本文主要是介绍编译原理:cminus_compiler-2021-fall Lab1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说点什么
某湖的编译原理实验。这个实验其实原本是中科大他们那边的编译原理实验项目,然后我们的编译原理实验就是果果和他们py的(X)
注意:本博客仅供参考!!!
0.基础知识
在本次实验中我们讲重点用到FLEX和以C-为基础改编的cminus-f语言。这里对其进行简单介绍。
0.1 cminus-f词法
C MINUS是C语言的一个子集,该语言的语法在《编译原理与实践》第九章附录中有详细的介绍。而cminus-f则是在C MINUS上追加了浮点操作。
1.关键字
else if int return void while float
2.专用符号
+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */
3.标识符ID和整数NUM,通过下列正则表达式定义:
letter = a|...|z|A|...|Z
digit = 0|...|9
ID = letter+
INTEGER = digit+
FLOAT = (digit+. | digit*.digit+)
4.注释用/…/表示,可以超过一行。注释不能嵌套。
/*...*/
注:[, ], 和 [] 是三种不同的token。[]用于声明数组类型,[]中间不得有空格。
a[]应被识别为两个token: a、[]
a[1]应被识别为四个token: a, [, 1, ]
0.2 FLEX简单使用
FLEX是一个生成词法分析器的工具。利用FLEX,我们只需提供词法的正则表达式,就可自动生成对应的C代码。整个流程如下图:

首先,FLEX从输入文件*.lex或者stdio读取词法扫描器的规范,从而生成C代码源文件lex.yy.c。然后,编译lex.yy.c并与-lfl库链接,以生成可执行的a.out。最后,a.out分析其输入流,将其转换为一系列token。
我们以一个简单的单词数量统计的程序wc.l为例:
%{
//在%{和%}中的代码会被原样照抄到生成的lex.yy.c文件的开头,您可以在这里书写声明与定义
#include <string.h>
int chars = 0;
int words = 0;
%}%%/*你可以在这里使用你熟悉的正则表达式来编写模式*//*你可以用C代码来指定模式匹配时对应的动作*//*yytext指针指向本次匹配的输入文本*//*左部分([a-zA-Z]+)为要匹配的正则表达式,右部分({ chars += strlen(yytext);words++;})为匹配到该正则表达式后执行的动作*/
[a-zA-Z]+ { chars += strlen(yytext);words++;}. {}/*对其他所有字符,不做处理,继续执行*/%%int main(int argc, char **argv){//yylex()是flex提供的词法分析例程,默认读取stdin yylex(); printf("look, I find %d words of %d chars\n", words, chars);return 0;
}
使用Flex生成lex.yy.c
[TA@TA example]$ flex wc.l
[TA@TA example]$ gcc lex.yy.c -lfl
[TA@TA example]$ ./a.out
hello world
^D
look, I find 2 words of 10 chars
[TA@TA example]$
注: 在以stdin为输入时,需要按下ctrl+D以退出
至此,你已经成功使用Flex完成了一个简单的分析器!
1. 实验要求
本次实验需要各位同学根据cminux-f的词法补全lexical_analyer.l文件,完成词法分析器,能够输出识别出的token,type ,line(刚出现的行数),pos_start(该行开始位置),pos_end(结束的位置,不包含)。如:
文本输入:
int a;
则识别结果应为:
int 280 1 2 5
a 285 1 6 7
; 270 1 7 8
具体的需识别token参考lexical_analyzer.h
特别说明对于部分token,我们只需要进行过滤,即只需被识别,但是不应该被输出到分析结果中。因为这些token对程序运行不起到任何作用。
注意,你所需修改的文件应仅有[lexical_analyer.l]…/…/src/lexer/lexical_analyzer.l)。关于FLEX用法上文已经进行简短的介绍,更高阶的用法请参考百度、谷歌和官方说明。
1.1 目录结构
整个repo的结构如下
.
