本文主要是介绍新SQL Server 2019函数Approx_Count_Distinct,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL Server 2019 has a rich set of enhancements and new features. In particular, there are many new feature improvements in the database engine for better performance and query tuning.
SQL Server 2019具有一组丰富的增强功能和新功能。 特别是,数据库引擎中进行了许多新功能改进,以实现更好的性能和查询调整。
Some of the important enhancements are:
一些重要的增强功能包括:
- Row mode memory grant feedback 行模式内存授予反馈
- Batch mode over row store 行存储上的批处理模式
- APPROX_COUNT_DISTINCT APPROX_COUNT_DISTINCT
- Compatibility level hints 兼容性级别提示
- Enhancements to columnstore index such as an online rebuild, compression estimates 列存储索引的增强,例如在线重建,压缩估计
- Certificate management in the configuration manager 配置管理器中的证书管理
- Database classification improvements 数据库分类改进
In this article, we are going to talk about the Approx_Count_Distinct function. This function was available in Azure SQL Database previously but has been launched now with SQL Server 2019.
在本文中,我们将讨论Approx_Count_Distinct函数。 此功能以前在Azure SQL数据库中可用,但现在已随SQL Server 2019启动。
In a day-to-day environment, when we deal with data, there are many tables in the database that have duplicate values. For example, suppose a customer table holds records of all customers who buy a product from a store. As we know, the customer can buy the product multiple times and each time the customer visits the store and purchase goods, an entry is made into the customer table.
在日常环境中,当我们处理数据时,数据库中有许多表具有重复的值。 例如,假设一个客户表保存了从商店购买产品的所有客户的记录。 众所周知,客户可以多次购买产品,并且每次客户访问商店并购买商品时,都会在客户表中进行输入。
Now, suppose we want to know the unique customer’s information from our table so until now with SQL Server 2017, we use Count distinct function to get unique records. The format of count distinct function is as below.
现在,假设我们想从表中了解唯一客户的信息,因此直到现在,对于SQL Server 2017,我们都使用Count区分功能来获取唯一记录。 计数不同功能的格式如下。
SELECT COUNT (DISTINCT column-name) FROM table-name
First, let us prepare our sample database and table with millions of rows and then I will introduce you to a new function in SQL Server 2019 Approx_count_distinct.
首先,让我们准备具有数百万行的示例数据库和表,然后为您介绍SQL Server 2019 Approx_count_distinct中的新函数。
In this article, we’ll need to generate the millions of rows for test data for which I’ll use ApexSQL Generate
在本文中,我们将需要为我将使用ApexSQL Generate的测试数据生成数百万行。
For demo purpose, let us create two tables in the database.
出于演示目的,让我们在数据库中创建两个表。
- Employees table: 员工表:
CREATE Table Employees
(EMPId int identity primary key,EMP_name nvarchar(50) Null )
- Insert 2 million rows of random data 插入200万行随机数据
- We will insert any Null values in the table. 我们将在表中插入任何Null值。
- EmployeesWithNull:. EmployeesWithNull :。
CREATE Table EmployeesWithNull
(EMPId int identity primary key,EMP_name nvarchar(50) Null)
- Insert 2 million records in this table. 在此表中插入200万条记录。
- We will insert NULL values in this table 我们将在此表中插入NULL值
Approx_Count_Distinct函数概述 (Overview of Approx_Count_Distinct function)
SQL Server 2019 introduces the new function Approx_Count_distinct to provide an approximate count of the rows. Count(distinct()) function provides the actual row count. In a practical scenario, if we get approximate a distinct value also works. This new function gives the approximate number of rows and useful for a large number of rows.
SQL Server 2019引入了新函数Approx_Count_distinct以提供行的近似计数。 Count(distinct())函数提供实际的行数。 在实际情况下,如果我们获得近似值,那么也可以使用。 此新功能提供了大约的行数,对于大量的行很有用。
This function APPROX_COUNT_DISTINCT is supposed to use less memory and CPU resources so that data result can be obtained without any issues as spilling to disk or CPU spikes. This is useful for a requirement with billions of rows.
该函数APPROX_COUNT_DISTINCT应该使用较少的内存和CPU资源,以便可以获取数据结果而不会出现任何问题,如溢出到磁盘或CPU峰值。 这对于数十亿行的需求很有用。
As per Microsoft documentation, ‘The function implementation guarantees up to a 2% error rate within a 97% probability.’
