本文主要是介绍Springboot给每个接口设置traceId,并添加到返回结果中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原理
slf4j有个MDC的类,是ThreadLocal的实现,保存在这里的变量会绑定到某个请求线程,于是在该请求的线程里的日志代码都可以使用设入的变量。
实现
一、引入依赖
这个是可选项,用于生成唯一uid,我人懒,就直接用这个工具,你们要自定义uid格式的,就可以不用导入。
<!-- hutool工具包 --><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.20</version></dependency>二、设置拦截器
因为要给每一个请求都利用所以建议利用MDC绑定traceId,所以需要用拦截器拦截每一个请求。
先给设置一个拦截器配置InterceptorConfig.class并实现重写WebMvcConfigurer,如下:
@Configuration
public class InterceptorConfig implements WebMvcConfigurer {/*** http请求拦截器* @param registry*/@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new TraceIdInterceptor());}
}里面的new TraceIdInterceptor()就是我们的核心配置类了,用于MDC绑定traceId到线程中,首先,新建一个TraceIdInterceptor.class,代码及注释如下:
@Component
public class TraceIdInterceptor implements HandlerInterceptor {/*** preHandle为请求前拦截*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 在日志框架中的MDC中添加请求的唯一标识(用于返回接口及保存mysql)String traceId = String.valueOf(UUID.randomUUID());// 绑定key值到线程中MDC.put("traceId", traceId);response.addHeader("traceId",traceId);// 继续执行接口请求return true;}
}三、设置返回体
然后通过【MDC.get("traceId")】实现获取traceId,这个可以用在统一返回的结果包装类里,如下:
/*** 接口返回统一包装*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {private String traceId;private Integer code;private String msg;private Object data;/*** 成功,且返回体有数据* @param code* @param msg* @param data* @return*/public static Result success(Integer code, String msg, Object data) {// 获取MDC中绑定的traceIdString traceId = MDC.get("traceId");return new Result(traceId, code, msg, data);}/*** 成功,但返回体没数据* @param code* @param msg* @return*/public static Result success(Integer code, String msg) {// 获取MDC中绑定的traceIdString traceId = MDC.get("traceId");return new Result(traceId, code, msg, null);}
}四、效果测试
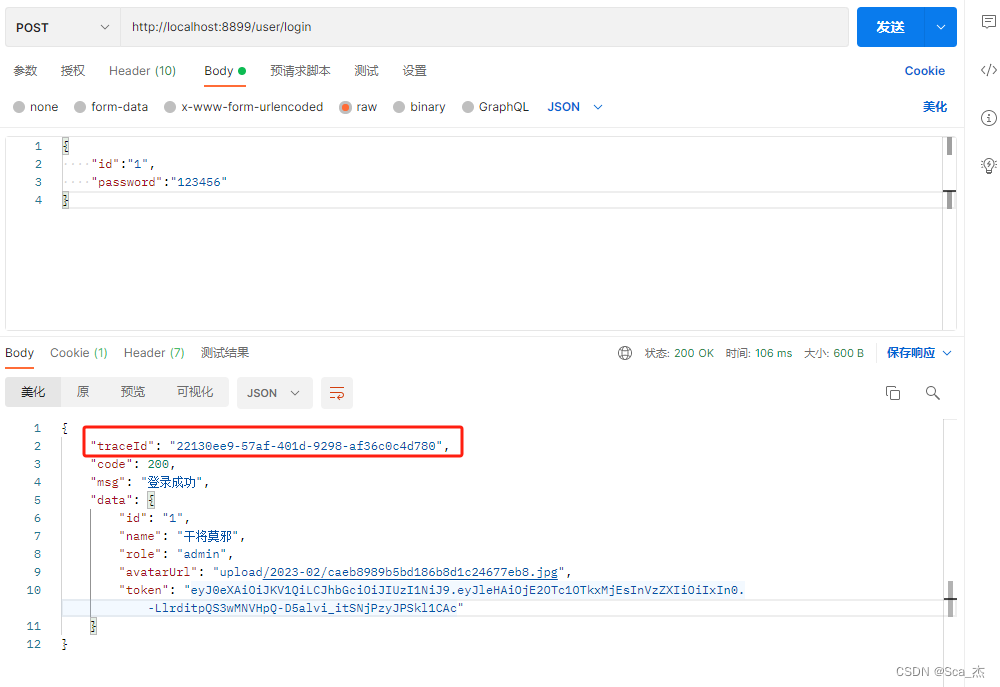
这篇关于Springboot给每个接口设置traceId,并添加到返回结果中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








