本文主要是介绍[论文解析] MagicFusion:Boosting Text-to-Image Generation Performance by Fusing Diffusion Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文链接:
https://arxiv.org/abs/2303.13126
项目主页:
https://magicfusion.github.io/
源码链接:
https://github.com/MagicFusion/MagicFusion.github.io
文章目录
- Overview
- What problem is addressed in the paper?
- Is it a new problem? If so, why does it matter? If not, why does it still matter?
- What is the key to the solution?
- What is the main contribution?
- What can we learn from ablation studies?
- Method
- 计算显著性映射
- 显著性融合
- 显著性感知 Mask
- 算法
- 技术创新说明
- Experiments
- 应用
- Application1 :细粒度融合
- Application2:重新语境化(Recontextualization)
- Application 3: 跨域融合
- 比较和消融
- 和仅使用通用模型相比
- 和dreambooth相比
- 和额外给定mask相比
- 和加权求和相比
- Conclusion
Overview
What problem is addressed in the paper?
we propose a simple yet effective method called Saliency-aware Noise Blending (SNB) that can empower the fused text-guided diffusion models to achieve more controllable generation.
(通过对两个预训练模型进行融合,实现更可控的text-to-image生成)
Is it a new problem? If so, why does it matter? If not, why does it still matter?
Yes,first propose to fuse two well-trained diffusion models to achieve more powerful image generation, which is a novel and valuable topic.
SNB is training-free and can be completed within a DDIM sampling process. Additionally, it can automatically align the semantics of two noise spaces without requiring additional annotations such as masks.
