本文主要是介绍python+selenium的web自动化测试之8种元素定位方式详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
单一属性定位
通过元素的id
通过元素的name
通过元素的class
通过元素的标签名
通过元素的超链接文本
通过元素的部分超链接文本
XPTH定位
CSS定位
辅助定位工具
前言
我们在做WEB自动化时,最根本的就是操作页面上的各种元素,而操作的基础便是元素的定位,只有准确地定位到唯一元素才能进行后续的自动化控制,下面将对各种元素定位方式进行总结归纳。
说明:以下操作统一使用百度首页<www.baidu.com>进行示例,鼠标右键然后点击检查(或按f12)可以查看具体的前端代码。
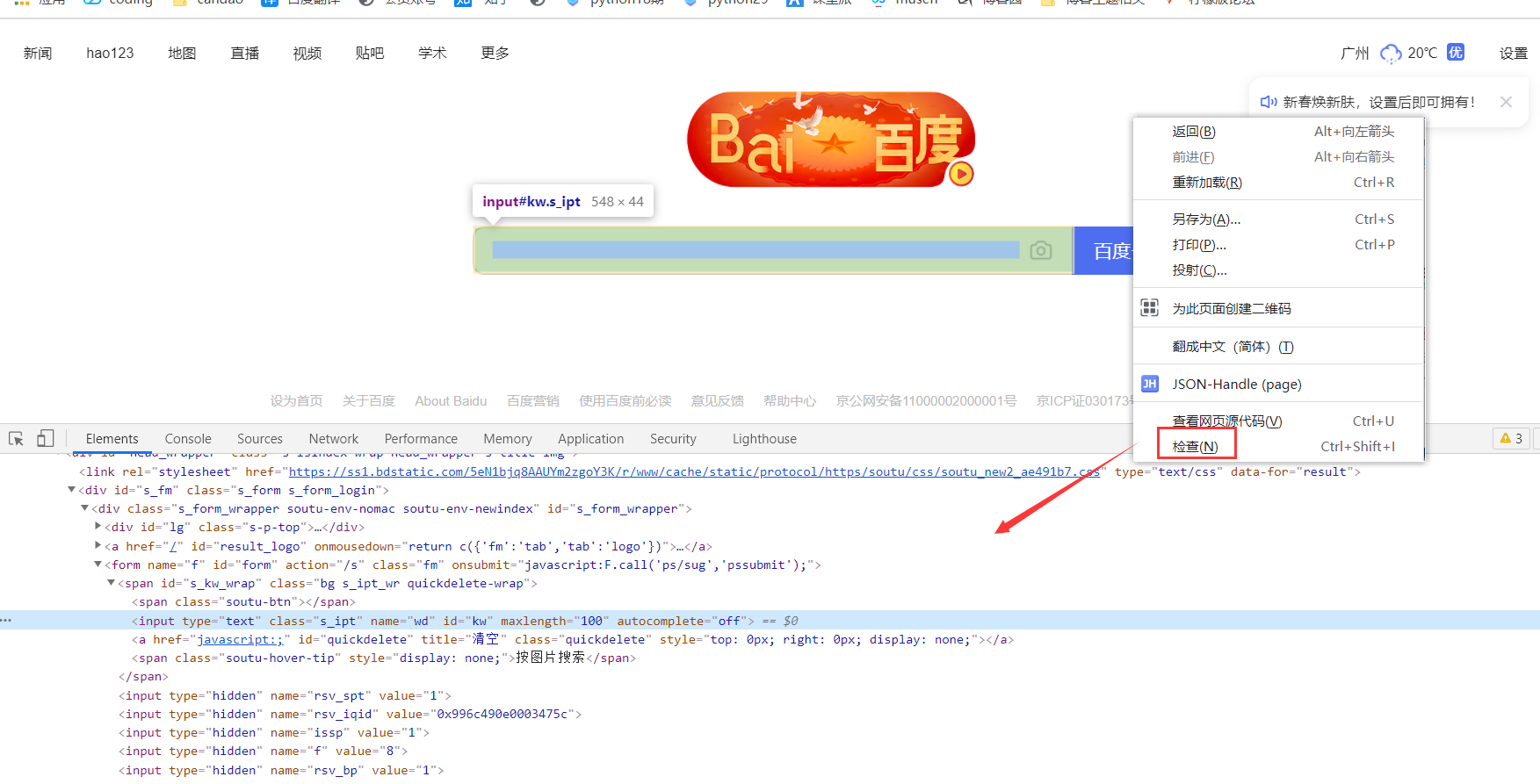
单一属性定位
6种单一属性定位 : id,name,class name,tag name,link,partial_link
2种多样式定位:css、xpath(强烈推荐)
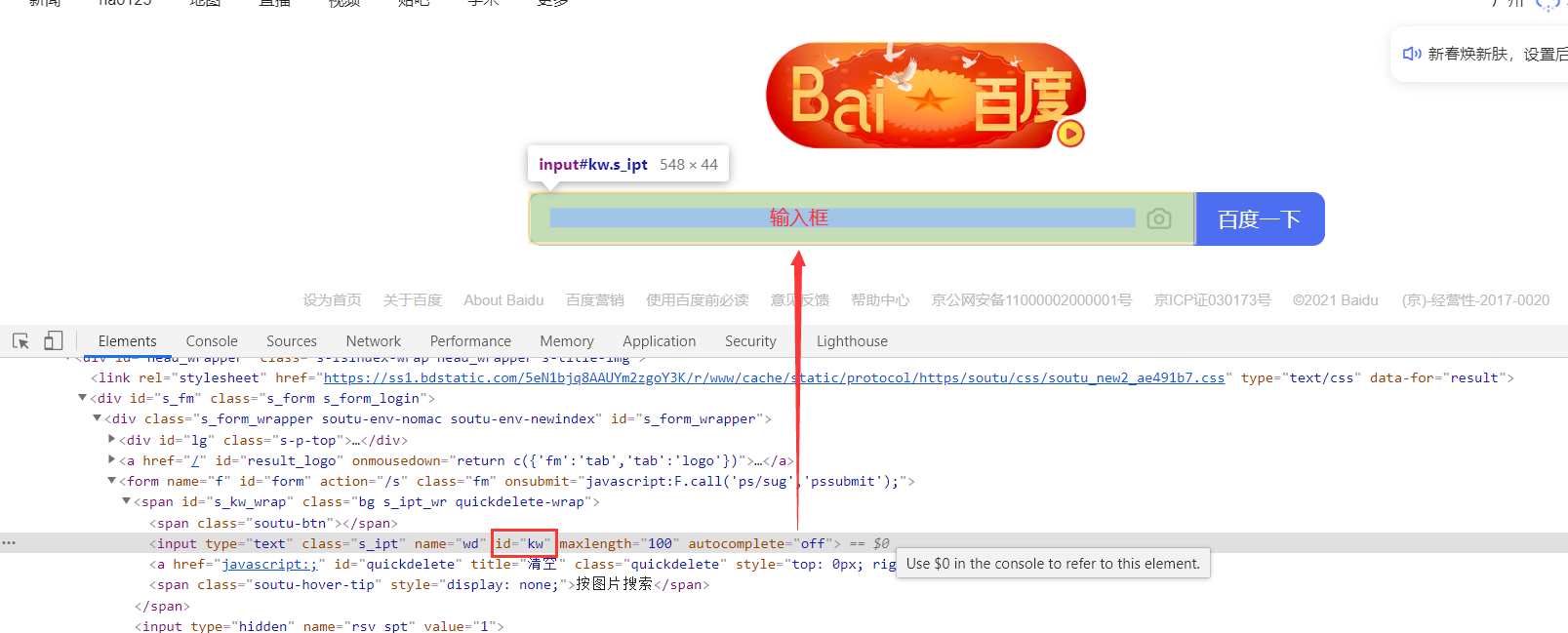
通过元素的id
<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过id(id唯一)</em></span>
ele = driver.find_element_by_id(<span style="color:#98c379">"kw"</span>) <span style="color:#b18eb1"><em># 类 WebElement - 属性、方法</em></span>
<span style="color:#e6c07b">print</span>(ele.get_attribute(<span style="color:#98c379">'class'</span>)) <span style="color:#b18eb1"><em># 获取该id的class属性值</em></span>
ele.send_keys(<span style="color:#98c379">"selenium"</span>) <span style="color:#b18eb1"><em># 发送内容</em></span></span></span> 在前端页面中,id是指页面匀速的的属性名id值,元素的id值在当前整个HTML页面中是唯一的,因此可以通过id属性来唯一定位一个元素,是首选的元素定位方式,但不是每个元素都有id属性。此外,也有动态变化的id值,即每次进入页面该元素的id值都不一样,一般是由一串英文+数字组成的字符串,这种情况下就不要使用id去定位元素了(因为下一次很有可能就找不到它了)。
通过元素的name

<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过name</em></span>
