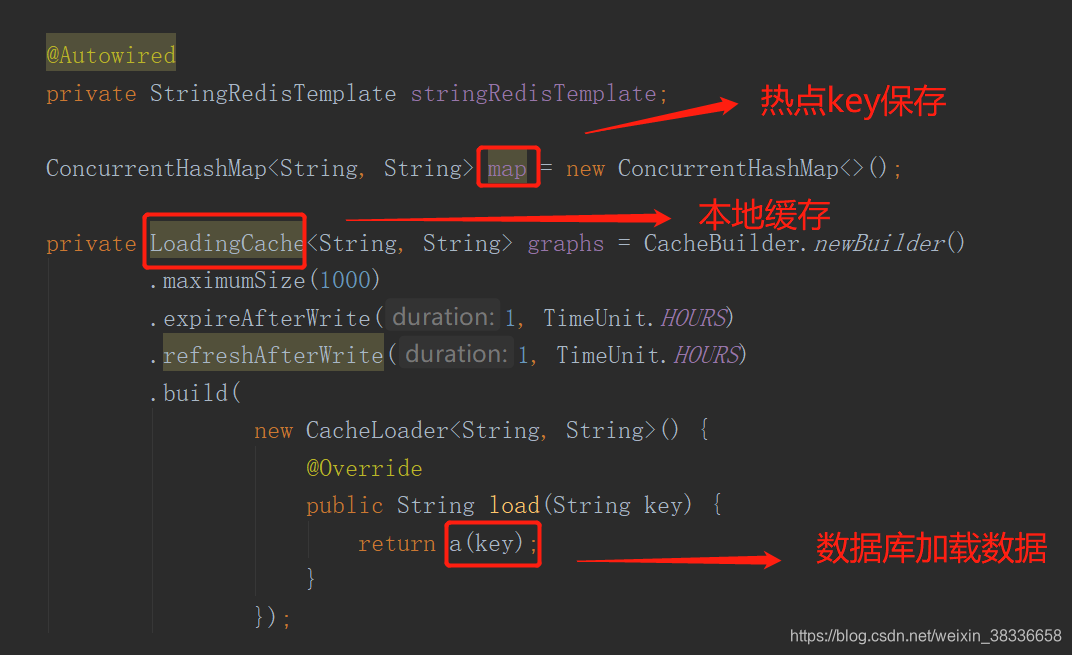
获取本地缓存的数据
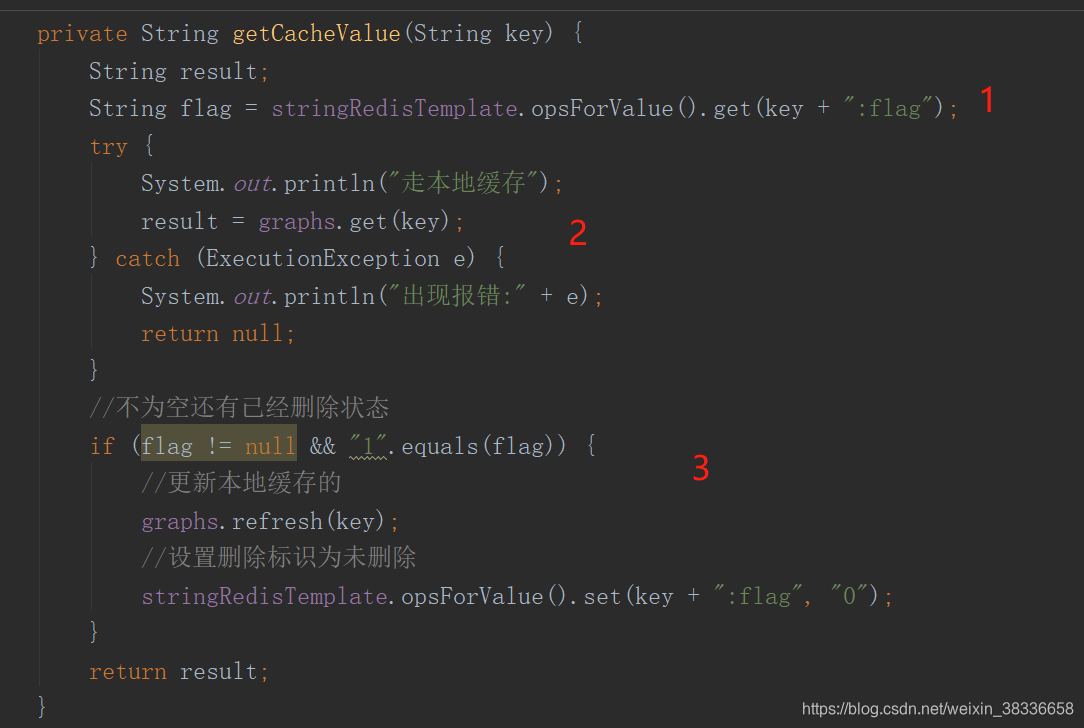
解释:
1.由于是分布式环境,所以先查询下这个key有没有被删除过
2.直接走本地缓存
3.如果是后台数据被修改,redis这个标识被修改到了,我们需要重新加载数据库的数据更新到本地缓存中,以及set到redis中
数据一致性问题
就是redis缓存跟本地缓存一致性问题,我的想法是惰性就行更新,如果有人去读取,先返回本地缓存的旧数据,后面再进行更新,也就是实现最终一致性问题。
存在问题
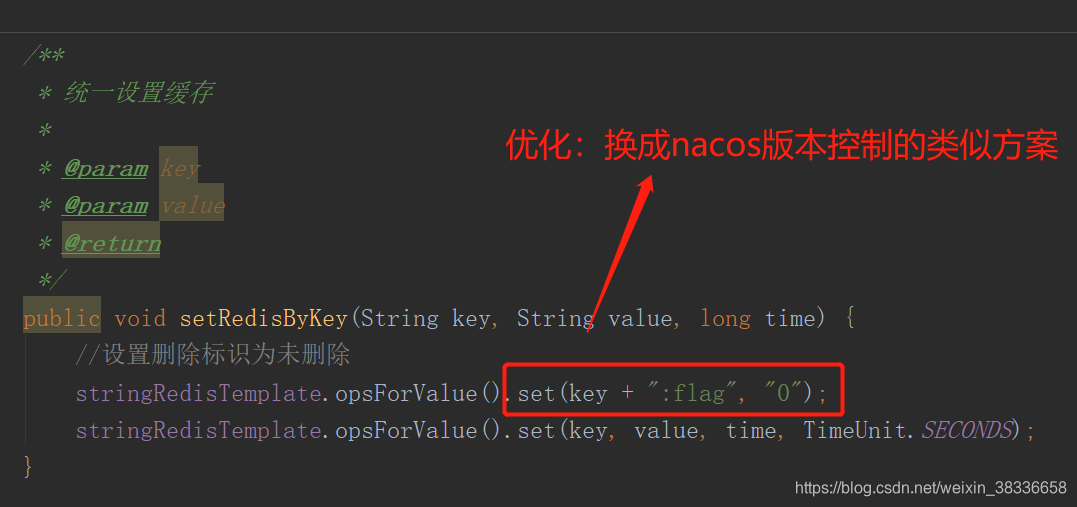
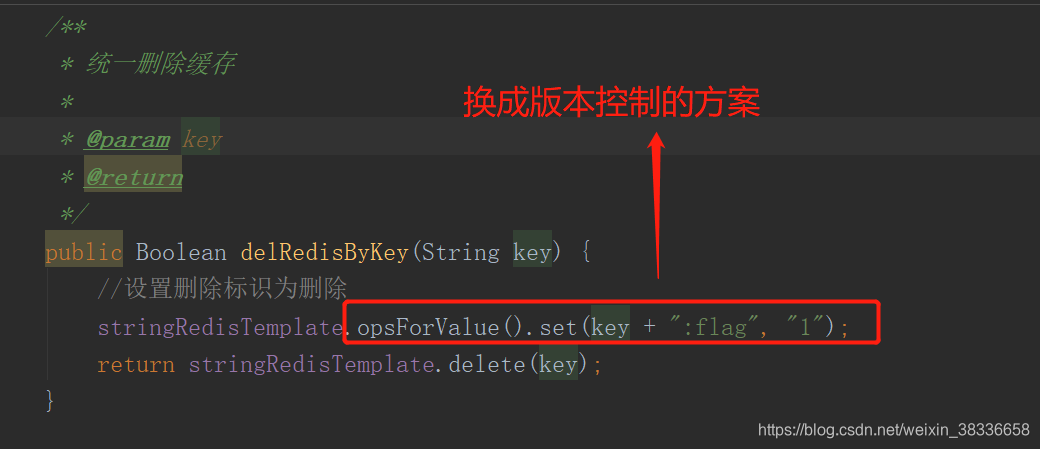
就是这里的flag在更新之后会变成0,我这里的的优化方案是:采用nacos的版本控制,redis有一份版本,本地也有一份版本,如果说redis上的版本跟本地缓存的版本有所不一样,那么就进行修改本地缓存,以及将最新的版本更新到本地缓存中。
这样的话就不会导致说一台机器把redis设置为0,另一台本地缓存就不会变了。
优化方案
- 使用nacos版本修改的原理来控制不同机器的本地缓存更新
- 更新的时候可以加个分布式锁,获得锁才能去查数据库,防止高并发查崩数据库。其次在把这个数据塞到redis还有本地缓存中。
设置缓存的值
删除缓存
统一获取缓存的方法
/*** 统一获取缓存数据** @param key* @return*/public String getRedisByKey(String key) {//计数stringRedisTemplate.opsForValue().increment(key + ":incr", 1);//5秒过期stringRedisTemplate.expire(key + ":incr", 10, TimeUnit.SECONDS);String count = stringRedisTemplate.opsForValue().get(key + ":incr");if (count != null && Integer.valueOf(count) > 2) {if (map.get(key) != null) {System.out.println("命中热点key....");return getCacheValue(key);}//2写死,表示5秒内get超过2次,定义为热点keymap.put(key, "true");if (stringRedisTemplate.getExpire(key, TimeUnit.SECONDS) < 10) {//自动延期System.out.println("自动延期");stringRedisTemplate.expire(key, 20, TimeUnit.SECONDS);}} else {map.remove(key);String result = stringRedisTemplate.opsForValue().get(key);if (result == null) {String value = a(key);setRedisByKey(key, value, 20L);return value;}System.out.println("直接走redis");return result;}return getCacheValue(key);}