(提出的方法可以在任意DDIM采样过程中使用,并且不需要附加的mask就可以实现两个模型自动的语义对齐,从而实现良好的生成效果。)
What is the key to the solution?
Specifically, we experimentally find that the responses of classifier-free guidance are highly related to the saliency of generated images. Thus we propose to trust different models in their areas of expertise by blending the predicted noises of two diffusion models in a saliencyaware manner.
(通过实验发现了classifier-free guidance 和生成图像的显著性密切相关,提出通过以显著性感知的方式混合两个扩散模型的预测噪声,建议信任不同的模型在其专业领域。)
What is the main contribution?
- We propose to fuse two well-trained diffusion models to achieve more powerful image generation, which is a novel and valuable topic.
- We propose a simple yet effective Saliency-aware Noise Blending method for text-guided diffusion models fusion, which can preserve the strengths of each individual model.
- We conduct extensive experiments on three challenging applications (i.e., a general model + a cartoon model, a fine-grained car model, and a DreamBooth [28] model), and prove that SNB can significantly empower pre-trained diffusion models.
(1. 提出要融合两个已经训练好的模型来实现更好的图像生成,2. 提出了简单有效的显著性感知噪声融合方法来做 文本引导的扩散模型融合,可以保留每个模型各自的优势。)
What can we learn from ablation studies?
- 可以解决通用模型在prompt 中包含多个主体的时候,出现的部分主体丢失的问题
- 相比于Dreambooth,能更准确捕捉主体的更精细的细节,生成符合prompt的场景
- 在编辑或替换场景内容时,SNB产生了更自然和真实的结果,特别是在物体和场景混合的场景中。