├── CMakeLists.txt
├── Documentations
│ └── lab1
│ └── README.md <- lab1实验文档说明
├── README.md
├── Reports
│ └── lab1
│ └── report.md <- lab1所需提交的实验报告(你需要在此提交实验报告)
├── include <- 实验所需的头文件
│ └── lexical_analyzer.h
├── src <- 源代码
│ └── lexer
│ ├── CMakeLists.txt
│ └── lexical_analyzer.l <- flex文件,lab1所需完善的文件
└── tests <- 测试文件└── lab1├── CMakeLists.txt├── main.c <- lab1的main文件├── test_lexer.py├── testcase <- 助教提供的测试样例└── TA_token <- 助教提供的关于测试样例的词法分析结果
1.2 编译、运行和验证
lab1的代码大部分由C和python构成,使用cmake进行编译。
·编译
# 进入workspace
$ cd cminus_compiler-2021-fall# 创建build文件夹,配置编译环境
$ mkdir build
$ cd build
$ cmake ../# 开始编译
# 如果你只需要编译lab 1,请使用 make lexer
$ make
编译成功将在${WORKSPACE}/build/下生成lexer命令
·运行
$ cd cminus_compiler-2021-fall
# 运行lexer命令
$ ./build/lexer
usage: lexer input_file output_file
# 我们可以简单运行下 lexer命令,但是由于此时未完成实验,当然输出错误结果
$ ./build/lexer ./tests/lab1/testcase/1.cminus out
[START]: Read from: ./tests/lab1/testcase/1.cminus
[ERR]: unable to analysize i at 1 line, from 1 to 1
......
......$ head -n 5 out
[ERR]: unable to analysize i at 1 line, from 1 to 1 258 1 1 1
[ERR]: unable to analysize n at 1 line, from 1 to 1 258 1 1 1
[ERR]: unable to analysize t at 1 line, from 1 to 1 258 1 1 1
[ERR]: unable to analysize at 1 line, from 1 to 1 258 1 1 1
[ERR]: unable to analysize g at 1 line, from 1 to 1 258 1 1 1
我们提供了./tests/lab1/test_lexer.py python脚本用于调用lexer批量完成分析任务
# test_lexer.py脚本将自动分析./tests/lab1/testcase下所有文件后缀为.cminus的文件,并将输出结果保存在./tests/lab1/token文件下下
$ python3 ./tests/lab1/test_lexer.py·········
#上诉指令将在./tests/lab1/token文件夹下产生对应的分析结果
$ ls ./tests/lab1/token
1.tokens 2.tokens 3.tokens 4.tokens 5.tokens 6.tokens
·验证
$ diff ./tests/lab1/token ./tests/lab1/TA_token
# 如果结果完全正确,则没有任何输出结果
# 如果有不一致,则会汇报具体哪个文件哪部分不一致
请注意助教提供的testcase并不能涵盖全部的测试情况,完成此部分仅能拿到基础分,请自行设计自己的testcase进行测试。
1.3 提交要求和评分标准
·提交要求
本实验的提交要求分为两部分:实验部分的文件和报告,git提交的规范性。
·实验部分:
·需要完善./src/lab1/lexical_analyer.l文件;
·需要在./Report/lab1/report.md撰写实验报告。
·实验报告内容包括:
·实验要求、实验难点、实验设计、实验结果验证、实验反馈(具体参考report.md);
·实验报告推荐提交 PDF 格式。
·git提交规范:
·不破坏目录结构(report.md所需的图片请放在Reports/lab1/figs/下);
·不上传临时文件(凡是自动生成的文件和临时文件请不要上传,包括lex.yy.c文件以及各位自己生成的tokens文件);
·git log言之有物(不强制, 请不要git commit -m ‘commit 1’, git commit -m ‘sdfsdf’,每次commit请提交有用的comment信息)