前面是进行简单的计数法来保存这个热点key,如果命中热点key直接读本地缓存,否则读redis,没有的话再去读DB。
重点
如果是热点key的话,那么就会去判断它过期时间,如果不够的话会自动给它进行续期。
优化
- 比如说热点key的统计方式,这里只是简单的redis+1,如果高级一点就是时间滑窗统计热点key
- 这里是封装redistemplate查询的方案,比较好的是有一个特有的分布式集群来收集这些redis查询,redis key过期、设置、删除操作等等,会更好。
- 在删除热点key map那里也是需要再优化的,就是如果说重新这个key在接下来的时间内不那么火热,那么剔除map对应的key。
所有代码
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;@Component
public class RedisManagement {@Autowiredprivate StringRedisTemplate stringRedisTemplate;ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();private LoadingCache<String, String> graphs = CacheBuilder.newBuilder().maximumSize(1000).expireAfterWrite(1, TimeUnit.HOURS).refreshAfterWrite(1, TimeUnit.HOURS).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) {return a(key);}});private String getCacheValue(String key) {String result;String flag = stringRedisTemplate.opsForValue().get(key + ":flag");try {System.out.println("走本地缓存");result = graphs.get(key);} catch (ExecutionException e) {System.out.println("出现报错:" + e);return null;}//不为空还有已经删除状态if (flag != null && "1".equals(flag)) {//更新本地缓存的graphs.refresh(key);//设置删除标识为未删除stringRedisTemplate.opsForValue().set(key + ":flag", "0");}return result;}/*** 统一设置缓存** @param key* @param value* @return*/public void setRedisByKey(String key, String value, long time) {//设置删除标识为未删除stringRedisTemplate.opsForValue().set(key + ":flag", "0");stringRedisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);}/*** 统一删除缓存** @param key* @return*/public Boolean delRedisByKey(String key) {//设置删除标识为删除stringRedisTemplate.opsForValue().set(key + ":flag", "1");return stringRedisTemplate.delete(key);}/*** 统一获取缓存数据** @param key* @return*/public String getRedisByKey(String key) {//计数stringRedisTemplate.opsForValue().increment(key + ":incr", 1);//5秒过期stringRedisTemplate.expire(key + ":incr", 10, TimeUnit.SECONDS);String count = stringRedisTemplate.opsForValue().get(key + ":incr");if (count != null && Integer.valueOf(count) > 2) {if (map.get(key) != null) {System.out.println("命中热点key....");return getCacheValue(key);}//2写死,表示5秒内get超过2次,定义为热点keymap.put(key, "true");if (stringRedisTemplate.getExpire(key, TimeUnit.SECONDS) < 10) {//自动延期System.out.println("自动延期");stringRedisTemplate.expire(key, 20, TimeUnit.SECONDS);}} else {map.remove(key);String result = stringRedisTemplate.opsForValue().get(key);if (result == null) {String value = a(key);setRedisByKey(key, value, 20L);return value;}System.out.println("直接走redis");return result;}return getCacheValue(key);}/*** 初始化本地缓存数据** @param key* @return*/private String a(String key) {System.out.println("查db");//执行不同逻辑if (key.startsWith("activity")) {//查数据库return "activity";} else if (key.startsWith("content")) {//查数据库return "content";} else {return "haha";}}}
这篇关于参照有赞TMC框架原理简单实现多级缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








