本文主要是介绍最大均值差异(Maximum Mean Discrepancy, MMD)复现教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文章主要为了复现这个MMD教程中的代码。
pytorch环境安装
下面参考pytorch的官方教程。
这是安装pytorch的先决条件,如果需要用到GPU加速的话还需要下载CUDA驱动。(不过这个小项目就不用啦)

首先需要一个Anaconda做为package manager,为项目建立虚拟环境(因为不同项目对pytorch或者其他包的版本要求不同,不能兼容哦)。
之后要下载项目所需要的pytorch版本。如果项目中有说明具体的pytorch版本,最好下载对应的版本,会省很多问题。在这个MMD项目中没有明确说明版本,那么我们就选择pytorch1.1.0这个版本吧(1.1、1.2、1.4、1.5这几个版本的区别不太清楚,但是小版本改动不大。0.4的版本相比1.x的版本差别会大很多。1.6是最新的版本,一般新版本不太稳定不建议使用)。
然后点击跳转到先前版本
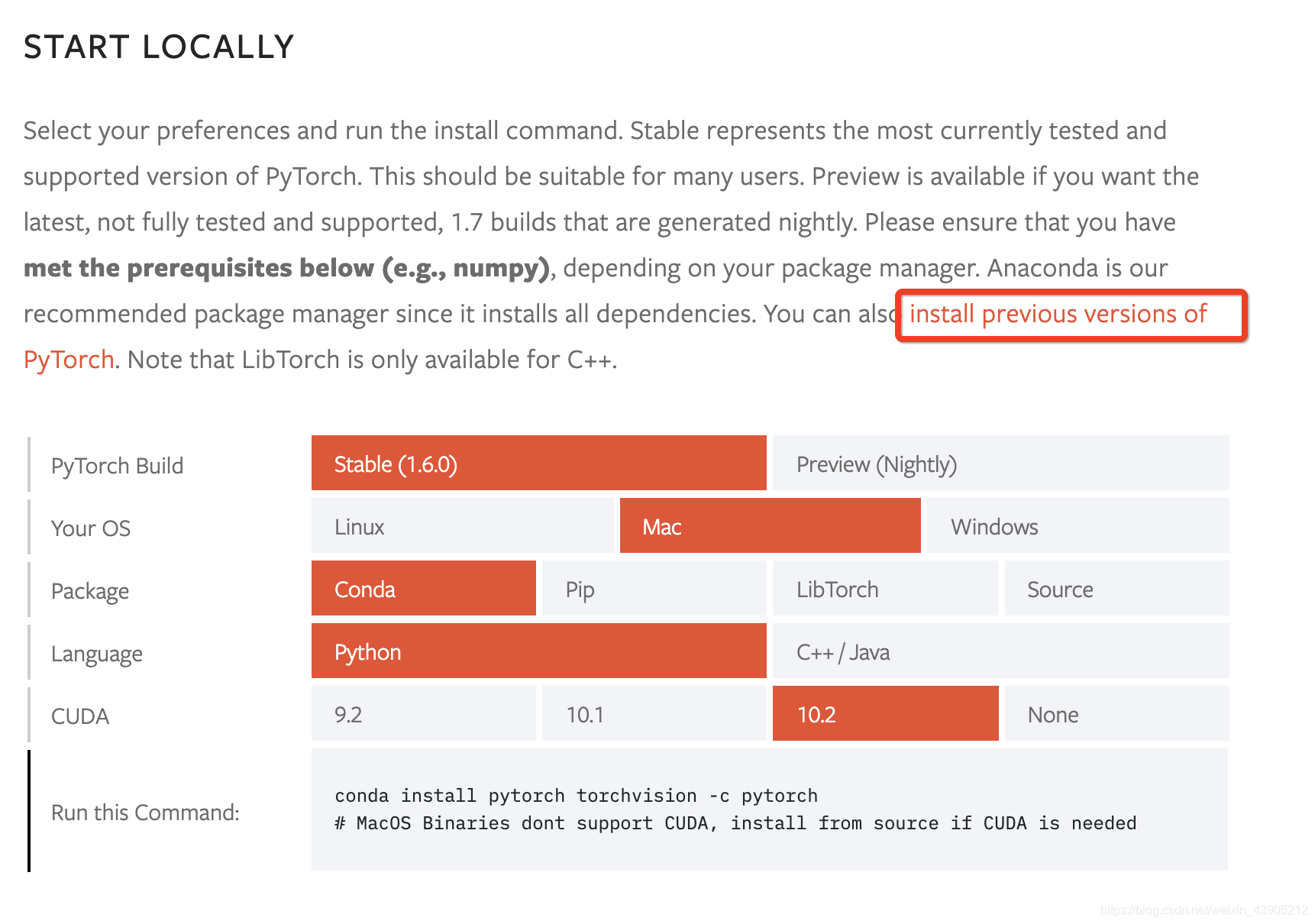
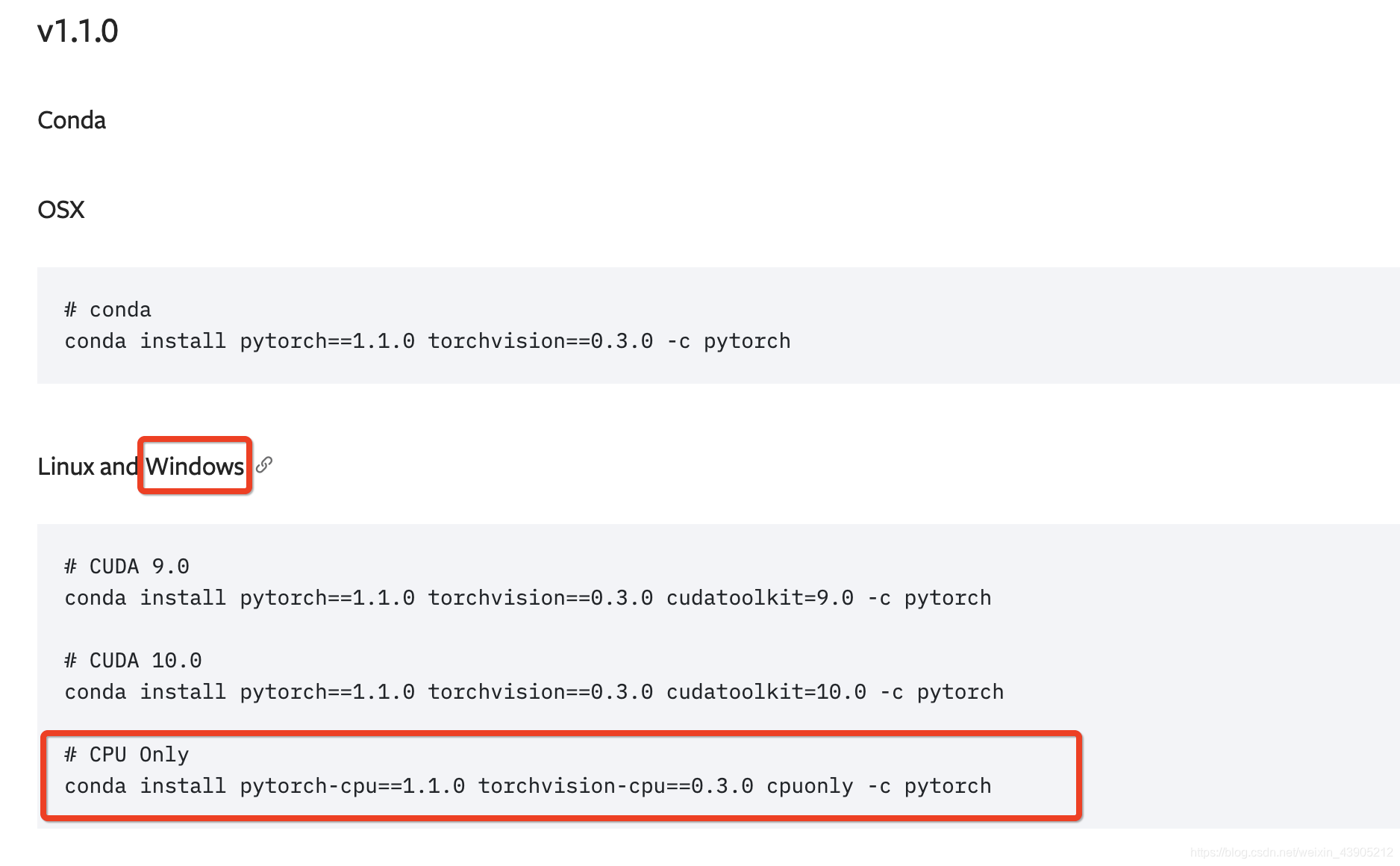
选择Windows->CPU only的命令行,复制下来,你可以直接在终端进入虚拟环境安装,也可以在后面打开VSCode,进项目再安装。(记得打开VPN哦,不然下载速度会很慢)
建立MMD项目
好的文件管理可以让你的电脑更加有序,不然项目一多就乱套了。(或者说我有整理洁癖也行哈哈哈哈)目录最好不要用中文,不然有些项目可能会出现乱七八糟的报错,还要改很长时间。打开一个盘建立一个pythonProjects文件夹,以后专门用来放python的项目,然后再创建一个MMD_test文件夹,用来放本次MMD项目的代码。
然后打开VSCode,可能会自动打开上次的项目,那么我们需要点击最上方“文件->新建窗口”,然后选择打开文件夹,选中之前创建的MMD_test。之后在最上方选择“终端->新终端”,在VSCode中打开一个终端,用conda activate 激活到目标虚拟环境中。
现在我们来粗略看一下MMD教程中的代码吧。
- 第一段代码
定义了两个函数,具体下面都有说明,看起来像是为之后的测试提供封装好的函数工具,那么我们就新建一个.py文件,把这段代码复制进去,命名为mmd_tool.py。