根据Microsoft 文档 ,“函数实现可在97%的概率内保证高达2%的错误率。”
Syntax for Approx_Count_distinct is APPROX_COUNT_DISTINCT (expression)
Approx_Count_distinct的语法为APPROX_COUNT_DISTINCT(表达式)
Let us perform some comparison in both the count (distinct).
让我们对两个计数(不同)进行一些比较。
Get the count of distinct records from ‘dbo.employees’ table and view the actual execution plan
从“ dbo.employees”表中获取不同记录的计数并查看实际执行计划
View the stats as well from the count distinct function.
还可以从计数不同功能中查看统计信息。
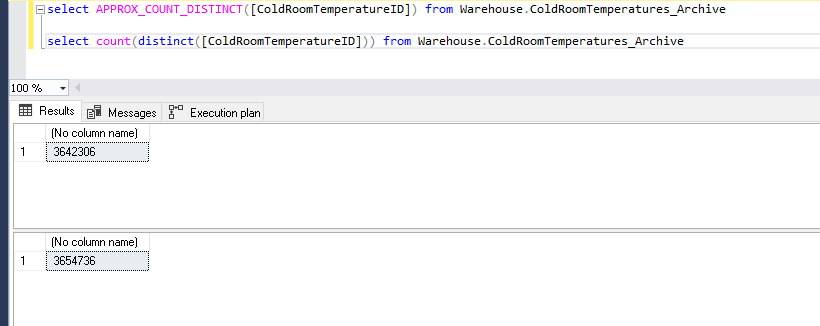
View the output record count. Its shows 2 million of distinct records in the table.
查看输出记录数。 它在表中显示200万个不同的记录。
Save the execution plan by right click, ‘Save Execution Plan As’ and provide the location to save it.
通过右键单击“将执行计划另存为”来保存执行计划,并提供保存位置。
Now run the below query using the SQL Server 2019 function APPROX_COUNT_Distinct.
现在使用SQL Server 2019函数APPROX_COUNT_Distinct运行以下查询。
SET STATISTICS TIME ON
select APPROX_COUNT_DISTINCT(EMPID) from [dbo].[Employees]
Notice the number of records. It says 205,580 records while our table only contains 2 million rows. It shows that we are not getting the exact count of distinct values, it is approximate.
注意记录数。 它说205,580条记录,而我们的表仅包含200万行。 它表明我们没有得到不同值的准确计数,而是近似值。
Right click on execution plan and click ‘Compare Showplan’
右键单击执行计划,然后单击“比较显示计划”
In Compare showplan provide the previously saved execution plan path
在“比较显示计划”中,提供先前保存的执行计划路径
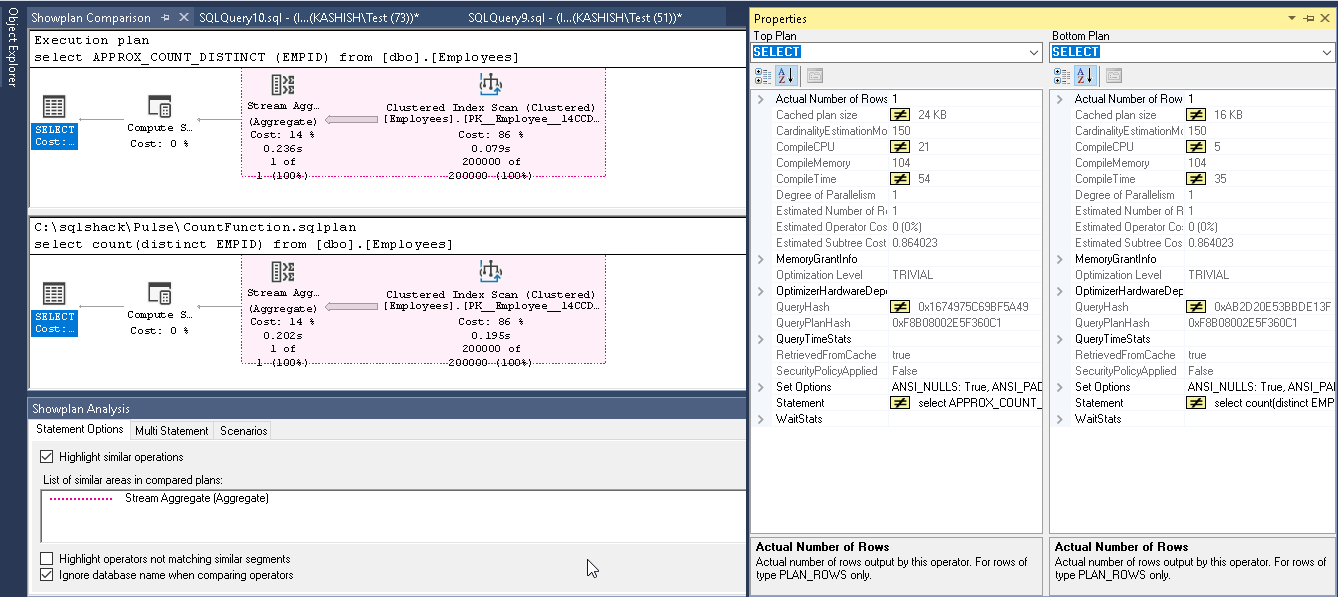
Now we can see a comparison of both Count (Distinct) and Approx_Count_distinct. Both the execution plan looks the same. In Approx_Count_distinct, we can see small improvement of clustered index scan time 0.079 seconds compared with 0.195 seconds using count (distinct)
现在我们可以看到Count(离散)和Approx_Count_distinct的比较。 两种执行计划看起来都一样。 在Approx_Count_distinct中,与使用count(distinct)的0.195秒相比,可以看到聚簇索引扫描时间为0.079秒的微小改进。
Now, if we compare the select operator in both the execution plan, in my result set below, we see little bit high values in the Approx_count_distinct function. For example, cache plan size, compileCPU, Compilememory, compile-time is high when we use the new function.
