本文主要是介绍OpenCSV处理反斜线 \ ,将.csv文件映射为Java对象落库clickhouse,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、关键:RFC4180Parser
1、默认情况下,CSVReader使用双反斜线(’\’)作为其转义字符。同时,CSVWriter使用双引号(’“’)作为转义字符。
因此,反斜线字符会导致不正确的转义。在读数据时,CSVParser将忽略单个反斜线字符,因为它是转义字符。
CSVReader使用CSVParser解析CSV数据。2、OpenCSV还提供了一个严格遵循RFC4180标准的解析器:RFC4180Parser。
使用 RFC4180Parser 解析器,CSVReader会以双引号(’“’)作为转义字符,这样就可以与CSVWriter的转义方式保持一致。
二、原始需求
使用定时任务,将用户的行为日志数据文件(.csv)解析为java对象,并批量落入clickhouse数据库(MySQL亦同理)。
行为日志包含:网站访问日志、文件上传日志等数据
三、具体方案:本文着重介绍第3点
-
1、springboot+mybatis配置clickhouse(略) 点击前往
-
2、spring的定时任务@Scheduled
/*** 1、每天00:05,将当天的用户行为日志文件解压至指定文件夹*/@Scheduled(cron = "0 5 0 * * ?")public void unZipFile() {/** 1、解压当天拉取的前一天行为日志文件到指定文件夹下 **/log.info("时间:"+DateUtils.getCurrentDateStr()+",开始解压文件 filePath:" + filePath + ",unZipPath:" + unZipPath);fileUnzipService.unZip(filePath + DateUtils.getYestoday(DateUtils.YYMMDD), unZipPath + DateUtils.getYestoday(DateUtils.YY_MM_DD) + "/");}/*** 2、每天00:30,将前一天解压后的用户行为日志文件数据同步至clickhouse* 具体为clickhouse库的 xxx 表* 3、入库完成后,删除前一天(昨天)同步目录下的行为日志文件,并且删除前两天(前天)解压目录下的日志文件,减少对服务器存储资源的占用*/@Scheduled(cron = "0 30 0 * * ?")public void syncUserLogFromFileToCK() {//1、解析.csv文件映射为java对象;//2、批量入库clickhouse,并记录每天不同日志类型入库的数据条数,方便后续查看}- 3、openCSV解析.csv映射为java对象
四、实施步骤:
.csv文件数据demo(基于文件数据创建clickhouse对应的表以及映射的java对象)
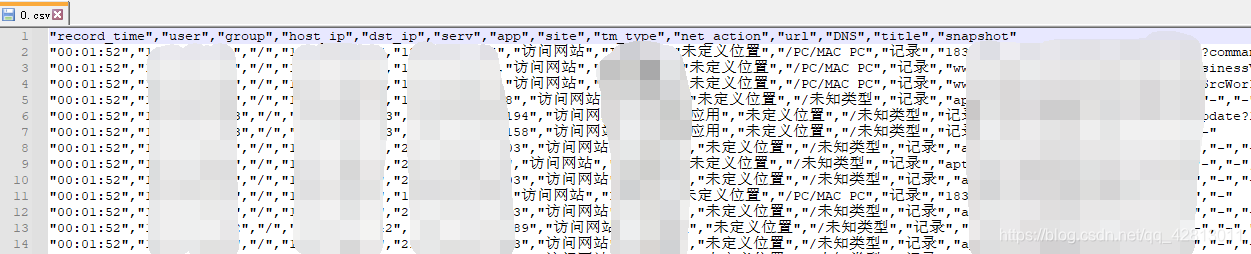
- 1、openCSV jar包引入
<dependency><groupId>com.opencsv</groupId><artifactId>opencsv</artifactId><version>4.6</version>
</dependency>
- 2、serviceImpl代码(依次对应3种不同类型日志)
/**- @author: Lucy- @version:- @createTime: 2021/5/19 10:51- @Description: 使用opencsv解析csv文件(基于字段名的映射)并进行ORM映射为对象集合 需- 注意CSV文件中列的内容包含转义字符 "\"的问题- 指定转换类型的注解主要有@CsvCustomBindByName和@CsvCustomBindByPosition这2种,分别对应基于字段名的映射和基于字段位置的映射。*/
@Service
@Slf4j
public class CsvParseLogServiceImpl implements CsvParseLogService {@Overridepublic List<UserBehaviorsOtherLog> parseOtherByName(File file) throws IOException {InputStreamReader inputStream = new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8);// 设置解析策略,csv的头和POJO属性的名称对应,也可以使用@CsvBindByName注解来指定名称HeaderColumnNameMappingStrategy strategy = new HeaderColumnNameMappingStrategy();strategy.setType(UserBehaviorsOtherLog.class);CsvToBean csvToBean = new CsvToBeanBuilder(inputStream).withMappingStrategy(strategy)//文件中使用的分割符 默认为逗号分割//.withSeparator(',').build();List<UserBehaviorsOtherLog> csvDTOList = csvToBean.parse();return csvDTOList;}@Overridepublic List<UserBehaviorsUpfileLog> parseUpfileByName(File file) throws IOException {InputStreamReader inputStream = new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8);// 设置解析策略,csv的头和POJO属性的名称对应,也可以使用@CsvBindByName注解来指定名称HeaderColumnNameMappingStrategy strategy = new HeaderColumnNameMappingStrategy();strategy.setType(UserBehaviorsUpfileLog.class);CsvToBean csvToBean = new CsvToBeanBuilder(inputStream).withMappingStrategy(strategy)//文件中使用的分割符 默认为逗号分割//.withSeparator(',').build();List<UserBehaviorsUpfileLog> csvDTOList = csvToBean.parse();return csvDTOList;}/*** 默认情况下,CSVReader使用双反斜线(’\’)作为其转义字符。同时,CSVWriter使用双引号(’“’)作为转义字符。* 因此,反斜线字符会导致不正确的转义。在读数据时,CSVParser将忽略单个反斜线字符,因为它是转义字符。* CSVReader使用CSVParser解析CSV数据。OpenCSV还提供了一个严格遵循RFC4180标准的解析器:RFC4180Parser。* 使用RFC4180Parser解析器,CSVReader会以双引号(’“’)作为转义字符,这样就可以与CSVWriter的转义方式保持一致。