本文主要是介绍linux内核 路由fib表之数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
要想看懂路由,最好先能理清各个结构体之间的关联,这样才能有一个整体的印象。
1 内核fib路由表
1.1 基本结构
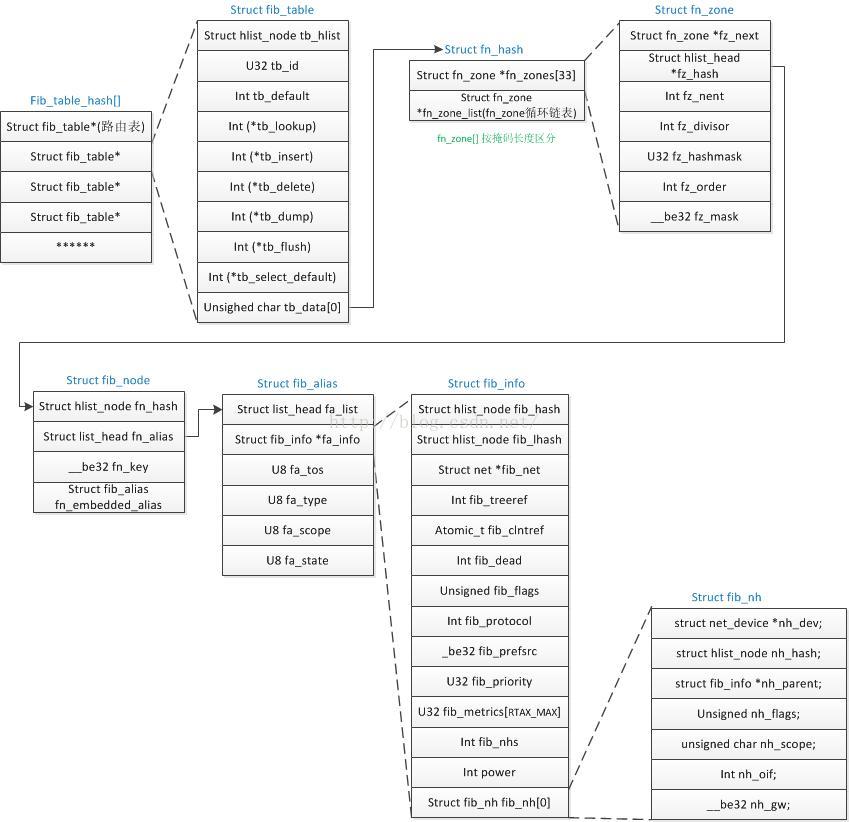
1.1.1 fib_table_hash结构图
1.1.2 举例说明fn_zone结构体的关系
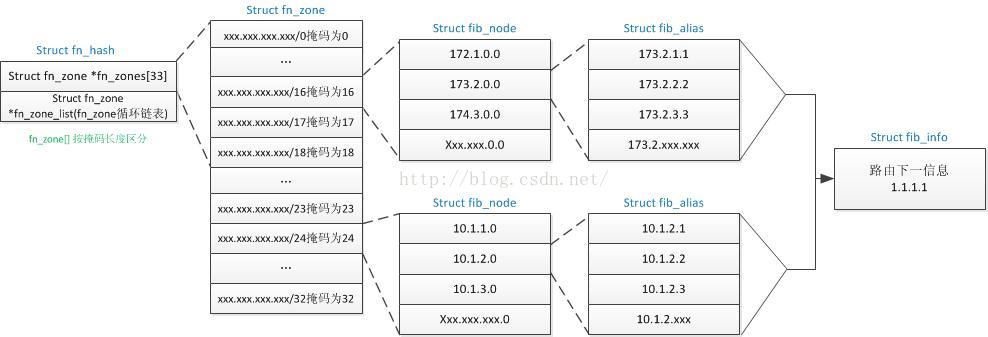
说明:
结构体Fn_zone[33]中存放同一掩码长度表项的集合;
结构体fib_node存放同一网段的路由表项集合;
结构体fib_alias存放具体的一条路由表项;
结构体fib_info存放下一跳网关等信息。
1.1.3 结构体描述
相关数据结构:fib_table、fn_hash、fn_zone、fib_node、fib_alias、fib_info、fib_nh
全局散列表net->ipv4.fib_table_hash中,存放所有的路由表fib_node;
全局散列表fib_info_hash,存放所有的fib_info实例;
全局散列表fib_info_laddrhash,当路由表项有源地址时,才存放该fib_info
(1)路由表fib_table结构
路由表是由fib_table结构来描述的,该结构是通过函数fib_hash_table()来赋值的,fib_table结构中的tb_data,是一个零长数组,该地址指向fn_hash结构体;
struct fib_table
| struct hlist_node tb_hlist; | //用来将各个路由表连接成一个双向链表 |
| u32 tb_id; | /路由标识,最多可以有256个路由表(静态路由、策略路由等等表项) |
| int tb_default; |
|
| int (*tb_lookup)(struct fib_table*tb,conststruct flowi*flp,struct fib_result*res); | //搜索路由表项 |
| int (*tb_insert)(struct fib_table*,struct fib_config*); | //插入给定的路由表项 |
| int (*tb_delete)(struct fib_table*,struct fib_config*); | //删除给定的路由表项 |
| int (*tb_dump)(struct fib_table*table,struct sk_buff *skb,struct netlink_callback*cb); | //dump出路由表的内容 ??不懂什么意思 |
| int (*tb_flush)(struct fib_table*table); | //刷新路由表项,并删除带有RTNH_F_DEAD标志的fib_node |
| void (*tb_select_default)(struct fib_table*table,conststruct flowi*flp,struct fib_result*res); | //选择一条默认的路由 |
| unsigned char tb_data[0]; | //路由表项的散列表的起始地址,指向fn_hash |
(2)结构体fn_hash
结构体fn_hash包含fn_zone[33]和fn_zone_list,其中fn_zone[33]是由33个fn_zone结构指针构成的向量,与fn_zone_list构成了循环单链表;
Struct fn_hash
| struct fn_zone *fn_zones[33]; |
|
| struct fn_zone *fn_zone_list; | //fn_zone链表 |
(3)结构体fn_zone
结构体fn_zone代表同一掩码长度表项的集合,fz_hash是长度为fz_divisor的HASH表,HASH表中存放的是不同子网的fib_node节点。
Struct fn_zone
| struct fn_zone *fz_next; | //将不为空的路由表项fn_zone链接在一起,该链表头存储在fn_hash的fn_zone_list中。 |
| struct hlist_head *fz_hash; | //指向存储路由表项fib_node的散列表 |
| Int fz_nent; | /在zone的散列表中的fib_node的数目,用于判断是否需要改变散列表的容量 |
| Int fz_divisor; | //散列表fz_hash的容量,及散列表桶的数目每次扩大2倍,最大1024 |
| u32 fz_hashmask; | //值为fz_divisor-1,用来计算散列表的关键值 |
