本文主要是介绍【Pytorch】DCGAN实战(四):总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DCGAN生成图像小结
- 一、MINIST数据集测试
- 1.1代码相关参数说明
- 1.2训练过程
- (1)Epoch:2
- (2)Epoch:3
- (3)Epoch:4
- (4)Epoch:5
- (5)Epoch:10
- (6)Epoch:20
- (7)汇总
- 二、牛津花卉数据集测试
- 2.1代码相关参数说明
- 2.2训练过程
- (1)Epoch:20
- (2)Epoch:50
- (3)Epoch:100
- (4)Epoch:200
- (5)Epoch:500
- (6)Epoch:1000
- (7)汇总
- 三、二次元头像数据集测试
- 3.1代码相关参数说明
- 3.2第一阶段
- (1)400epoch
- (2)600epoch
- (3)800epoch
- 3.3第二阶段
- (1)Epoch10
- (2)Epoch30
- (3)Epoch50
- (4)Epoch100
- (5)Epoch200
- (6)Epoch300
- (7)Epoch500
- (8)汇总
- 四、小结
- 五、所有代码资料
一、MINIST数据集测试
1.1代码相关参数说明
Batchsize:128
Data:70000,1,28,2870000,1.64,64(dataset) 128,1,64,64
Noise:z=128,100,1,1 G(z)=128,1,64,64
Class:0-9
LossD:LossD=-[ log(D(x)) + log(1 - D(G(z)))], LossG=- log(D(G(z)))
Optimizer:opt_G=torch.optim.Adam(),opt_D = torch.optim.Adam()
Generator((main): Sequential((0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(8): ReLU(inplace=True)(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(11): ReLU(inplace=True)(12): ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(13): Tanh()
Discriminator((main): Sequential((0): Conv2d(1, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(1): LeakyReLU(negative_slope=0.2, inplace=True)(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2, inplace=True)(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2, inplace=True)(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2, inplace=True)(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)(12): Sigmoid())
)
1.2训练过程
(1)Epoch:2

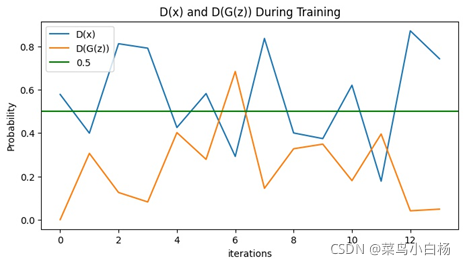

(2)Epoch:3

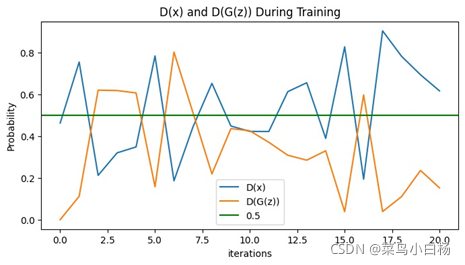
(3)Epoch:4

(4)Epoch:5

(5)Epoch:10


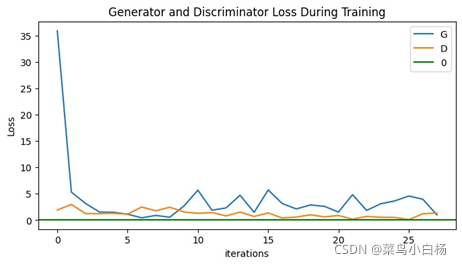
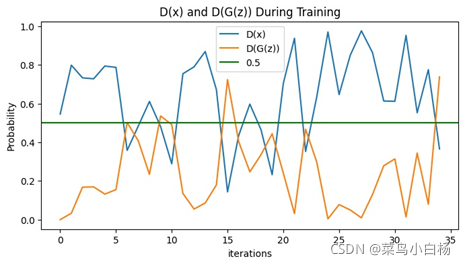
开始直接训练了10个epoch,训练结束之后发现,观察Loss,训练到后面的epoch,Loss值不变化,应该是出现梯度消失。之后尝试训练2epoch,3epoch,4epoch,5epoch以及20epoch观察生成的图片集,以及D和G的Loss。
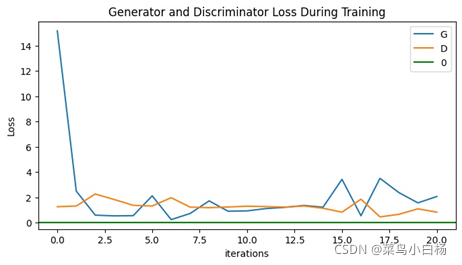
(6)Epoch:20