import torchdef guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):'''将源域数据和目标域数据转化为核矩阵,即上文中的KParams: source: 源域数据(n * len(x))target: 目标域数据(m * len(y))kernel_mul: kernel_num: 取不同高斯核的数量fix_sigma: 不同高斯核的sigma值Return:sum(kernel_val): 多个核矩阵之和'''n_samples = int(source.size()[0])+int(target.size()[0])# 求矩阵的行数,一般source和target的尺度是一样的,这样便于计算total = torch.cat([source, target], dim=0)#将source,target按列方向合并#将total复制(n+m)份total0 = total.unsqueeze(0).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))#将total的每一行都复制成(n+m)行,即每个数据都扩展成(n+m)份total1 = total.unsqueeze(1).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))#求任意两个数据之间的和,得到的矩阵中坐标(i,j)代表total中第i行数据和第j行数据之间的l2 distance(i==j时为0)L2_distance = ((total0-total1)**2).sum(2) #调整高斯核函数的sigma值if fix_sigma:bandwidth = fix_sigmaelse:bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)#以fix_sigma为中值,以kernel_mul为倍数取kernel_num个bandwidth值(比如fix_sigma为1时,得到[0.25,0.5,1,2,4]bandwidth /= kernel_mul ** (kernel_num // 2)bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]#高斯核函数的数学表达式kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for bandwidth_temp in bandwidth_list]#得到最终的核矩阵return sum(kernel_val)#/len(kernel_val)def mmd_rbf(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):'''计算源域数据和目标域数据的MMD距离Params: source: 源域数据(n * len(x))target: 目标域数据(m * len(y))kernel_mul: kernel_num: 