·评分标准
·源代码测试: 60%
·git提交规范(20分);
·实现词法分析器并通过给出的6个测试样例(一个10分,共60分);
·提交后通过助教进阶的多个测试用例(20分)。
·实验报告:40%
代码
%option noyywrap
%{
/*****************声明和选项设置 begin*****************/
#include <stdio.h>
#include <stdlib.h>#include "lexical_analyzer.h"int lines;
int pos_start;
int pos_end;/*****************声明和选项设置 end*****************/%}%%/******************TODO*********************//****请在此补全所有flex的模式与动作 start******///STUDENT TO DO\+ {pos_start=pos_end;pos_end=pos_start+1;return ADD;}
\- {pos_start=pos_end;pos_end=pos_start+1;return SUB;}
\* {pos_start=pos_end;pos_end=pos_start+1;return MUL;}
\/ {pos_start=pos_end;pos_end=pos_start+1;return DIV;}
\< {pos_start=pos_end;pos_end=pos_start+1;return LT;}
"<=" {pos_start=pos_end;pos_end=pos_start+2;return LTE;}
\> {pos_start=pos_end;pos_end=pos_start+1;return GT;}
">=" {pos_start=pos_end;pos_end=pos_start+2;return GTE;}
"==" {pos_start=pos_end;pos_end=pos_start+2;return EQ;}
"!=" {pos_start=pos_end;pos_end=pos_start+2;return NEQ;}
\= {pos_start=pos_end;pos_end=pos_start+1;return ASSIN;}
\; {pos_start=pos_end;pos_end=pos_start+1;return SEMICOLON;}
\, {pos_start=pos_end;pos_end=pos_start+1;return COMMA;}
\( {pos_start=pos_end;pos_end=pos_start+1;return LPARENTHESE;}
\) {pos_start=pos_end;pos_end=pos_start+1;return RPARENTHESE;}
\[ {pos_start=pos_end;pos_end=pos_start+1;return LBRACKET;}
\] {pos_start=pos_end;pos_end=pos_start+1;return RBRACKET;}
\{ {pos_start=pos_end;pos_end=pos_start+1;return LBRACE;}
\} {pos_start=pos_end;pos_end=pos_start+1;return RBRACE;}
else {pos_start=pos_end;pos_end=pos_start+4;return ELSE;}
if {pos_start=pos_end;pos_end=pos_start+2;return IF;}
int {pos_start=pos_end;pos_end=pos_start+3;return INT;}
float {pos_start=pos_end;pos_end=pos_start+5;return FLOAT;}
return {pos_start=pos_end;pos_end=pos_start+6;return RETURN;}
void {pos_start=pos_end;pos_end=pos_start+4;return VOID;}
while {pos_start=pos_end;pos_end=pos_start+5;return WHILE;}
[a-zA-Z]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return IDENTIFIER;}
[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return INTEGER;}
[0-9]*\.[0-9]+ {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return FLOATPOINT;}
"[]" {pos_start=pos_end;pos_end=pos_start+2;return ARRAY;}