- 优于直接平均方法,实现了精确的语义对齐,产生了更准确和真实的图像内容。
Method
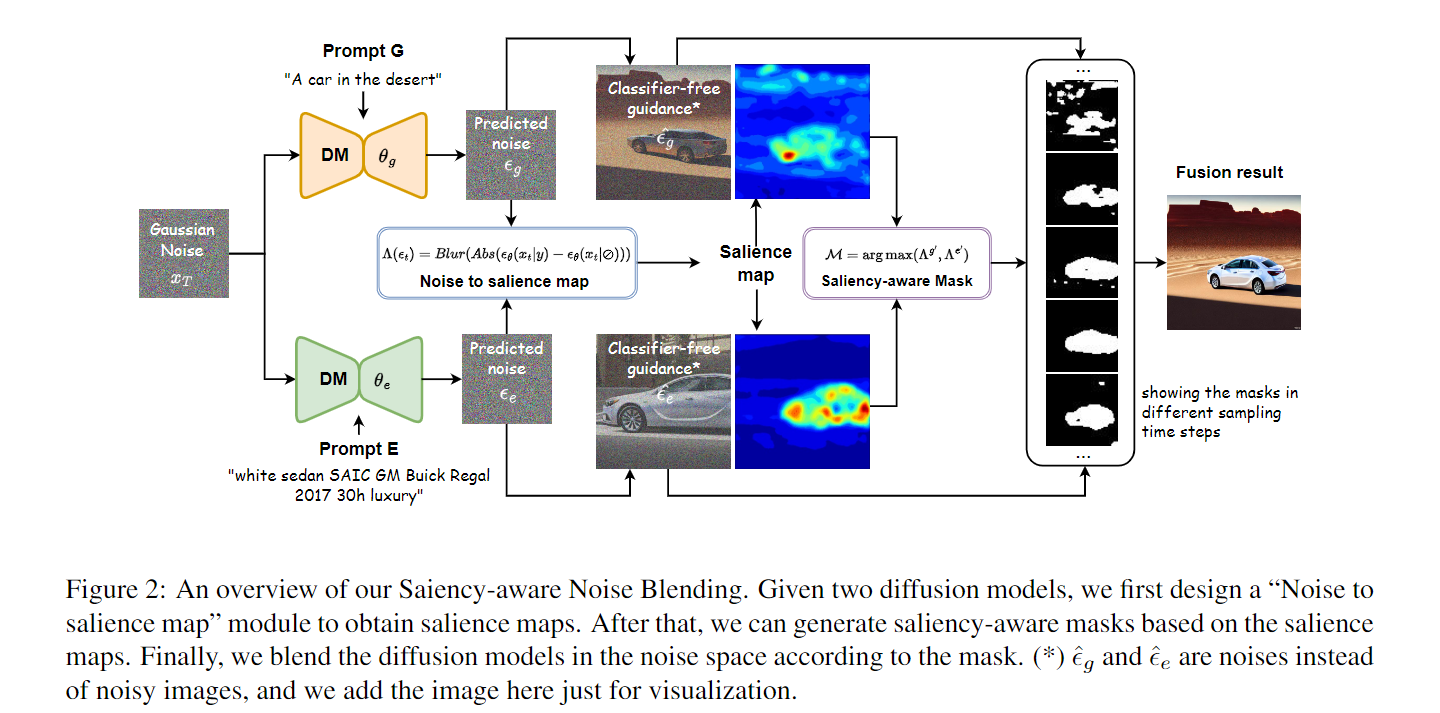
计算显著性映射

ϵ θ \epsilon_\theta ϵθ表示diffusion model预测出的噪音, a b s ( ) abs() abs()是取绝对值操作, b l u r ( ) blur() blur()是平滑操作
显著性融合

对任意的两个模型,一个称为通用模型,一个称为专家模型,对他们执行上面的操作。
其中 k g k^g kg和 k e k^e ke是超参数
s o f t m a x ( ) softmax() softmax()在这里确保每个显著图的和是一个常数(即1),这意味着每个模型必须专注于某些区域,而不是对所有地方都有高响应。
显著性感知 Mask

显著性感知mask是执行噪声混合的有效指导,它由0和1的二进制值组成,分别对应通用模型和专家模型的噪音。
最后融合后的噪声计算如下:

算法
整个显著性感知噪声融合方法归纳在算法1中。

技术创新说明
方法虽然简单,但是从它解决了两大挑战来讲是不简单的。
- 我们利用无分类器的指导来自动识别每个模型的专业领域。超参数k的引入为混合两种图像来源提供了更好的可控性,从而使基于SNB的图像生成具有更大的创造力和灵活性。
- 获取与提示内容密切相关的显著性响应值是一项非常重要的任务。在每个采样步骤中,两个模型将混合后的xt作为输入,以实现两个模型噪声空间的自动语义对齐。
相信我们的探索将为社区做出贡献,并有利于预训练扩散模型的利用。
Experiments
应用
为了评估所提方法的有效性,在三个具有挑战性的应用上进行了实验。
- 1)细粒度融合,即融合通用模型和细粒度模型,以实现复杂场景的细粒度生成。
- 2)重新语境化,即融合通用模型和DreamBooth[28]模型,可以在保留良好细节的情况下对特定物体进行重新语境化。
- 3)跨域融合,即融合通用模型和卡通模型,结合卡通模型生成复杂场景的创意优势和通用模型的真实感。
Application1 :细粒度融合
model1:能够生成广泛场景的通用模型,比如stable diffusion
model2:细粒度的汽车模型(可以明确的指定汽车的颜色、视角、类型、品牌、型号)
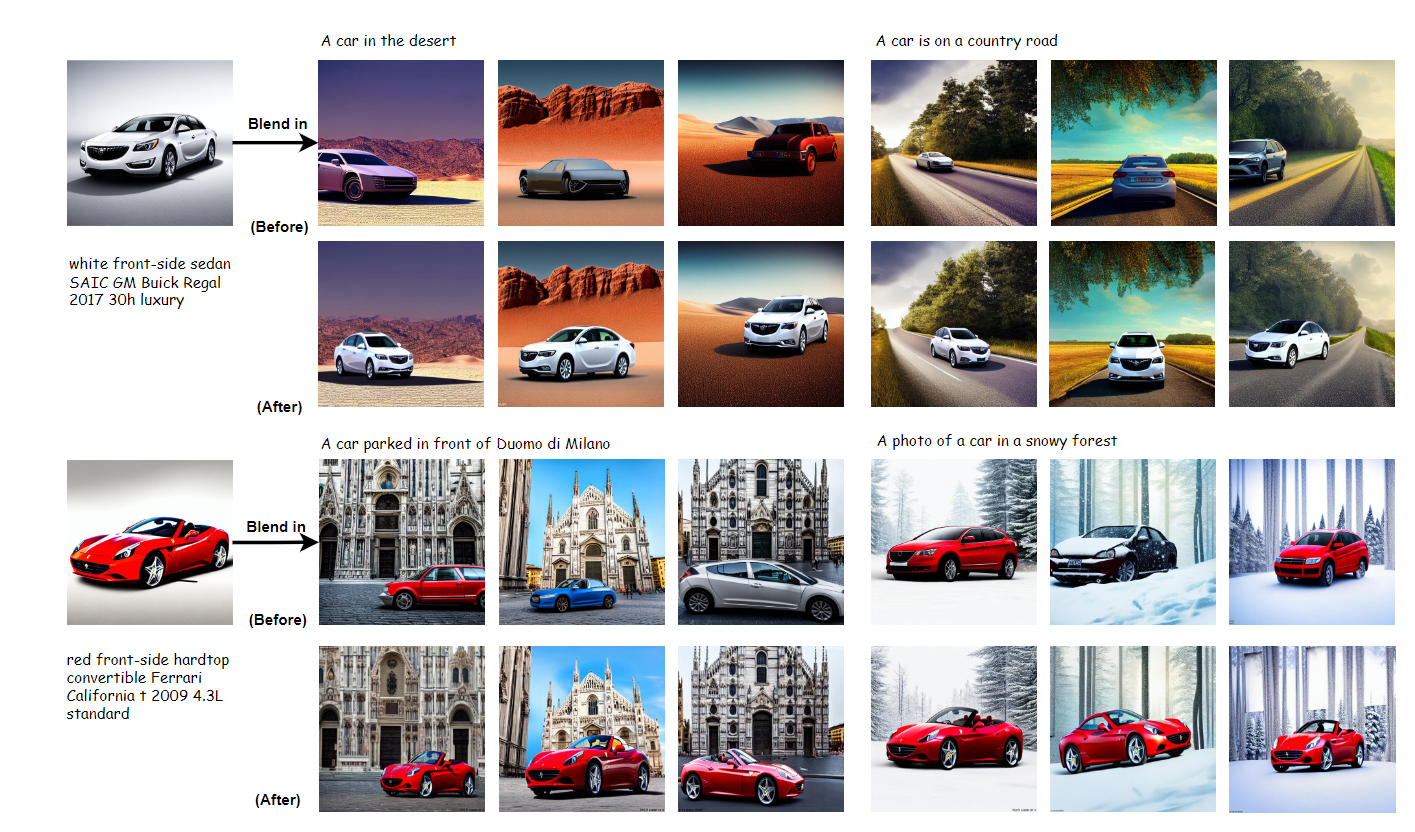
通用模型可以生成了任意车辆在场景中的图片(每组case的第一行)
汽车模型可以生成细粒度的车辆 (最左侧)
融合之后,可以看到细粒度的车辆替换掉了原来场景中汽车。 值得注意的是,在融合的过程中,并没有额外标注出原始场景中汽车的位置,融合后的效果也没有硬性拼接背景和主体的情况,而是非常自然连贯。
Application2:重新语境化(Recontextualization)
model1:通用模型
model2: 用输入图片fine-tune后的模型。
用通用模型生成输入图片类型所在的一个场景,例如,a photo of a bag on the pool table
用fine-tune后的模型生成“a photo of a [] bag” .