取不同高斯核的数量fix_sigma: 不同高斯核的sigma值Return:loss: MMD loss'''batch_size = int(source.size()[0])#一般默认为源域和目标域的batchsize相同kernels = guassian_kernel(source, target,kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)#根据式(3)将核矩阵分成4部分XX = kernels[:batch_size, :batch_size]YY = kernels[batch_size:, batch_size:]XY = kernels[:batch_size, batch_size:]YX = kernels[batch_size:, :batch_size]loss = torch.mean(XX + YY - XY -YX)return loss#因为一般都是n==m,所以L矩阵一般不加入计算
- 第二段代码
用来生成后面测试用的两种不同分布下的数据,那我们就命名为data_generate.py。这里需要安装matplotlib库,直接pip install matplotlib就可以啦。
import random
import matplotlib
import matplotlib.pyplot as pltSAMPLE_SIZE = 500
buckets = 50#第一种分布:对数正态分布,得到一个中值为mu,标准差为sigma的正态分布。mu可以取任何值,sigma必须大于零。
plt.subplot(1,2,1)
plt.xlabel("random.lognormalvariate")
mu = -0.6
sigma = 0.15#将输出数据限制到0-1之间
res1 = [random.lognormvariate(mu, sigma) for _ in xrange(1, SAMPLE_SIZE)]
plt.hist(res1, buckets)#第二种分布:beta分布。参数的条件是alpha 和 beta 都要大于0, 返回值在0~1之间。
plt.subplot(1,2,2)
plt.xlabel("random.betavariate")
alpha = 1
beta = 10
res2 = [random.betavariate(alpha, beta) for _ in xrange(1, SAMPLE_SIZE)]
plt.hist(res2, buckets)plt.savefig('data.jpg)
plt.show()我们在终端输入python data_generate.py直接来运行一下,看看有没有什么问题。
报错啦,这里漏了一个 ’ 。

