本文主要是介绍MySQL的in查询效率太低的解决办法之一与其它优化示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在做一个MySQL数据库的查询(查询出指定时间之后凡是上传过图片的用户所在的镇和镇的管理员名),查询语句如下:
SELECT DISTINCT user_name,town_name FROM t_farmers WHERE id IN
(SELECT DISTINCT farmer_id FROM t_farmers_images WHERE create_time>='2017-07-05')
其中farmers表有六千多记录,farmers_images表有近20万条记录,查询效率极低,此查询估计能够耗十分钟的时间,无法忍受,于是寻找解决办法,
网上有说加索引解决的,此处并未采取此方案,加索引或许确实能够解决问题,但时担心影响插入效率而且并非业务字段强相关故而暂未采取。
网上还有说把in改为exist,但是查询效率似乎并没有什么改变。通过搜阅资料得知in适合用于子表小的情况,而exist适合子表大主表小的情况,(仅代表一家之言,可能有不到之处,日后细究)。
解决方法如下:
上面的sql的执行计划如下:

可以看到为全表扫描,效率肯定会非常差;
经对数据库方面的文章参考,最终找到了一个方法,把in改为左连接右连接的方式命中索引,于是把sql语句改为如下:
SELECT DISTINCT b.user_name,b.town_name FROM (SELECT DISTINCT farmer_id FROM t_farmers_images WHERE create_time>='2017-08-18') a
LEFT JOIN t_farmers b ON a.farmer_id=b.id
查询效率瞬间提升,几乎感觉不到有什么延迟。
执行计划为:

可以看到命中b表的索引;
详细的左连接,右连接,内连接等的查询和哪种适合左边表大,哪种适合右边表大,哪种查询具体适合什么情形,请自行网上查询。
查询2月1号之后,总数之和超过300的用户:
SELECT mm.*,c.user_name,c.town_name,c.name,c.tel,c.card_id,c.onecard_id FROM (
SELECT a.farmer_id,SUM(death_number) FROM t_farmers_details a
WHERE a.date_time>='2017-02-01' GROUP BY a.farmer_id HAVING SUM(death_number)>=300 ) mm
LEFT JOIN t_farmers c ON c.id=mm.farmer_id
此外做项目时有经常需要用到多表查询的情况,全表扫描查询太慢,到现在才明白为什么两年前别人的项目中都用左连接,右连接之类的索引优先查询了,N多年后才明白别人当初的业务逻辑,还需要加把劲更加努力进步!
2017.12.07需要对已有系统进行优化,其中有一个导出Excel的功能,用户量小的时候导出功能正常,但是用户量大的时候导出特别慢,甚至网络差的时候还会出现导出失败的情况,起初以为是前端导出Excel效率低下的原因,后来经测试发现是数据库查询效率太差,
最初sql语句写法为:
SELECT a.*,(SELECT SUM(death_number) death_number FROM t_farmers_details
WHERE date_time LIKE '%2017-12%'
AND farmer_id =a.id ) harmless_quantity
FROM t_farmers a WHERE 1=1
执行计划为:
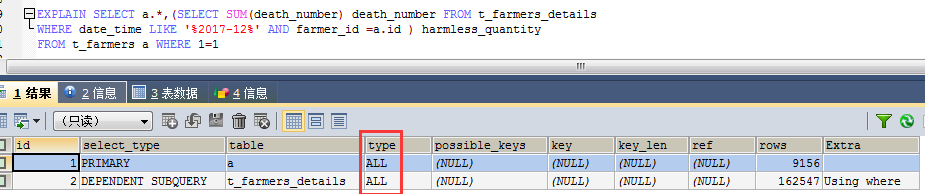
同样是全表扫描;
优化后sql语句写法为:
SELECT a.*,b.harmless_quantity
FROM t_farmers a LEFT JOIN
(SELECT b.farmer_id,SUM(b.death_number) harmless_quantity FROM t_farmers_details b
WHERE b.date_time LIKE '%2017-12%' GROUP BY b.farmer_id ) b ON a.id=b.farmer_id
WHERE 1=1
执行计划为:

核心修改是多了temporary、filesort,
这样一来原来需要几分钟导出的一个Excel,现在只需几秒钟解决,特此记录。
初窥门径,不当之处还望指教。
欢迎大家进企鹅群交流:589847567;
这篇关于MySQL的in查询效率太低的解决办法之一与其它优化示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