融合的结果就是,输入图片对应的包在这个场景中。
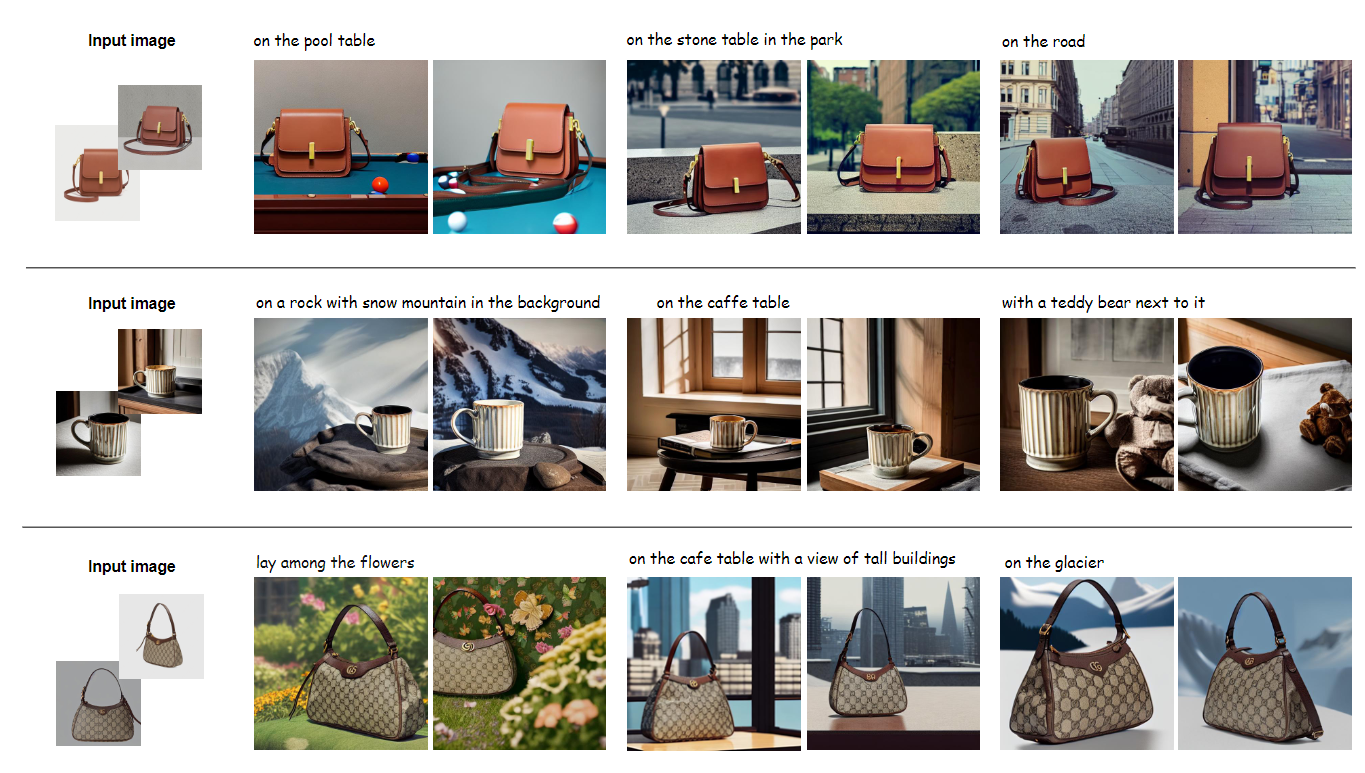
最左侧是输入图片,后面对应在三个不同场景中的融合效果展示。
Application 3: 跨域融合
model1:通用模型
model2:卡通模型
给两个模型,相同的prompt,例如“a cat is wearing sunglasses”
通过融合两组噪声,SNB生成的图像表现出创造性的组成和现实的内容。

我们提出的SNB为实现创意和现实的平衡提供了一个强大的工具,我们相信这样的工具有潜力使各种领域的广泛应用受益,如艺术和ai辅助设计。
比较和消融
和仅使用通用模型相比
通用模型在prompt 中包含多个主体的时候,可能会出现部分主体丢失的情况,尤其是在描述的场景在现实中不常见的情况。
例如:
App1中,“a car is driving on a winding mountain rood”车俩丢失,或者"A car on the road by thesea, seagulls all over the sky" 海鸥丢失。
App3中,“A lion with a crown on his head” 王冠丢失。

所提出的SNB可以解决这些限制,它集成了一个专门的模型,如应用1中的汽车模型,或应用3中的卡通模型,以提高图像生成的准确性和真实感。通过利用通用模型和专门模型的优势,所提出方法可以生成视觉上吸引人且语义丰富的图像。这种方法有可能通过实现更复杂和更真实的图像生成来推进计算机视觉领域。