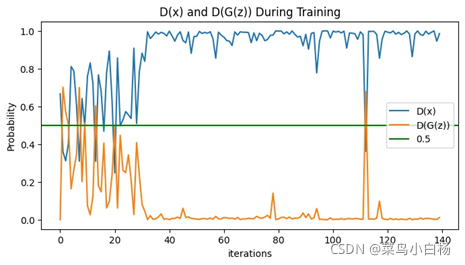

(7)汇总
说明一个epoch画图显示7个iter的Loss。可以看到我们训练10个epoch的时候,在6个epoch左右的时候D(x)和D(G(z))的值就没有明显的变化了,此时的Loss G突然激增,之后没有什么变化,最后显示的第10个epoch生成的图片是全糊的。同样训练20个epoch的时候也是在6个epoch左右也是没什么变化了,但是相较于10个epoch的还是有起伏的,最终生成的图片要比10个epoch的好一点,但是其实形状是错误的而且生成了很多重复的图片,对应GAN常见的模式崩溃的问题。
可以看到MINIST数据集训练很快5个epoch左右已经能生成很好的图片了,当时看到就很惊讶(孩子已经被4dB和30dB吓傻了),后来这就是简单数据集的好处,而且神经网络拟合数据分布的功能真的好强大呀!后来又想到之前用LeNet5测试识别手写数据集的时候好像10epoch左右分类精度也达到100%了。
| Epoch | Real_Fake | D(x)_D(G(z)) | LD_LG |
|---|---|---|---|
| 2 |  |  |  |
| 3 |  |  |  |
| 4 |  |  |  |
| 5 |  |  |  |
| 10 |  |  |  |
| 20 |  |  |  |
DCGAN初始的值要求很高,否则很容易出现梯度消失的情况。举例当epoch=4,训练较好和训练不好。
| Epoch | 4(bad) | 4(good) |
|---|---|---|
| Real_Fake |  |  |
| D(x)_D(G(z)) |  |  |
| LossD_LossG |  |  |
| LossD_LossG | 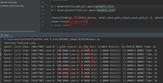 | 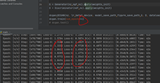 |
在实验过程中发现,有时候刚开始训练,就出现了LossD和Loss G的值都不变的情况,就感觉像是要掌握火候一样(看人品的时候[狗头]),如果开始LossD以及LossG训练的挺好的,之后训练G和D都在慢慢学习,开始如果就LossD和Loss G不变,那就不用接着训练了,直接凉凉。
二、牛津花卉数据集测试
在原MINIST的代码的基础上修改,主要是修改了Dataset以及Dataloader的部分。MINIST对应的Pytorch有专门的函数读取,Oxford17改用Imgfolder读取。
2.1代码相关参数说明
Batchsize:128
Data:1360,x,y,3 1360,3,64,64(dataset)128,3,64,64(datloader)
Noise:z=128,100,1,1G(z)=128,3,64,64
Class:0-16
LossD:LossD=-[ log(D(x)) + log(1 - D(G(z)))], LossG=- log(D(G(z)))
Optimizer:opt_G=torch.optim.Adam(),opt_D = torch.optim.Adam()
Generator((main): Sequential((0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(8): ReLU(inplace=True)(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(11): ReLU(inplace=True)(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(13): Tanh())
)
Discriminator((main): Sequential((0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(1): LeakyReLU(negative_slope=0.2, inplace=True)(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2, inplace=True)(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2, inplace=True)(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2, inplace=True)(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)(12): Sigmoid())
)
2.2训练过程
(1)Epoch:20

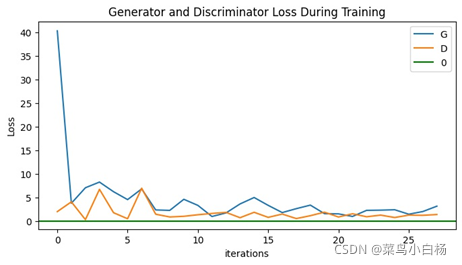
(2)Epoch:50

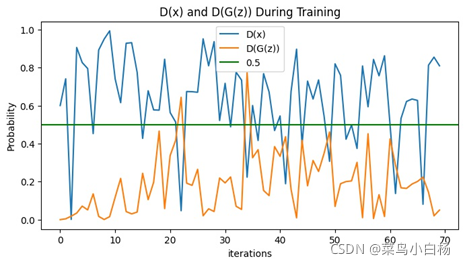
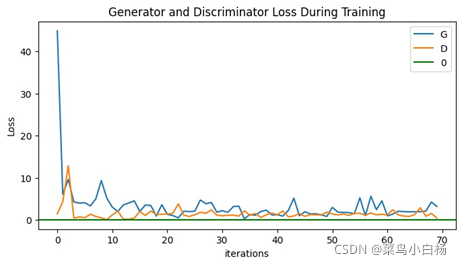
(3)Epoch:100

