本文主要是介绍数仓DWS层之旁路缓存优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
优化原因:
外部数据源的查询常常是流式计算的性能瓶颈。以本程序为例,每次查询都要连接 Hbase,数据传输需要做序列化、反序列化,还有网络传输,严重影响时效性。可以通过旁路缓存对查询进行优化。
旁路缓存模式是一种非常常见的按需分配缓存模式。所有请求优先访问缓存,若缓存命中,直接获得数据返回给请求者。如果未命中则查询数据库,获取结果后,将其返回并写入缓存以备后续请求使用。
(1)旁路缓存策略应注意两点
a)缓存要设过期时间,不然冷数据会常驻缓存,浪费资源。
b)要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
(2)缓存的选型
一般两种:堆缓存或者独立缓存服务(memcache,redis)
堆缓存,性能更好,效率更高,因为数据访问路径更短。但是难于管理,其它进程无法维护缓存中的数据。
独立缓存服务(redis,memcache),会有创建连接、网络IO等消耗,较堆缓存略差,但性能尚可。独立缓存服务便于维护和扩展,对于数据会发生变化且数据量很大的场景更加适用,此处选择独立缓存服务,将 redis 作为缓存介质。
(3)实现步骤
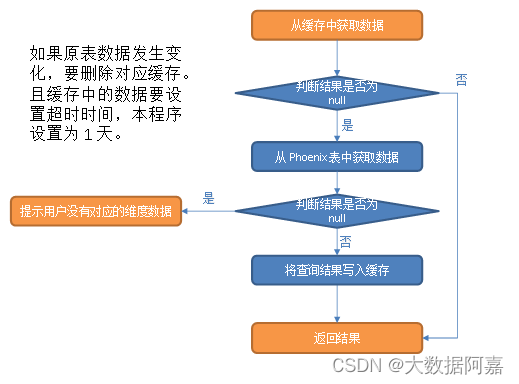
从缓存中获取数据。
① 如果查询结果不为 null,则返回结果。
② 如果缓存中获取的结果为 null,则从 Phoenix 表中查询数据。
a)如果结果非空则将数据写入缓存后返回结果。
b)否则提示用户:没有对应的维度数据
注意:缓存中的数据要设置超时时间,本程序设置为 1 天。此外,如果原表数据发生变化,要删除对应缓存。为了实现此功能,需要对维度分流程序做如下修改:
i)在 MyBroadcastFunction的 processElement 方法内将操作类型字段添加到 JSON 对象中。
ii)在 DimUtil 工具类中添加 deleteCached 方法,用于删除变更数据的缓存信息。
iii)在 MyPhoenixSink 的 invoke 方法中补充对于操作类型的判断,如果操作类型为 update 则清除缓存。
图解:
代码方面:
思路:当我们需要使用外部数据源的表数据时,在第一次使用的时候,从Phoenix获取维表数据,并且将这些维表数据写入Redis缓存中,在后面我们需要再次使用维表数据的时候,我们先可以从Redis中获取,如果Redis中没有,在从Phoenix中获取维表数据并且写入Redis缓存中,主要这里要设置缓存过期时间,要不然会造成冷数据,而浪费资源。当我们修改维表中的数据时,要先删除Redis缓存中的数据,然后再对Phoenix进行更新。
(1)创建连接池(与Phoenix建立连接,即与HBASE建立连接)
package com.atguigu.utils;import com.alibaba.druid.pool.DruidDataSource;
import com.atguigu.common.GmallConfig;public class DruidDSUtil {private static DruidDataSource druidDataSource=null;public static DruidDataSource createDataSource() {// 创建连接池druidDataSource = new DruidDataSource();// 设置驱动全类名druidDataSource.setDriverClassName(GmallConfig.PHOENIX_DRIVER);// 设置连接 urldruidDataSource.setUrl(GmallConfig.PHOENIX_SERVER);// 设置初始化连接池时池中连接的数量druidDataSource.setInitialSize(5);// 设置同时活跃的最大连接数druidDataSource.setMaxActive(20);// 设置空闲时的最小连接数,必须介于 0 和最大连接数之间,默认为 0druidDataSource.setMinIdle(1);// 设置没有空余连接时的等待时间,超时抛出异常,-1 表示一直等待druidDataSource.setMaxWait(-1);// 验证连接是否可用使用的 SQL 语句druidDataSource.setValidationQuery("select 1");// 指明连接是否被空闲连接回收器(如果有)进行检验,如果检测失败,则连接将被从池中去除// 注意,默认值为 true,如果没有设置 validationQuery,则报错// testWhileIdle is true, validationQuery not setdruidDataSource.setTestWhileIdle(true);// 借出连接时,是否测试,设置为 false,不测试,否则很影响性能druidDataSource.setTestOnBorrow(false);// 归还连接时,是否测试druidDataSource.setTestOnReturn(false);// 设置空闲连接回收器每隔 30s 运行一次druidDataSource.setTimeBetweenEvictionRunsMillis(30 * 1000L);// 设置池中连接空闲 30min 被回收,默认值即为 30 mindruidDataSource.setMinEvictableIdleTimeMillis(30 * 60 * 1000L);return druidDataSource;}
}
(二)先判断Redis缓存是否有数据,如果没有,则从Phoenix获取维表数据并且将在Phoenix中查到的数据放入Redis缓存中
package com.atguigu.utils;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.common.GmallConfig;