和dreambooth相比
在场景描述复杂的情况下,Dreambooth可能会丢失主体(左第一行),并且在处理创造性场景构图(如“月球上的背包”)时面临困难(左第二行)。此外,Dreambooth在保留给定对象的细节上也不如SNB,特别是复杂和冗长的提示。(右)

相比之下,所提出方法擅长将特定主题整合到场景中,同时保持对提示的保真度。尽管Dreambooth可以为“花园长凳上的一个包”之类的简短提示生成上下文相关的图像,但它可能无法准确捕捉主题的更精细的细节,例如包的图形纹理。相比之下,所提出方法不仅生成了符合提示的图像,还以更高的准确性再现了主题细节。
和额外给定mask相比
这种方法既不能处理跨域融合等应用,也不能很好地处理物体和场景混合的情况,如“a car in a snowy forest”。
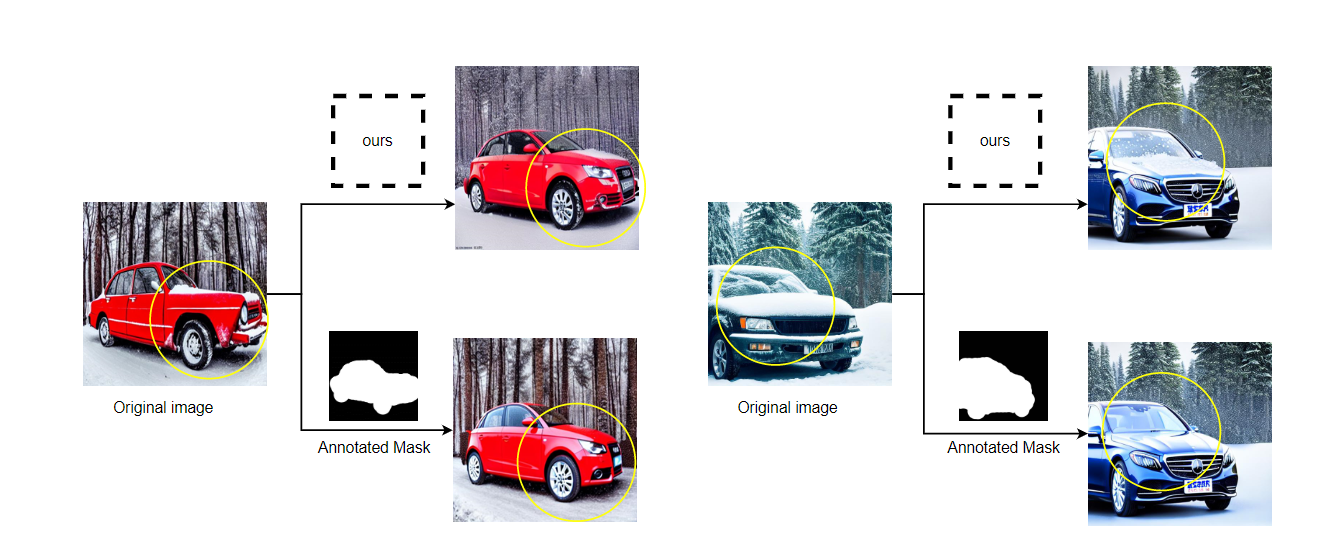 文章的方法和给定mask的方法之间的比较表明,我们的SNB方法准确地保留了受场景影响的详细主体特征,如汽车引擎盖和车轮上的雪。相比之下,给定mask的方法替换了整个汽车区域,导致场景内的主体细节丢失。总的来说,在编辑或替换场景内容时,SNB产生了更自然和真实的结果,特别是在物体和场景混合的场景中。