driver.find_element_by_name(<span style="color:#98c379">"wd"</span>) <span style="color:#b18eb1"><em># 不一定唯一 # elements</em></span></span></span> 元素的name属性,但name不一定是唯一的,就像大家的身份证号是唯一的,但是名字会有重复。driver.find_element_by_name只返回第一个匹配到的元素,如果想返回所有匹配到该name的元素,则使用driver.find_elements_by_name,区别就是element带不带s。这里特别说明一下,find_elements不管找到多少个,都会返回 一个list(找不到则返回空列表),列表当中的每一个元素就是一个 WebElement。
通过元素的class
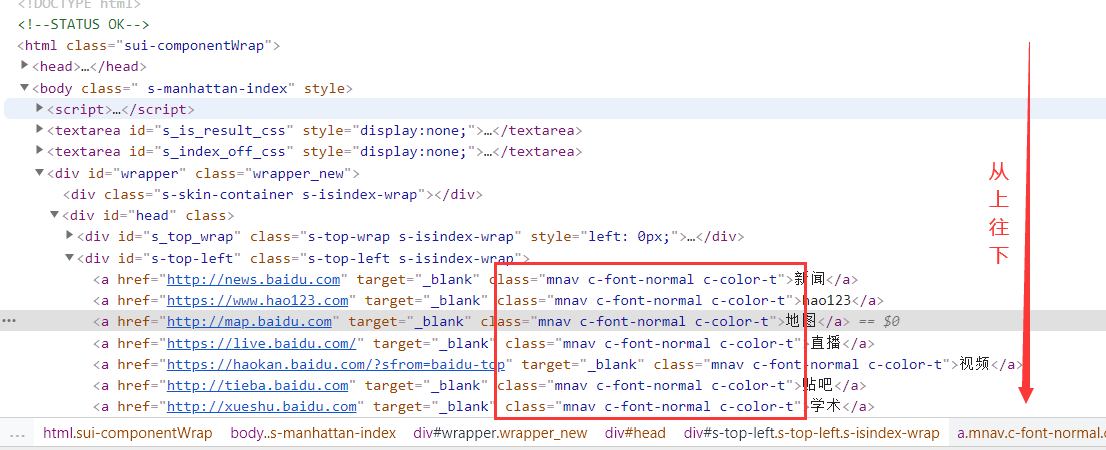
<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过class_name</em></span>
driver.find_element_by_class_name(<span style="color:#98c379">'mnav c-font-normal c-color-t'</span>) <span style="color:#b18eb1"><em># 不一定唯一,只返回匹配到的第一个元素</em></span>
driver.find_elements_by_class_name(<span style="color:#98c379">'mnav c-font-normal c-color-t'</span>) <span style="color:#b18eb1"><em># 返回元素列表,按照dom树从上往下</em></span></span></span> 元素的class属性,在前端,class一般是用来元素进行分组的,并对这一级元素设置相同的样式,因此会存在多个元素会共用一个class,不一定是唯一值。与name一样,element带s时返回匹配到的元素列表。
通过元素的标签名

<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过tag_name</em></span>
driver.find_element_by_tag_name(<span style="color:#98c379">'span'</span>) <span style="color:#b18eb1"><em># 不唯一 # elements</em></span></span></span> tag就是元素的标签标识,不一定是唯一值,element带s时返回匹配到的元素列表。
通过元素的超链接文本

<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过link_text</em></span>
driver.find_element_by_link_text(<span style="color:#98c379">'hao123'</span>) <span style="color:#b18eb1"><em># 不是唯一 # elements</em></span></span></span> 精确匹配链接的文本值,不一定是唯一值,element带s时返回匹配到的元素列表。