[a-zA-Z] {pos_start=pos_end;pos_end=pos_start+1;return LETTER;}
[0-9]+\. {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return FLOATPOINT;}
\n {return EOL;}
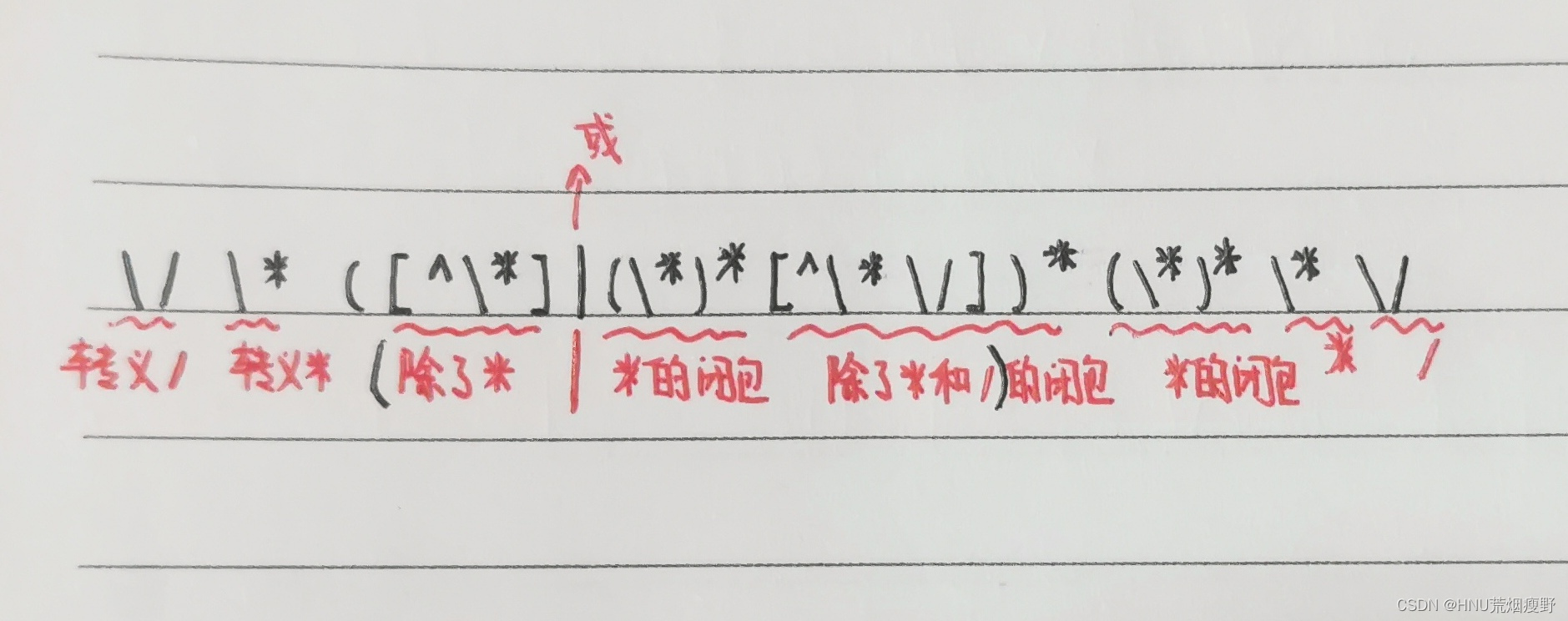
\/\*([^\*]|(\*)*[^\*\/])*(\*)*\*\/ {return COMMENT;}
" " {return BLANK;}
\t {return BLANK;}
. {pos_start=pos_end;pos_end=pos_start+strlen(yytext);return ERROR;}/****请在此补全所有flex的模式与动作 end******/
%%
/****************C代码 start*************//// \brief analysize a *.cminus file
///
/// \param input_file, 需要分析的文件路径
/// \param token stream, Token_Node结构体数组,用于存储分析结果,具体定义参考lexical_analyer.hvoid analyzer(char* input_file, Token_Node* token_stream){lines = 1;pos_start = 1;pos_end = 1;if(!(yyin = fopen(input_file,"r"))){printf("[ERR] No input file\n");exit(1);}printf("[START]: Read from: %s\n", input_file);int token;int index = 0;while(token = yylex()){switch(token){case COMMENT://STUDENT TO DO{pos_start=pos_end;pos_end=pos_start+2;int i=2;while(yytext[i]!='*' || yytext[i+1]!='/'){ if(yytext[i]=='\n'){lines=lines+1;pos_end=1;}elsepos_end=pos_end+1;i=i+1;}pos_end=pos_end+2;break;}case BLANK://STUDENT TO DO{pos_start=pos_end;pos_end=pos_start+1;break;}case EOL://STUDENT TO DO{lines+=1;pos_end=1;break;}case ERROR:printf("[ERR]: unable to analysize %s at %d line, from %d to %d\n", yytext, lines, pos_start, pos_end);default :if (token == ERROR){sprintf(token_stream[index].text, "[ERR]: unable to analysize %s at %d line, from %d to %d", yytext, lines, pos_start, pos_end);} else {strcpy(token_stream[index].text, yytext);}token_stream[index].token = token;token_stream[index].lines = lines;token_stream[index].pos_start = pos_start;token_stream[index].pos_end = pos_end;index++;if (index >= MAX_NUM_TOKEN_NODE){printf("%s has too many tokens (> %d)", input_file, MAX_NUM_TOKEN_NODE);exit(1);}}}printf("[END]: Analysis completed.\n");return;
}
/****************C代码 end*************/
大部分操作就是挺正常的写,然后注释,空格,回车,错误这四个需要在后面单独处理一下,但是好像错误的代码是已经给好的(大概?)
写这篇博客的时候已经是放假了,已经记不清当时做这个实验的心路历程了,就记得大概:好像这个一开始写的时候是根本毫无头绪,然后看了前辈完成的代码的时候就突然醒悟这个应该怎么做,然后就发现其实挺简单的(大概?)
这里补充一个[注释]的解释吧,可能你们会有问题(超级贴心的学姐
这篇关于编译原理:cminus_compiler-2021-fall Lab1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