import redis.clients.jedis.Jedis;import java.lang.reflect.InvocationTargetException;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;public class DimUtil {//启动Redis// bin/redis-server.sh ./redis.conf// bin/redis-cli -h hadoop107 --rawpublic static JSONObject getDimInfo(Connection connection,String tableName,String key) throws SQLException, InvocationTargetException, InstantiationException, IllegalAccessException {//先查询RedisJedis jedis = JedisUtil.getJedis();String redisKey="DIM"+tableName+":"+key;String dimJsonStr = jedis.get(redisKey);//如果Redis缓存中有数据,则从缓存中读取数据,如果没有,则从Phoenix(Hbase)中获取数据if(dimJsonStr!=null){//重置过期时间jedis.expire(redisKey,24*60*60);//归还连接jedis.close();//返回维表数据return JSON.parseObject(dimJsonStr);}else{//拼接SQL语句String querySql="select * from " + GmallConfig.HBASE_SCHEMA +"."+tableName+"where id="+ key+"'";System.out.println("querySql>>>"+querySql);//查询数据List<JSONObject> queryList = JdbcUtil.queryList(connection, querySql, JSONObject.class, false);//将从Phoenix查询到的数据写入RedisJSONObject dimInfo = queryList.get(0);jedis.set(redisKey, dimInfo.toJSONString());//设置过期时间jedis.expire(redisKey,24*60*60);//归还连接jedis.close();//返回结果return dimInfo;}}//删除Redis中的缓存数据public static void delDimInfo(String tableName,String key){//获取连接Jedis jedis = JedisUtil.getJedis();//删除数据jedis.del("DIM"+tableName+":"+key);//归还连接jedis.close();}}
(三)当维表数据更新时,需要删除Redis对应的维表数据(删除方法在上一段代码中)
package com.atguigu.app.func;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.utils.DimUtil;
import com.atguigu.utils.DruidDSUtil;
import com.atguigu.utils.PhoenixUtil;import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.SQLException;public class DimSinkFunction extends RichSinkFunction<JSONObject> {private static DruidDataSource druidDataSource=null;@Overridepublic void open(Configuration parameters) throws Exception {druidDataSource = DruidDSUtil.createDataSource();}/*主流数据value数据格式:(消费的topic_db){"database":"gmall-211126-flink","table":"base_trademark","type":"insert","ts":1652499161,"xid":167,"commit":true,"data":{"id":13,"tm_name":"atguigu","logo_url":"/aaa/aaa"}}*/@Overridepublic void invoke(JSONObject value, Context context) throws Exception {//获取连接DruidPooledConnection connection = druidDataSource.getConnection();String sinkTable=value.getString("sinkTable");JSONObject data=value.getJSONObject("data");//获取数据类型String type=value.getString("type");//如果为更新类型,则需要删除Redis中的数据if("update".equals(type)){DimUtil.delDimInfo(sinkTable.toUpperCase(),data.getString("id"));}//写出数据PhoenixUtil.upsertValues(connection,sinkTable,data);//归还连接connection.close();}
}
这篇关于数仓DWS层之旁路缓存优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