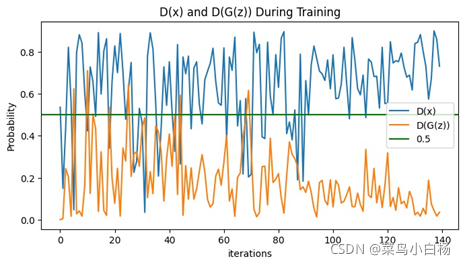
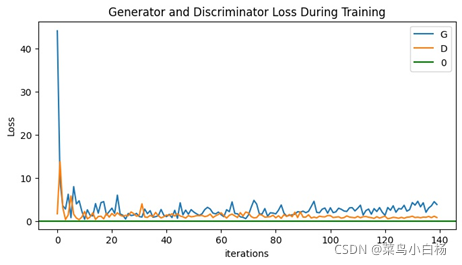
(4)Epoch:200

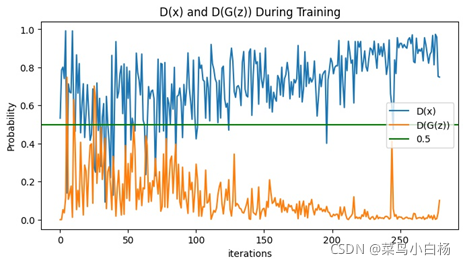

(5)Epoch:500

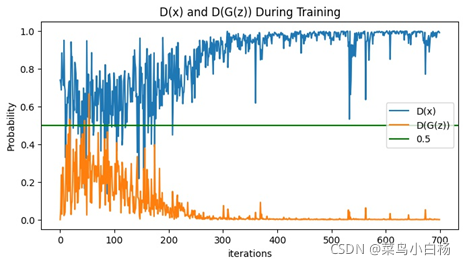
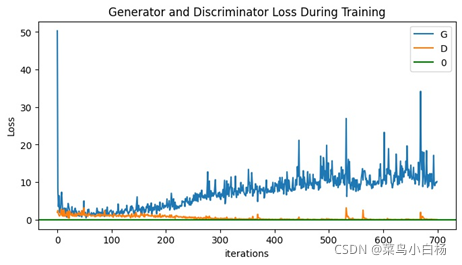
(6)Epoch:1000