| Int fz_order; | /掩码fz_mask的长度 |
| __be32 fz_mask; | //利用fz_order构造得到的网络掩码 |
(4)结构体fib_node
结构体fib_node根据键值fn_key的不同,HASH到fn_hash结构的hash表中;每个网段对应一个fib_node,网段用fn_key来表示,有相同网段的路由表项共享一个路由表项,即公共部分。
具体的路由表项由fib_alias和fib_info这两个结构体构成。
struct fib_node
| struct hlist_node fn_hash; | //用于散列表中同一桶内的所有fib_node链接成一个双向链表 |
| struct list_head fn_alias; | //指向多个fib_alias结构组成的链表 |
| __be32 fn_key; | //由IP和路由项的netmask与操作后得到,被用作查找路由表的搜索条件 |
| struct fib_alias fn_embedded_alias; | //内嵌的fib_alias结构,一般指向最后一个fib_alias |
(5)结构体fib_alias
相同网段的每一条路由表项有各自的fib_alias结构;多个fib_alias可以共享一个fib_info结构;
struct fib_alias
| struct list_head fa_list; | //将所有fib_alias组成的链表 |
| struct fib_info *fa_info; | //指向fib_info,储存如何处理路由信息 |
| u8 fa_tos; | //路由的服务类型比特位字段 |
| u8 fa_type; | //路由表项的类型,间接定义了当路由查找匹配时,应采取的动作 |
| u8 fa_scope; | //路由表项的作用范围 |
| u8 fa_state; | //一些标志位,目前只有FA_S_ACCESSED。表示该表项已经被访问过。 |
(6)结构体fib_info
结构体Fib_info存储真正重要路由信息,即如何到达目的地。
struct fib_info
| struct hlist_node fib_hash; | //所有fib_info组成的散列表,该表为全局散列表fib_info_hash |
| struct hlist_node fib_lhash; | //当存在首源地址时,才会将fib_info插入该散列表,该表为全局散列表fib_info_laddrhash |
| struct net *fib_net; |
|
| Int fib_treeref; | //使用该fib_info结构的fib_node的数目 |
| atomic_t fib_clntref; | //引用计数。路由查找成功而被持有的引用计数 |
| Int fib_dead; | //标记路由表项正在被删除的标志,当该标志被设置为1时,警告该数据结构将被删除而不能再使用 |
| Unsigned fib_flags; | //当前使用的唯一标志是RTNH_F_DEAD,表示下一跳已无效 |
| Int fib_protocol; | //设置路由的协议 |
| __be32 fib_prefsrc; | //首选源IP地址 |
| u32 fib_priority; | //路由优先级,默认为0,值越小优先级越高 |
| u32 fib_metrics[RTAX_MAX]; | //与路由相关的度量值 |
| Int fib_nhs; | //可用的下一跳数量,通常为1.只有支持多路径路由时,才大于1 |
| struct fib_nh fib_nh[0]; | //表示路由的下一跳 |
(7)结构体fib_nh
该结构体中存放着下一跳路由的地址nh_gw。
struct fib_nh
| struct net_device *nh_dev; | //该路由表项输出网络设备 |
| struct hlist_node nh_hash; | //fib_nh组成的散列表 |
| struct fib_info *nh_parent; | //指向所属fib_info结构体 |
| struct fib_info *nh_parent; |
|
| Unsigned nh_flags; |
|
| unsigned char nh_scope; |
|
| Int nh_oif; | //输出网络设备索引 |
| __be32 nh_gw; | //网关地址 |
后面我们分析路由表的操作:初始化、创建、查找、删除。
这篇关于linux内核 路由fib表之数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




