本文主要是介绍python爬虫练手项目之获取某地企业名录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因为很多网站都增加了登录验证,所以需要添加一段利用cookies跳过登陆验证码的操作
import pandas as pd
import requests
from lxml import etree
# 通过Chrome浏览器F12来获取cookies,agent,headers
cookies ={'ssxmod_itna2':'eqfx0DgQGQ0QG=DC8DXxxxxx','ssxmod_itna':'euitGKD5iIgGxxxxx'}
agent ='Mozilla/5.0 (Windows NT 10.0; Win64; x64)xxxxxxx'headers = {'User-Agent' : agent,'Host':'www.xxx.com','Referer':'https://www.xxx.com/'
}
#建立会话
session = requests.session()
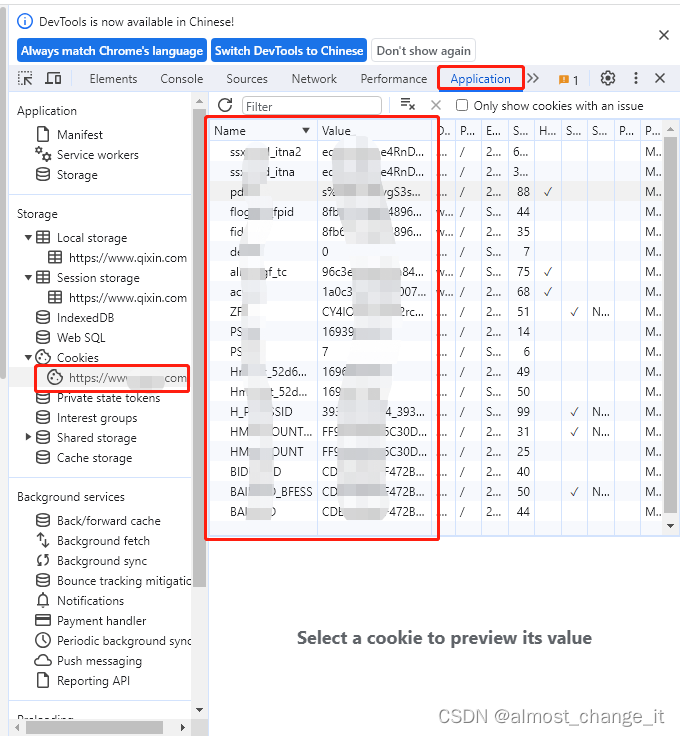
session.headers = headerscookies获取方式
chrmoe浏览器,F12,把name和value填入cookies
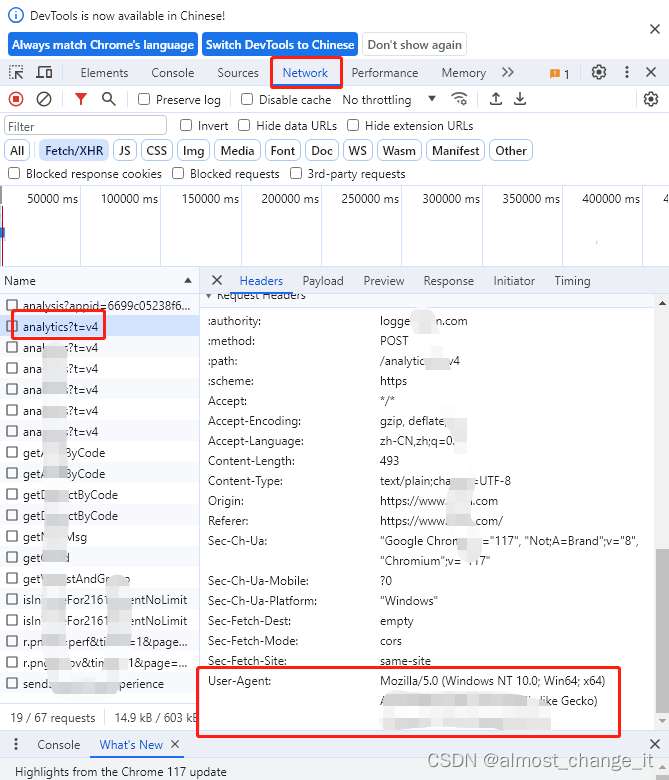
agent获取方式
任意点击一条网络资源,右侧headers往下翻到底
测试访问是否成功
#↓此处测试访问是否成功,成功的话返回码200
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
url = 'https://www.qixin.com/search-prov/36/3604/p1'
response=session.get(url)
print(response)访问成功的话进入下一步
#初始化df数据
df = pd.DataFrame(columns = ['企业名称'])#观察翻页后网址变化规律,取10页数据
for k in range(10): url = 'https://www.xxx.com/search-prov/36/3604/p' + str(k+1) + '/' cookies_dict = requests.utils.add_dict_to_cookiejar(session.cookies, cookies)page_text = requests.get(url, headers = headers, cookies = cookies_dict).text # GET#print(page_text)tree = etree.HTML(page_text) #数据解析#取到企业名对应xpathname = [i for i in tree.xpath("//div[@class='company-title font-18 font-f6']/a/text()")]dic = {'企业名称':name}df1 = pd.DataFrame(dic)df = pd.concat([df,df1], axis=0)#print(df)
print('全部数据爬取成功')
print(df)最后将结果导入csv文件
#将df数据写入csv文件
df.to_csv('xx企业名录.csv',index=None,encoding = 'utf-8-sig')这篇关于python爬虫练手项目之获取某地企业名录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