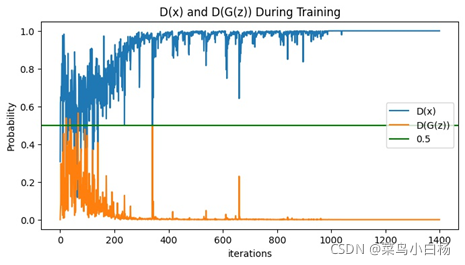

(7)汇总
| Epoch | Real_Fake | D(x)_D(G(z)) | LD_LG |
|---|---|---|---|
| 20 |  |  |  |
| 50 |  |  |  |
| 100 |  |  |  |
| 200 |  |  |  |
| 500 |  |  |  |
| 1000 |  |  |  |
完成了MINIST的数据集之后,Oxford17只是改动了数据预处理的部分(也许是过渡的太过顺利,为后面改造生成二次元埋下了隐患[暴风哭泣]),相比于MINIST数据集,Oxford17还是复杂点的,这里要说明一下,网站上下载的数据集是每类80张,按顺序放在一起的,写了个程序分好类(哈哈新知识get√)。之后就用分好类的和未分类的进行试验,从打印出来的数据来看,未分类的是没有已分类的效果好的。我只能以人的视角去解释啦,如果把一堆图片放在我面前让我学习特征,我都不一定能学出17种分布。但如果这17类分类好把放在我面前,虽然我只知道他们是真的,但是我应该会会更好的学习到每一类的特征吧(嘻嘻纯属我个人的强行解释)。
三、二次元头像数据集测试
用DCGAN生成二次元头像,采用了一份网上的参考代码,整体思路和MINIST以及Oxford17的思路是一致的,但在以下几个方面做了修改:
1.定义一个类,用于存放超参数的值
2.不用打印每个epoch来表明训练进度,使用tqdm库,调用tdqm()函数以内存进度的形式表明训练过程。
3.训练过程中,对于Discriminator,每经过一个batch,参数进行一次更新;Generator,经过k次进行一次更新。
参考代码全部放在一个.py文件里,所以还是先整合(我总有感觉一分开放到不同的.py文件,程序运行会慢一些,但是分开放,结构清晰),之后加入之前MINIST和Oxford17绘制Loss等图像的代码。在整合的过程中,对于创建的存放超参数的类的使用,尝试了不同的方法,也出现了一些新的问题。
整个过程,主要是代码研读(我发现不同的人写代码的风格真的完全不一样,这个过程也学习到了很多,虽然在此之前已经编写了MINIST以及Oxford17的代码,但是看到新的代码又出现了新的函数或者说是相同的函数更改参数就是新的用法,既是查漏补缺又在不断学习新知识)以及代码整合(在网上查找到的一些代码都是写在一个.py文件里,我猜想应该是方便直接阅读以及运行,但是我就有点习惯分到不同的.py文件里感觉结构更清晰。但是这样做据我的观察是运行要慢一点)。对于网络参数的调整,几乎没有调试,直接采用的是参考代码的网络。
3.1代码相关参数说明
定义存放超参数的新类:
class Config(object):# 0.数据data_path = './data/'img_size = 96 # 剪切图片的像素大小batch_size = 256 # 批处理数量# 1.设备num_workers = 0 # 多线程ngpu=1device = torch.device('cuda:0' if (torch.cuda.is_available() and ngpu > 0) else 'cpu') #是否使用GPU运算# 2.训练模型max_epoch = 2 # 最大轮次d_every = 1 # 每1个batch 训练一次判别器,判别模型的更新频率要高于生成模型g_every = 5 # 每5个batch训练一次生成模型save_every = 5 # 每save_every次保存一次模型# 3.噪声nz = 100 # 噪声维度z_mean=0 #生成模型的噪声均值z_std=1 #噪声方差# 4.real和fake标签real_label=1fake_label=0# 5.模型输入参数nc = 3ngf = 64 # 生成器的卷积核个数ndf = 64 # 判别器的卷积核个数# 6.优化器参数lrg = 2e-4 # 生成器学习率lrd = 2e-4 # 判别器学习率beta1 = 0.5 # 正则化系数,Adam优化器参数# 7.模型保存路径save_models_path = './models/'netd_path = './models/'netg_path = './models/'virs = "result"# 9.生成图片保存路径gen_num = 64nrow = 8save_imgs_path = './imgs/' # opt.netg_path生成图片的保存路径save_figures_path = './figures/'gen_img = "result.png"Generator((Gene): Sequential((0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(8): ReLU(inplace=True)(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(11): ReLU(inplace=True)(12): ConvTranspose2d(64, 3, kernel_size=(5, 5), stride=(3, 3), padding=(1, 1), bias=False)(13): Tanh())
)
Discriminator((Discrim): Sequential((0): Conv2d(3, 64, kernel_size=(5, 5), stride=(3, 3), padding=(1, 1), bias=False)(1): LeakyReLU(negative_slope=0.2, inplace=True)(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2, inplace=True)(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2, inplace=True)(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2, inplace=True)(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1))(12): Sigmoid())
)3.2第一阶段
直接使用网上代码运行400epoch,600epoch,800epoch只能观察到生成的图片没有Loss图。
(1)400epoch

