本文主要是介绍【RabbitMQ 实战】11 队列的结构和惰性队列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 队列的结构
队列的组成:
- 队列由 rabbit_amgqueue_process 和 backing_queue两部分组成。
- rabbit_amqqueue_process负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认 (包括生产端的 confirm 和消费端的 ack) 等。
- backing_queue是消息存储的具体形式和引擎,并向rabbit_amqqueue_process提供相关的接口以供调用。
消息投递: - 若消息投递的目的队列是空的,并且有消费者订阅了此队列,则该消息直接发给消费者,不经过队列。
- 若消息无法直接投递给消费者时,需要暂时将消息存入队列,以便重新投递。消息存入队列后,会随着系统的负载在队列中不断地流动,消息的状态会不断发生变化。
1.1 消息状态分类
消息的4 种状态:
- alpha状态:表示消息内容 (包括消息体、属性和 headers) 和消息索引都存储在内存中。
- beta状态:表示消息内容保存在磁盘中,消息索引保存在内存中。
- gamma状态:表示消息内容保存在磁盘中,消息索引在磁盘和内存中都有。
- delta状态:表示消息内容和索引都在磁盘中。
注意事项:
- 对于持久化的消息,消息内容和消息索引都必须先保存在磁盘上,才会处于上述状态中的一种。
- gamma 状态的消息是只有持久化的消息才会有的状态。
1.2 消息状态对资源影响
rabbitmq在运行时,会根据统计的消息传送速度,定期计算一个当前内存中能够保存的最大消息数量(target_ram_count)。
- 若alpha 状态的消息数量大于此值时,就会引起消息的状态转换,多余的消息可能会转换到beta 状态、gamma 状态或者 delta 状态。
- 区分这 4 种状态的主要作用是满足不同的内存和CPU需求。
消息状态对服务器资源的影响:
- alpha状态最耗内存,但很少消耗 CPU。
- delta状态基本不消耗内存,但是需要消耗更多的 CPU 和磁盘 I/O 操作。
注意事项:
- delta 状态需要执行两次I/O 操作才能读取到消息。一次是读消息索引 (从 rabbit_queue_index 中),一次是读消息内容(从 rabbit_msg_store 中)。
- beta 和 gamma 状态都只需要一次I/0 操作就可以读取到消息 (从 rabbit_msg_store中)。
1.3 队列中的消息状态分布结构
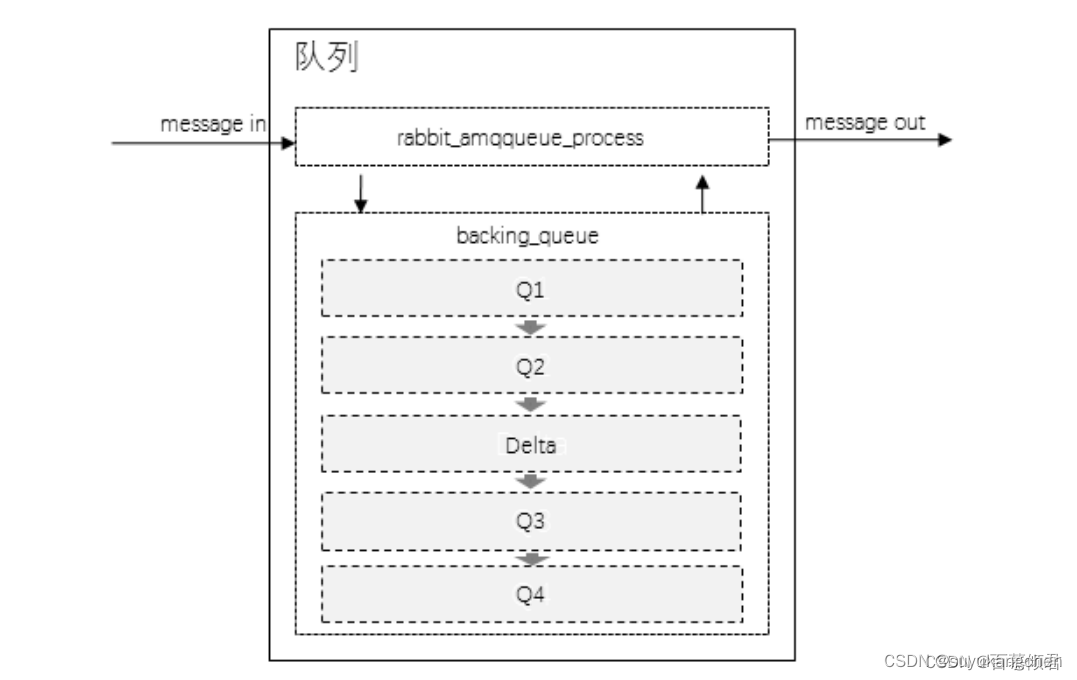
- 对于普通的没有设置优先级和镜像的队列来说,backing_queue的默认实现是rabbit_variable_queue。其内部通过 5 个子队列 Q1、Q2、Delta、Q3 和 Q4 来体现消息的各个状态。
- 整个队列包括rabbit_amgqueue_process和backing_queue 的各个子队列。
- 队列中的消息状态结构分布:
- Q1、Q4 只包含 alpha 状态的消息。也就是消息体和消息索引都在内存中的消息。
- Q2 、Q3 包含 beta 和gamma 状态的消息,
- Delta 只包含 delta 状态的消息。也就是消息内容和索引都在磁盘中的消息。
- 队列中的消息流动状态变化:
- 一般情况下,消息按照 Q1——> Q2——> Delta——> Q3——> Q4 顺序进行流动,但并不是每一条消息都一定会经历所有的状态,这个取决于当前系统的负载状况。
- 从Q1至Q4的过程,就相当于消息内存——> 磁盘——> 内存的过程。
- 当队列负载高,占用极大的内存时,可以把一部分消息放入磁盘,以此节省内存空间。
- 当队列负载降低,内存资源释放出来时,这部分消息又渐渐回到内存被消费者获取,使得整个队列具有很好的弹性。
1.4 消费者对队列中消息状态的影响变化
消费消息对队列中的消息状态变化流程:
- 第一步:当消费者获取消息时,首先会从 Q4 中获取内存中消息,如果获取成功则返回。