现在,如果我们在两个执行计划中比较select运算符,则在下面的结果集中,我们在Approx_count_distinct函数中看到的值有点高。 例如,当我们使用新功能时,缓存计划大小,compileCPU,Compilememory,编译时间很高。
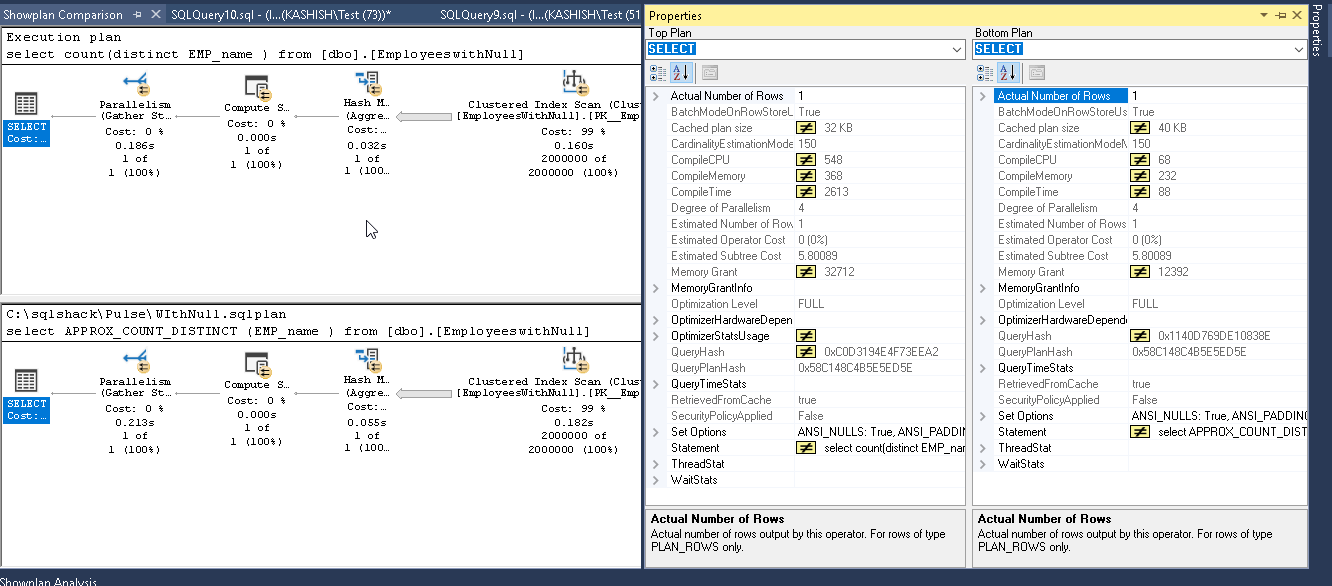
Let us perform the same test on our table with Null values.
让我们在表上使用Null值执行相同的测试。
We can see the below result in execution plan comparison report.
在执行计划比较报告中可以看到以下结果。
Rows count are again high as compare to the count distinct function.
与计数不同功能相比,行计数再次高。
Let us insert more records into both the table and refresh our data.