(2)600epoch

(3)800epoch

可以看到800epoch的时候无法生成图像,对比600epoch和400epoch,400epoch生成的图像还是有点模糊,600epoch生成的图像就相对清晰一些,但是生成的图片还是不能完全接近真实的图片的,存在一些五官扭曲,大小眼,天生异瞳。。(啊忍不住了好想笑哈哈哈),虽然有的还是呆呆的亚子,还是能看出基本的五官的比例的(强行赞美)。但到了800epoch的时候,已经生不成图像了。
3.3第二阶段
第二阶段主要是整合代码到不同的.py文件中。主要是5个py文件
├─03DCGAN_faces
│ ├─data
│ │ └─faces
│ ├─imgs
│ ├─figures
│ ├─models
│ ├─data.py
│ ├─hyperpara.py
│ ├─main.py
│ ├─model.py
│ ├─net.py
在整合过程中我有两个想法,一是画图用的变量保存在超参数类opt中,二是想要训练不同的epoch的话一般是再复制一遍,同时跑。我想的是能不能执行完train之后,在调用train函数。
但事实证明,没办法实现。(或者说要实现的的话,程序要大改[狗头])
实现一的过程中:存在的问题是变量保存在超参数类中,只要主程序main()不结束存放在类中的参数不释放,因此一些变量要是放在参数类中,之后被调用的时候,值不会被覆盖。
实现二的过程中,同样是第一次train后,D和G的参数会被保留,因此在训练的时候是在原来train的基础上再接着train的。
如果两个想同时实现的话,就是要清除变量内存,网络也要清除。这样除了是为了保持调用trin的时候是从头开始train的,再者是如果不清除,就空占着内存,最后一定会造成溢出的。
其实开始的时候我没意识到这些问题,我在按照自己的思路自认为改“好”了程序,在主程序main()中执行
dcgan.train(num_epochs=2)
dcgan.train(num_epochs=5)
dcgan.train(num_epochs=10)
绘图的时候发现num_epochs=5的legend出现了两遍,num_epochs=10的legend出现了三遍。



而且可以看到10epoch的是出现三条线,横坐标对应的也是2个epoch,5个epoch,10个epoch。所以变量一直是被保存的,画图的时候就会把之前的变量保存的值绘制出来。
后来就还是老老实实的,复制然后同时运行了(啊不甘心哈哈),并且加上了绘制loss部分的代码。
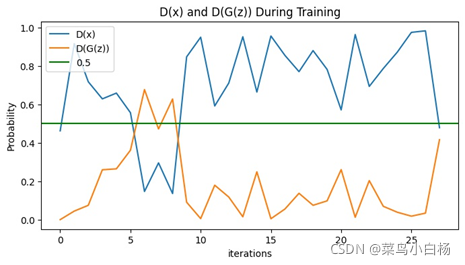
(1)Epoch10


(2)Epoch40

(3)Epoch50


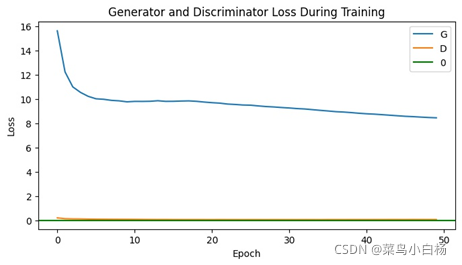
(4)Epoch100

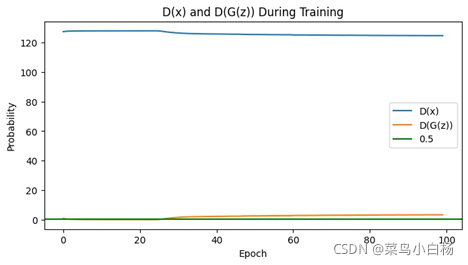
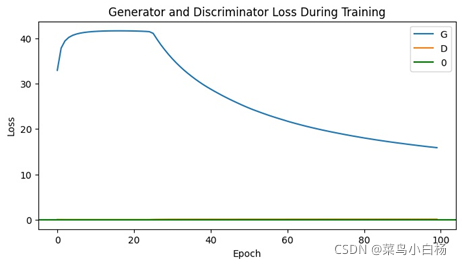
(5)Epoch200