加上后保存再运行。(注意中英文输入法的切换哦!)又报错啦!

我们把报错信息NameError后面的内容复制到百度查一下(程序员的日常,现学现卖!)

哈哈哈是python版本的问题,从这就可以看出,原来的代码使用python2写的,但是我们装的是python3,不过没关系,python2到python3没有特别大的改动,做一些小修改就行啦。
再次运行结果图,而且它还在你的当前文件夹下保存了这个图片。
- 第三段代码
总共有两种情况,第一种情况是取不同分布数据,第二种情况,取相同分布数据,看MMD的效果。那我们把这两段代码合并以下,并修改之前的xrange错误。
from torch.autograd import Variable#参数值见上段代码
#分别从对数正态分布和beta分布取两组数据
diff_1 = []
for i in range(10):diff_1.append([random.lognormvariate(mu, sigma) for _ in range(1, SAMPLE_SIZE)])diff_2 = []
for i in range(10):diff_2.append([random.betavariate(alpha, beta) for _ in range(1, SAMPLE_SIZE)])X = torch.Tensor(diff_1)
Y = torch.Tensor(diff_2)
X,Y = Variable(X), Variable(Y)
print mmd_rbf(X,Y)#参数值见以上代码
#从对数正态分布取两组数据
same_1 = []
for i in range(10):same_1.append([random.lognormvariate(mu, sigma) for _ in range(1, SAMPLE_SIZE)])same_2 = []
for i in range(10):same_2.append([random.lognormvariate(mu, sigma) for _ in range(1, SAMPLE_SIZE)])X = torch.Tensor(same_1)
Y = torch.Tensor(same_2)
X,Y = Variable(X), Variable(Y)
print mmd_rbf(X,Y)
运行一下吧:

报错啦,这个问题也是python2到python3版本变换的一个经典问题,python3中的print需要加括号。
print(mmd_rbf(X,Y))
我们还注意到这里用了mmd_rbf函数,但是我们把这个函数定义在了mmd_tool.py文件里面,所以运行mmd_test.py文件时,文件应该不知道这个函数的意义,那怎么解决呢?我们直接在顶部加一个声明,类似于import包一样:
from mmd_test import * # 这里的*代表导入mmd_test里面所有定义的函数,你也可也指定单独的函数导入
你也可以直接把这两个文件合并起来,就用一个文件,虽然这样很方便,但是如果项目很大的话我们还是需要把不同作用的代码分开,方便管理,养成良好的编程习惯。
之后我们再次运行。

又报错啦,SAMPLE_SIZE没有定义!!是因为我们生成数据的代码在data_generate.py文件里,还包括mu、sigma等等变量,这个问题是不是和上面的问题一样,那我们可以import来解决!(import就完事了)
from data_generate import *
然后我们再运行试试!

结果出来了!恭喜你哈哈哈,接下来就可以仔细看一看这个代码是如何运行的,原理是什么啦。
注意测试代码里面有这些代码:
from torch.autograd import Variable
...
X,Y = Variable(X), Variable(Y)
...
这里的Variable其实是pytorch很早以前版本的一个类,在所有张量定义使用的时候都要加一下,但是现在为了简洁已经删除了,只不过有些时候不会报错。为了更规范我们还是把包含Variable的代码都修改一下。
最后再补充一个关于if name == ‘main’: 的小知识点。
这篇关于最大均值差异(Maximum Mean Discrepancy, MMD)复现教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