通过元素的部分超链接文本
<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#b18eb1"><em># 通过partial_link_text</em></span>
driver.find_element_by_partial_link_text(<span style="color:#98c379">'hao'</span>) <span style="color:#b18eb1"><em># 不是唯一 # elements</em></span></span></span> 模糊匹配链接的文本值,element带s时返回匹配到的元素列表。
XPTH定位
以上介绍的6中定位方式,都是针对元素的单一特征来定位元素,但在实际应用中,一般都需要组合以上各种情况来定位一个元素。那么xpath和css定位就可以实现各种组合,基本可以覆盖所有的元素定位。
xpath是一门在xml文档中查找信息的语言,因为html与xml比较相似,用得比较广泛,所以xpath也可以用于在html对元素进行定位。它是将整个html看成一个树形结构,html为根节点,页面当中节点与其他节点可以有祖先、父辈、兄弟、这样的关系,类似一个族谱。
selenium提供的xpath定位的方法名:find_element_by_xpath(xpath表达式),表达式语法如下:
| 表达式 | 说明 |
|---|---|
| / | 绝对定位,从根节点选取 |
| // | 相对定位,选择匹配的节点 |
| . | 选择当前节点 |
| .. | 选择当前节点的父节点 |
| @ | 选择属性,如:@class="class值",@id="id值",属性放在中括号[]中 |
| * | 通配符,匹配所有 |
| @* | 通配符,匹配所有属性,如:@*="test" |
- 绝对定位(不建议) : /单斜杠开头,严格按照层级、同级元素的位置,只要位置改变就无法定位,如:/html/body/div[2]/[form]/div[1]/input
- 相对定位://双斜杠开头 ,在参照物之下只要符合条件的元素存在即可,表达式:
//标签名[@属性名=值],用*表示要匹配所有标签 ,如://*[@id="kw"] 匹配所有标签 - 下标定位(不建议):路径下相同标签的下标,如://*[@id="th"]/a[2],意思是该路径下第二个a标签
- 逻辑运算:表达式中可以使用and 、or 描述元素的多个属性,表达式:
//标签名[@属性名=值 and @属性名=值] - 层级定位:靠本身特性无法唯一定位的时候,使用层级去定位,如:
//div[@id="u1"]//a[@name="tj_login"]。/(单斜杠)表示在前一个元素的直系下, //(双斜杠)表示在前个元素之下的所有范围内 - 文本定位: 通过标签内的文本内容,表达式:
//标签名[text()="文本"] - 包含(部分属性):标签的部分属性,表达式:
