本文主要是介绍【12.23-12.24】Member Inference Attack,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、Repeated Knowledge Distillation with Confidence Masking to Mitigate Membership Inference Attacks
- 1.1 Member Inference Attack
- 2.2 Confidence Score Masking
- 2.3 Knowledge Distillation
- 二、Membership Inference Attacks Against Machine Learning Models
- 2.1 概述
- membership inference
- shadow model
- 过拟合
- 2.2 防御手段
- 2.3 相关工作
前言
` 了解到两篇关于Member Inference Attack 问题的论文并进行简单的整理。只是大致浏览了解描述的内容,具体实验过程没有深入研究。
第一篇论文来自CCS-机器学习安全和隐私会议(2022),描述了一种新的方法:基于KD+Confidence Masking的结合;第二篇也属于成员推断攻击的经典论文之一,介绍了什么是成员推断攻击,介绍了如何构造问题和一些防御手段。
一、Repeated Knowledge Distillation with Confidence Masking to Mitigate Membership Inference Attacks
Mitigate Membership Inference Attacks
1.1 Member Inference Attack
Member Inference Attack, 成员推测攻击;在针对在私有数据集 𝐷 上训练的模型 𝑓 ,攻击者被赋予一个特定的数据点 𝑥(可选地存在与其关联的真实标签 𝑦),并旨在找出 𝑥 是否是训练数据集的一部分𝑓的,即是否𝑥∈𝐷。
即决定给定的数据(data record)判断是否是目标模型(target model)的训练集。
两种场景:
1). black-box setting: 黑盒攻击,即攻击者可以获取模型的预测结果但不知道模型参数。Shokri et al.’s [17]
攻击者可以生成多个shadow models(攻击者可用的数据集【的子集】上训练的目标模型的副本);然后可以判断数据是否被训练进而评估获取预测结果。
paper [17]中所提到的 shadow training technique.
First, we create multiple “shadow models” that
imitate the behavior of the target model, but for which we
know the training datasets and thus the ground truth about
membership in these datasets. We then train the attack model
on the labeled inputs and outputs of the shadow models
shadow models被使用的越多,用于训练攻击模型数据的数据就越多,模型准确率越高。
2). white-box setting: 白盒攻击,即攻击者可以看到模型的架构和内部参数。Nasr et al.’s [13]
简言之,攻击者可以根据目标点对(x, y)计算模型的中间结果(前向/后向传播过程中的数值)
2.2 Confidence Score Masking
在黑盒攻击中,通常建设输出结果为对输入数据的似然概率。即输入数据在每一种分类的概率。
为了避免攻击者从输出结果中获取过多信息,可以采用下列方法:
- 对预测结果添加随机噪音
- 仅返回k个最有可能的分类
- 仅返回给用户相应的预测标签,不暴露额外数据。
2.3 Knowledge Distillation
存在两个模型:teacher model 和 student model,进行学习知识的迁移,通过使用teacher model的预测输出作为student model的训练数据,保证数据集的私有化。Shejwalkar et al. [16]
end-----
仅了解背景介绍,和基础知识铺垫;暂未看实验过程
二、Membership Inference Attacks Against Machine Learning Models
2.1 概述
membership inference
假设:对于输入,模型输出为一组vector of probabilities, 描述当前输入划分每一类的概率。该概率值被称为 confidence values;
认定攻击者可以接触目标模型,并能够获取目前模型给出的任意数据预测值。
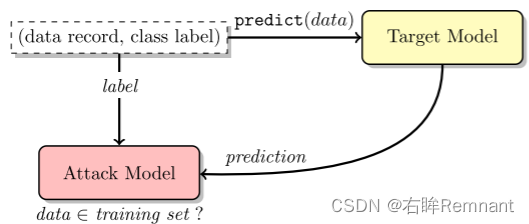
- 上图为黑盒攻击,即不知道模型内部架构,只能获取模型的输出预测;通过比较判断data record是否为训练数据。
- Attack model的目标是识别target model的差异性,并通过这种差异利用prediction识别member和non-member
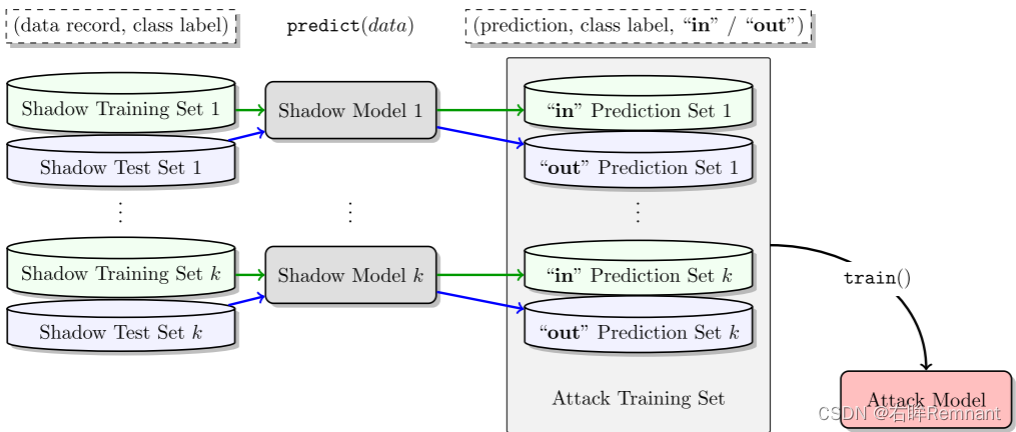
shadow model
用于构造attack model的一种方法;通过多个与target model 类型的模型称为shadow model,训练集D’为目标训练集D的子集进行构造。
假设用于训练影子模型的数据集与用于训练目标模型的私有数据集不相交 。这对攻击者来说是最坏的情况;如果训练数据集恰好重叠,则攻击的效果会更好。
对于训练shadow model的训练集D’,意味着攻击者需要构造与目标数据D分布类似的数据,
并不是说已知部分隐私数据。(下面生成数据的方法为主)
构造数据的手段
- Model-based synthesis: 利用目标模型合成数据
- Statistics-based synthesis:攻击者可能有一些关于从中提取目标模型训练数据的人群的统计信息
- Noisy real data: 攻击者可能有权访问一些与目标模型的训练数据相似的数据,并且可以被视为其“嘈杂”版本
过拟合
过度拟合并不是member inference attack起作用的唯一原因。不同的机器学习模型,由于其不同的结构,“记住”有关其训练数据集的不同信息量。即使模型过度拟合到相同程度,这也会导致不同数量的信息泄漏。
2.2 防御手段
- Restrict the prediction vector to top k classes
当类别很多的时候,往往大部分分类输出的概率很低;因此可以只选择输出概率最大的几类减少信息泄露的范围。 - Increase entropy of the prediction vector
结果粗化;将预测结果四舍五入,降低精度。 - Use regularization
该方法用于处理过拟合问题。 - Increase entropy of the prediction vector.
Increase entropy of the prediction vector also used in knowledge distillation and information transfer between models [20]
2.3 相关工作
这里提到的是对机器学习安全和隐私领域的其他研究进行概述。
- Attacks on statistical and machine learning models
首先, 可以推断数据集的统计信息。其次, 对手利用协作推荐系统输出的变化来推断导致这些变化的输入
- model inversion
应用于隐藏输入的模型输出来推断该输入的某些特征。
use the output of a model applied to a hidden input to infer certain features of this input
- Model extraction
- Privacy-preserving machine learning
这篇关于【12.23-12.24】Member Inference Attack的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