文章的方法和给定mask的方法之间的比较表明,我们的SNB方法准确地保留了受场景影响的详细主体特征,如汽车引擎盖和车轮上的雪。相比之下,给定mask的方法替换了整个汽车区域,导致场景内的主体细节丢失。总的来说,在编辑或替换场景内容时,SNB产生了更自然和真实的结果,特别是在物体和场景混合的场景中。
和加权求和相比
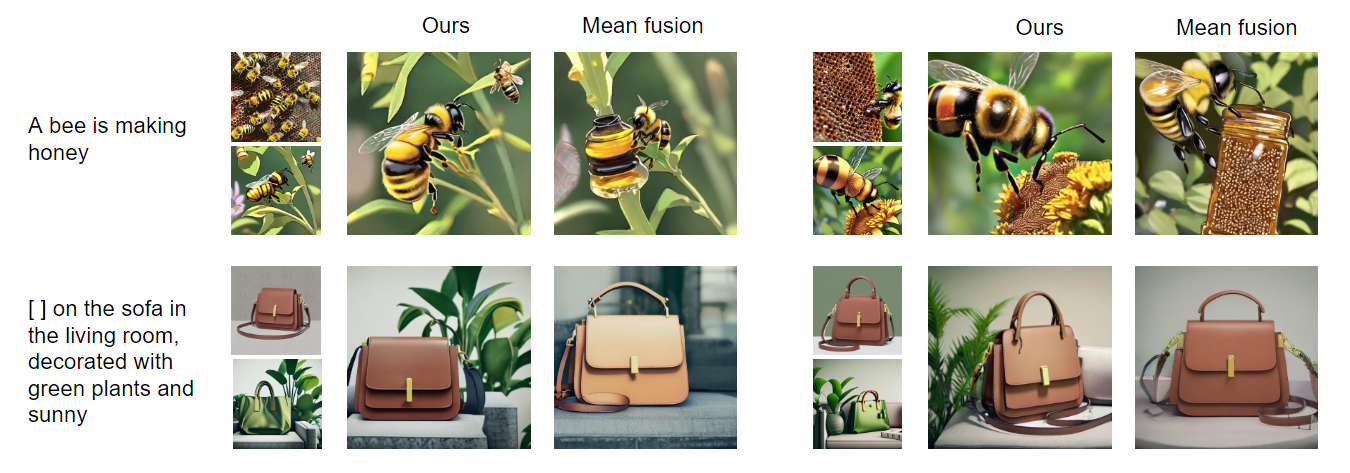
SNB和直接对两种噪声取平均值的融合方法的实验结果有显著差异。当使用两种噪声的加权和时,得到的图像内容显得杂乱,缺乏所需的语义对齐(第一行)。在重新语境化任务中,存在着由于不准确的掩蔽而丢失重要场景内容的风险(第二行)。相比之下,SNB方法优于直接平均方法,实现了精确的语义对齐,产生了更准确和真实的图像内容。
Conclusion
本文研究了整合预训练文本引导扩散模型的问题,以实现更可控的生成。本文提出一种简单有效的显著性感知噪声混合(SNB),以保留每个单独模型的优势。在三个具有挑战性的应用(即通用模型+卡通模型、细粒度汽车模型和Dream- Booth模型)上的广泛实验表明,SNB可以显著增强预训练扩散模型。随着预训练大型生成模型的快速发展,本文工作具有重大价值。未来,我们将继续研究不同大型生成模型的集成,并将我们的方法扩展到更一般的环境。
这篇关于[论文解析] MagicFusion:Boosting Text-to-Image Generation Performance by Fusing Diffusion Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