//标签名[contains(@属性名 , "部分属性值")],如: //a[contains(@href,"Cource/homework")],部分文本也可以,//a[contains(text(), "部分文本")] - 轴定位:一般用于表格样式的数据列,需要通过组合来进行定位,轴运算名称为以下6种,使用语法:
/轴名称::节点名称[@属性=值],例: //div//table//td/preceding::td,只要后面接的是轴定位要用/(单斜杠)。- 👉ancestor:祖先节点,父
- 👉parent:父节点
- 👉preceding:当前元素节点标签之前的所有节点(html页面先后顺序)
- 👉preceding-sibling:当前元素节点标签之前的所有兄弟节点
- 👉following:当前元素节点标签之后的所有节点(html页面先后顺序)
- 👉following-sibling:当前元素节点标签之后的所有兄弟节点
<span style="background-color:#282c34"><span style="color:#abb2bf"><span style="color:#f92672">from</span> selenium <span style="color:#f92672">import</span> webdriver
<span style="color:#f92672">import</span> timedriver = webdriver.Chrome()
driver.get(<span style="color:#98c379">"https://www.baidu.com"</span>)<span style="color:#b18eb1"><em># 定位到输入框并输入搜索内容</em></span>
driver.find_element_by_xpath(<span style="color:#98c379">"//input[@id='kw']"</span>).send_keys(<span style="color:#98c379">"selenium"</span>)
<span style="color:#b18eb1"><em># 定位到百度按钮,并点击</em></span>
driver.find_element_by_xpath(<span style="color:#98c379">"//input[@class='btn self-btn bg s_btn']"</span>).click()
time.sleep(<span style="color:#d19a66">5</span>)<span style="color:#b18eb1"><em># 关闭浏览器</em></span>
driver.quit()</span></span>CSS定位
css定位也可以较为灵活地选择控件的任意属性,一般情况下定位速度要比xpath要快,但比较复杂,这里只做简单介绍。有兴趣的可以深入了解。
| 选择器 | 例子 | 描述 |
|---|---|---|
| class | .intro | class选择器,选择class="intro"的所有元素 |
| #id | #firstname | id选择器,选择id= " firstname"的所有元素 |