让我们在表中插入更多记录并刷新数据。
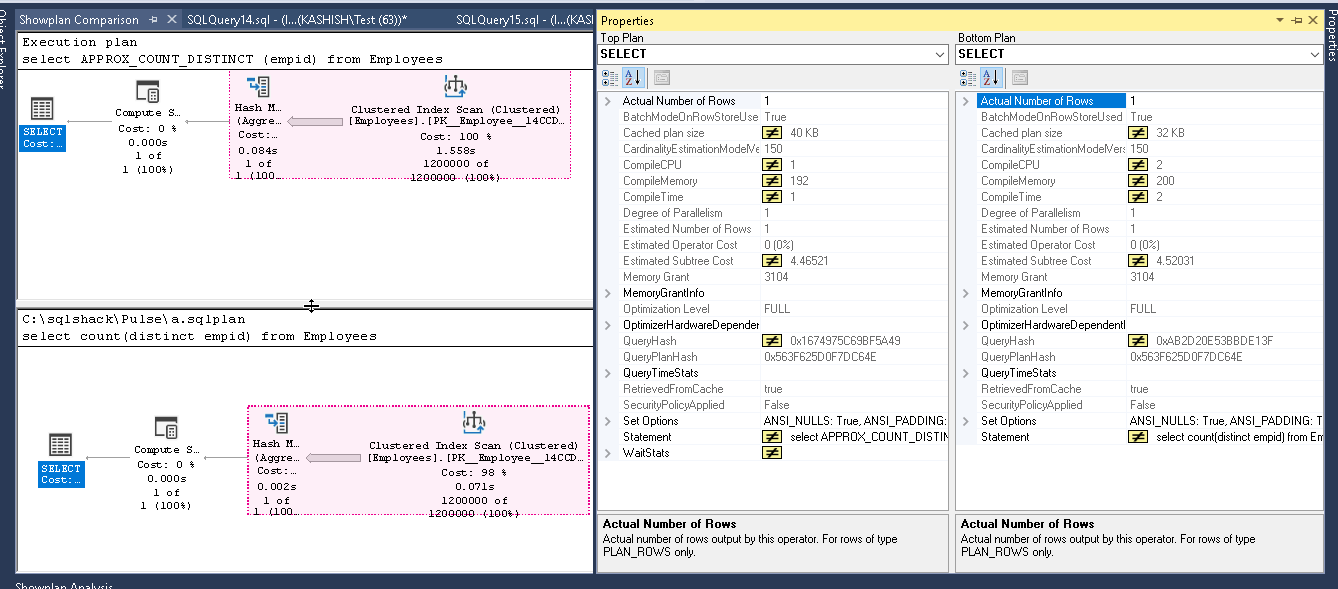
If we compare both the execution plan now, we can see little performance improvement while using the APPROX_COUNT_DISTINCT function.
如果现在比较两个执行计划,则使用APPROX_COUNT_DISTINCT函数时,性能几乎不会提高。
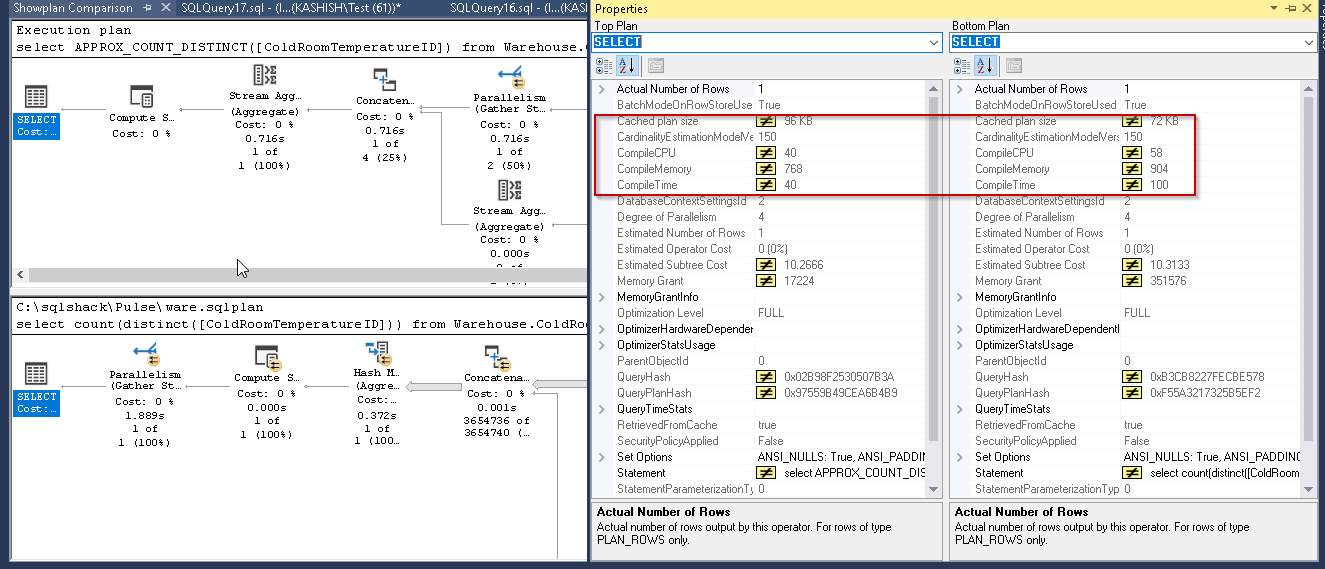
Let us do one more test against the sample database WideWorldImporters. Here in the comparison report, we found fewer values for CompileCPU, CompileMemory, and CompileTime while using the Approx_Count_distinct as compared with count distinct.