* @param file* @return* @throws IOException*/@Overridepublic List<UserBehaviorsUrlLog> parseUrlByName(File file) throws IOException {RFC4180Parser rfc4180Parser = new RFC4180ParserBuilder().build();CSVReader inputStream = new CSVReaderBuilder(new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8)).withCSVParser(rfc4180Parser).build();//InputStreamReader inputStream = new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8);//CSVReader csvReader = new CSVReader();// 设置解析策略,csv的头和POJO属性的名称对应,也可以使用@CsvBindByName注解来指定名称HeaderColumnNameMappingStrategy strategy = new HeaderColumnNameMappingStrategy();strategy.setType(UserBehaviorsUrlLog.class);CsvToBean csvToBean = new CsvToBeanBuilder(inputStream).withMappingStrategy(strategy)//文件中使用的分割符 默认为逗号分割//.withSeparator(',').build();List<UserBehaviorsUrlLog> csvDTOList = csvToBean.parse();return csvDTOList;}
}
- 4、相关mapper及配置文件
@Mapper
public interface UserBehaviorsUpfileLogMapperExt {/*** 读取行为日志信息,写入clickhouse* @param records* @return 落库条数*/int insertUpfileLog(@Param("records") List<UserBehaviorsUpfileLog> records);}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxxx.mapper.ext.UserBehaviorsUpfileLogMapperExt"><sql id="Base_Column_List">(transfer_date, record_time, user, group, host_ip, dst_ip, serv, app, site, tm_type, net_action, file_name, file_size, file_type)</sql><insert id="insertUpfileLog" parameterType="com.xxxx.model.UserBehaviorsUpfileLog">INSERT INTO log.xxzx_user_behaviors_upfile_log<include refid="Base_Column_List" />VALUES<foreach collection="records" item="item" index="index"separator=",">(#{item.transfer_date,jdbcType=DATE},#{item.record_time},#{item.user},#{item.group},#{item.host_ip},#{item.dst_ip},#{item.serv},#{item.app},#{item.site},#{item.tm_type},#{item.net_action},#{item.file_name},#{item.file_size},#{item.file_type})</foreach></insert></mapper>
- 5、clickhouse表所映射的java对象
@Data
public class UserBehaviorsUrlLog {//private String transfer_time;private Date transfer_date;@CsvBindByName(column = "record_time",required = false)private String record_time;@CsvBindByName(column = "user",required = false)private String user;@CsvBindByName(column = "group",required = false)private String group;@CsvBindByName(column = "host_ip",required = false)private String host_ip;@CsvBindByName(column = "dst_ip",required = false)private String dst_ip;@CsvBindByName(column = "serv",required = false)private String serv;@CsvBindByName(column = "app",required = false)private String app;@CsvBindByName(column = "site",required = false)private String site;@CsvBindByName(column = "tm_type",required = false)private String tm_type;@CsvBindByName(column = "net_action",required = false)private String net_action;@CsvBindByName(column = "url",required = false)private String url;@CsvBindByName(column = "DNS",required = false)private String dns;@CsvBindByName(column = "title",required = false)private String title;@CsvBindByName(column = "snapshot",required = false)private String snapshot;
}
- 6、调用代码
.......File file = new File(fileName);//根据解压后的文件目录名称判断当前文件的类型if(fileName.indexOf(URL_LOG) != -1) {List<UserBehaviorsUrlLog> urlLogList = csvParseLogService.parseUrlByName(file);for (List<UserBehaviorsUrlLog> listSub : lists) {upfileLogMapperExt.insertUpfileLog(upfileLogList);}}......
欢迎补充,完毕!!!
这篇关于OpenCSV处理反斜线 \ ,将.csv文件映射为Java对象落库clickhouse的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