若Q4为空,则尝试从 Q3 中获取消息,进入第二步。 - 第二步:从Q3中获取消息时,系统首先会判断Q3是否为空,如果为空则返回队列为空,即此时队列中无消息。
若Q3不为空,则取出 Q3 中的消息并和Delta中的消息长度做已判断。如果Q3和Delta都为空,则可以认为 Q2、Delta、03、Q4 全部为空,此时将Q1中的消息直接转移至 Q4,下次直接从Q4 中获取消息。
若Q3为空,Delta 不为空,则将 Delta 的消息转移至Q3中,下次可以直接从Q3中获取消息。 - 第三步:在将消息从 Delta 转移到 Q3 的过程中,是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与Delta 中消息的个数是否相等,如果相等,则可以判定此时 Delta 中已无消息,则直接将Q2 和刚读取到的消息一并放入到 Q3 中;如果不相等,仅将此次读取到的消息转移到 Q3。
结论:
- 通常在负载正常时,如果消息被消费的速度不小于接收新消息的速度,对于不需要保证可靠不丢失的消息来说,极有可能只会处于 alpha 状态。
- 对于 durable 属性设置为 true 的消息一定会进入 gamma 状态,并且在开启 publisher confirm机制时,只有到了 gamma 状态时才会确认该消息已被接收。
- 若消息消费速度足够快、内存也充足,这些消息也不会继续走到下一个状态。
影响及应对措施:
- 在系统负载较高时,已接收到的消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,这样会增加处理每个消息的平均开销。因为要花更多的时间和资源处理“堆积”的消息,如此用来处理新流入的消息的能力就会降低,使得后流入的消息又被积压到很深的队列中继续增大处理每个消息的平均开销,继而情况变得越来越恶化,使得系统的处理能力大大降低。
- 应对这一问题一般有 3 种措施:
- 增加 prefetch_count值,即一次发送多条消息给消费者,加快消息被消费的速度。这个值跟消息分发有关,开发人员代码中使用设置。
- 采用 multiple ack,降低处理 ack 带来的开销。可以回顾消费端的确认机制,也是开发人员设置。
- 流量控制。
二、惰性队列
当生产者将消息发送到RabbitMQ的时候,队列中的消息会尽可能地存储在内存之中,这样可以更加快速地将消息发送给消费者。即使是持久化的消息,在被写入磁盘的同时也会在内存中驻留一份备份。当RabbitMQ需要释放内存的时候,会将内存中的消息换页至磁盘中,这个操作会耗费较长的时间。
惰性队列会将收到的消息直接存入文件系统中,而不管是持久化的或者是非持久化的。这样减少了内存的消耗,但是会增加I/O的使用,如果消息是持久化的,那么这样的I/O操作不可避免。
注意如果惰性队列中存储的是非持久化的消息,内存的使用率会一直很稳定,但是重启后消息一样会丢失。
代码设置惰性队列
在队列声明的时候可以通过x-queue-mode 参数来设置队列的模式,取值为default和lazy。下面示例演示了一个惰性队列的声明细节:
Map<String,Object> args = new HashMap<String,Object>();
args.put( "x-queue-mode" , "lazy");
channel.queueDeclare( "myqueue" , false , false , false , args);
对应的Policy 设置方式为:
rabbitmqctl set_policy Lazy "^myqueue$ " ' {"queue-mode ":" lazy" } ' --apply-to-queues
如果要将普通队列转换为隋性队列,那么我们需要忍受性能损耗,需要将缓存中的消息转存到磁盘中,然后才能接收新的消息。反之,将一个惰性队列转为普通队列,会将磁盘中的消息批量地导入到内存中。
这篇关于【RabbitMQ 实战】11 队列的结构和惰性队列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