让我们再对示例数据库WideWorldImporters进行测试。 在比较报告中,我们发现使用Approx_Count_distinct时,CompileCPU,CompileMemory和CompileTime的值较少,而计数不同。
You can see the difference in row count in both the methods. Most of the time in my demo, I saw high row counts with new function however here we can see lower value than the actual but that is 0.34% approximate than the actual.
您可以在两种方法中看到行数的差异。 在我的演示中,大多数时候我都看到带有新功能的高行数,但是在这里我们可以看到比实际值低的值,但比实际值低0.34%。
Let us start the default extended event session ‘standard’ before running both the queries to capture the live trace of performance. Expand the XEvent profiler from SQL Server Management Studio and launch session.
让我们在运行两个查询以捕获实时性能跟踪之前启动默认的扩展事件会话“标准”。 从SQL Server Management Studio展开XEvent分析器,然后启动会话。
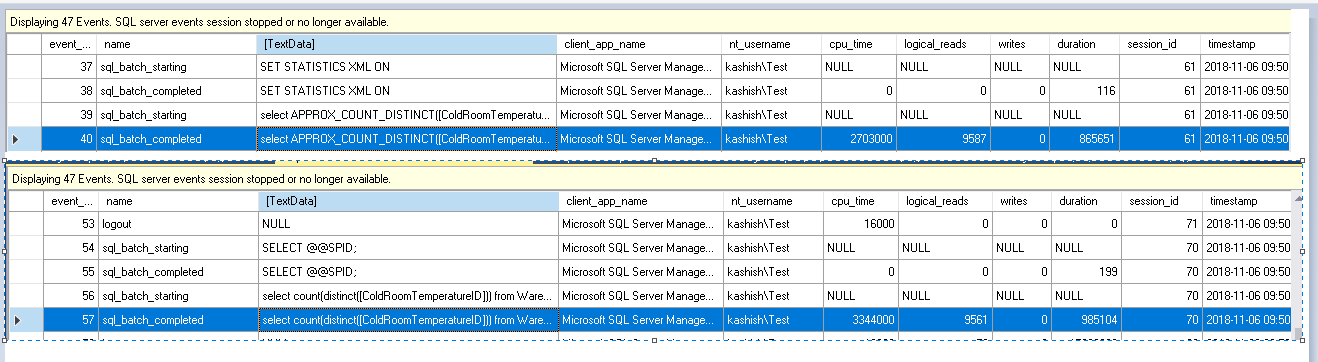
This captures the logical reads, CPU time, writes, duration.
这将捕获逻辑读取,CPU时间,写入,持续时间。
We can notice that values are lower while using the Approx_count_distinct as compare with the count distinct function.
我们可以注意到,使用Approx_count_distinct时,其值与count count函数相比要低一些。
结论 (Conclusion)
We explore the new functionality of getting an approximate count of distinct nonnull values in SQL Server 2019. During my test, I got mixed results in terms of performance however you can try running in more complex data scenario. Feel free to leave any feedback or questions in the comments below.
我们探索了在SQL Server 2019中获得近似计数的不同非空值的新功能。在我的测试期间,我在性能方面得到了混合的结果,但是您可以尝试在更复杂的数据方案中运行。 随时在下面的评论中留下任何反馈或问题。
翻译自: https://www.sqlshack.com/the-new-sql-server-2019-function-approx_count_distinct/
这篇关于新SQL Server 2019函数Approx_Count_Distinct的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}