| * | * | 选择所有元素 |
| element | p | 元素所有<p>元素 |
| element > element | div > input | 选择父元素为<div>的所有<input> 元素 |
| element + element | div + input | 选择同一级中紧接在<div> 元素之后的所有<input> 元素 |
| [attribute= value] | [target=_blank] | 选择target="_blank"的所有元素。 |
以百度输入框和搜索框为例:
- 🍄 find_element_by_css_selector(".s_ipt") #通过class属性定位
- 🍄 find_element_by_css_selector("#kw") #通过id属性
- 🍄 find_element_by_css_selector("input") #通过标签名
- 🍄 find_element_by_css_selector("span>input") #通过父子关系定位,查找span所有标签名叫input的子元素
- 🍄 find_element_by_css_selector("[name='kw']") #通过属性定位
- 🍄 find_element_by_css_selector("span.bg s_ipt_wr>input.s_ipt") #组合定位,父元素是span标签名,class属性是.bg s_ipt_wr,有一个子元素,标签名为input,class属性是s_ipt
辅助定位工具
快捷键f12调出浏览器的开发者工具 —— elements,或通过右击检查调出,以chrome浏览器为例,如下图,点击左上角箭头,再用鼠标点击页面中想要定位的元素,该元素所在代码行会高亮显示,crtl + f可以调出元素查找框,输入表达式,在输入框右边可以看到该表达式定位的元素是否存在且唯一,可以通过组合定位或者更换更具代表性的属性去保证定位到的元素是唯一的。
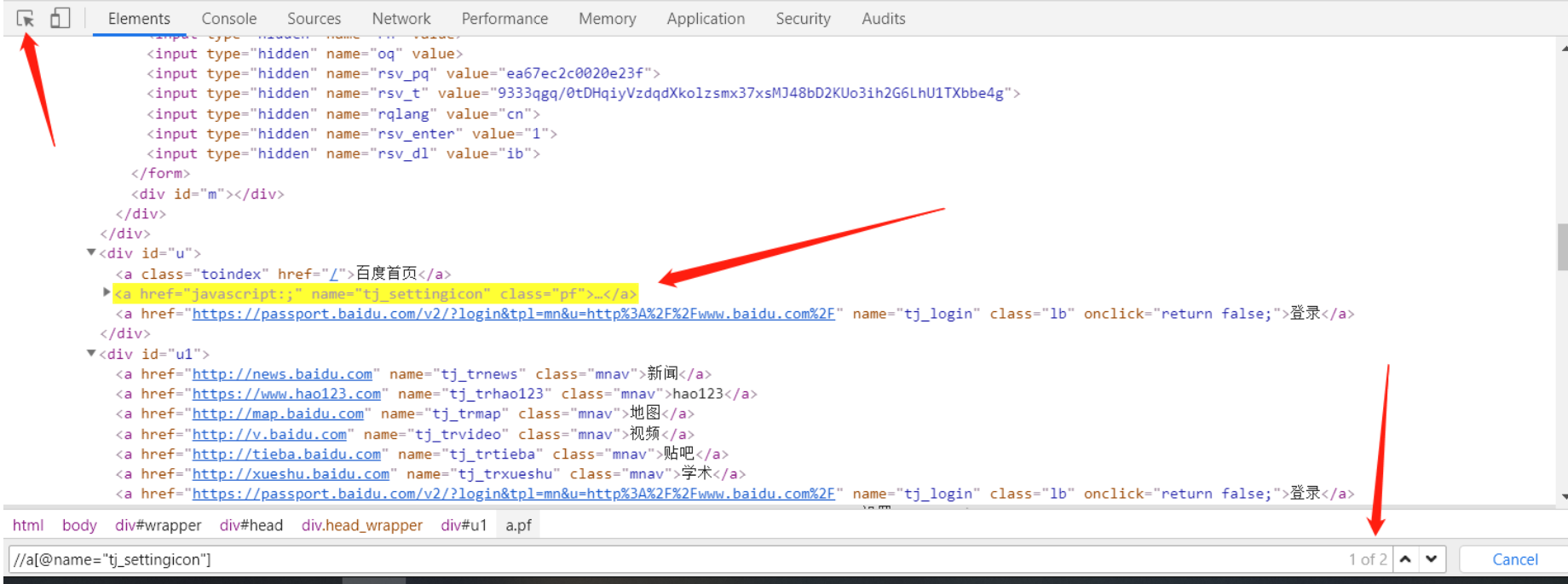
在上图的底部(搜索框对上一栏),选中元素后还可以看到元素的路径,可以用此判断元素是否在iframe表单中;而如果不确定元素是否在html里,可以利用字符串的元素查找,代码如下:
<span style="background-color:#282c34"><span style="color:#abb2bf">test = driver.page_source.find(<span style="color:#98c379">"<p>hello</p>"</span>)
<span style="color:#e6c07b">print</span>(test) <span style="color:#b18eb1"><em># 返回-1就是不存在</em></span></span></span>这篇关于python+selenium的web自动化测试之8种元素定位方式详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