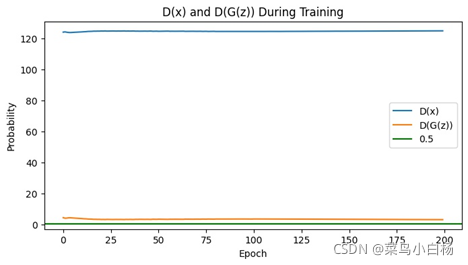

(6)Epoch400

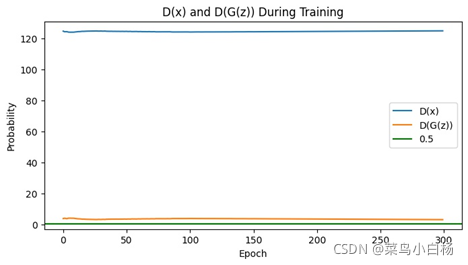

(7)Epoch500

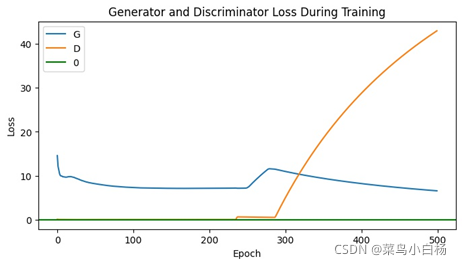
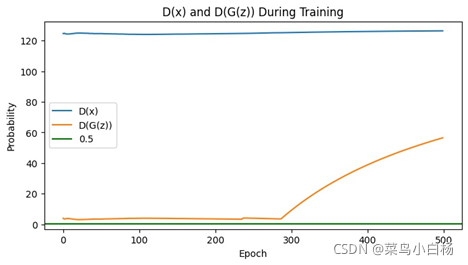
(8)汇总
| Epoch | Real_Fake | D(x)_D(G(z)) | LD_LG |
|---|---|---|---|
| 10 |  |  |  |
| 30 |  |  |  |
| 50 |  |  |  |
| 100 |  |  |  |
| 200 |  |  |  |
| 300 |  |  |  |
| 500 |  |  |  |
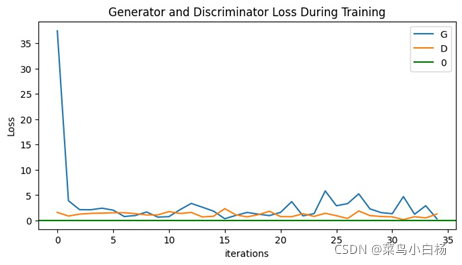
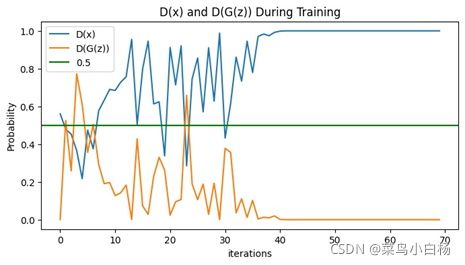
需要说明的是看起来生成二次元头像的D(x)以及D(G(z))的图像看起来是比较平滑的,是因为在绘图的时候对数值做了处理。
之前的是将每个iter存放在list中,绘图的时候是间隔采样,这样的话每个iter之后梯度会更新那么iter和iter之间的波动就会比较大。
但是在这次生成二次元图片时,D和G更新的频率不一样所以,最后没有采用显示每个iter的Loss以及D(x),D(G(z)),而是每个epoch结束后将每个iter求和取平均,这样的话可以看到整个都是比较平滑的。
从整个生成的图片来看的话,训练的前期生成的图片较为鲜艳但是轮廓不清晰,很张扬的感觉哈哈(画家新手:初出茅庐),训练的中期色彩就没有那么明丽了,而且有基本的线条人物的面部结构也较为完整(画家老手:手法娴熟),训练的次数增多,图像就越清晰了,但是还是会出现“怪异娃娃头”(画家高手:想不到词)。
但其实也不是越训练越好,如果训练次数达到一定程度之后反而会“坏掉”。
四、小结
现在对生成图像已经很熟悉了,整个的思路以及绘图的相关代码,还有自己整合代码的能力都有了很大的提高。尤其是这次编程的过程中又遇到了好多新的函数,以及见过的函数的参数的新用法,所以就又返回重新理解。自己之前有些模棱两可的认识(关于Pytorch张量部分的细节)又趁着这次机会把搞通搞懂了,感觉收获满满!!
再次惊叹于深度学习网络强大的拟合数据分布的能力!!真的是一个强大神秘又充满吸引力的领域呢!当它运行的时候,自己总会有一种面对未知的感觉,会想到图画,声音,信号这些都可以被作为高维分布的数据了,机器用它强大的计算能力去寻找数据在高维的分布是什么样子的,在我们眼里图像更多给我们带来一种视觉上的感觉,让我们知道哪些是花哪些是数字,哪些又是二次元头像,以及他们分别长什么样子,那我们的情感,气味,情绪等等这些代表我们感觉的之后是不是也可以作为数据?然后让机器去寻找他们真实的在高维的分布呢?害这些都不得而知了。。。但我相信未来的技术一定是属于人工智能的,至少目前看来已经是这样啦!
五、所有代码资料
https://pan.baidu.com/s/1TBz4C3IPCQnZx4JIcBApWg
提取码:DGAN
这篇关于【Pytorch】DCGAN实战(四):总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





