本文主要是介绍解决pymysql.err.DataError (1406, “Data too long for column ‘remark‘ at row 1419“),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 问题背景
在向数据库导入大批量数据的时候报错:
DataError: (pymysql.err.DataError) (1406, "Data too long for column 'remark' at row 1419")
相关代码:
import pandas as pd
from sqlalchemy import create_engine
from urllib.parse import quote_plus as urlquote
import pymysqluserName = "xxxx"
password = "xxxxx"
dbHost = "your ip xxx.xxx.xxx.xxx"
dbName = "your dbname"
dbPort = 3306# charset=utf8mb4为utf8的超集,兼容utf8,可存储emoji表情等非常规数据
conn = f'mysql+pymysql://{userName}:{urlquote(password)}@{dbHost}:{dbPort}/{dbName}?charset=utf8mb4'
engine = create_engine(conn,max_overflow=50, # 超过连接池大小外最多创建的连接pool_size=50, # 连接池大小pool_timeout=5, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置)encoding='utf-8',echo=False
)pd.io.sql.to_sql(data_df, name="db_table1", con=engine, if_exists="append", index=False)
engine.dispose()2. 分析
百度上有很多解决办法,但是都不适合自己的问题情况。
- 有的办法是让修改MySQL数据库的严格模式,就是修改sql_mode参数 STRICT_TRANS_TABLES,但我认为不合适,尤其是在线上生产数据库,严格模式可以确保数据的基本规范性,把严格模式去掉后的数据库不就是垃圾场了么,什么数据都能往里面塞;如果是数据库是自己测试的,那就无所谓了。
- 还有的办法是让修改字符集,但巧了,我的数据库字符集是这样的,没得改。
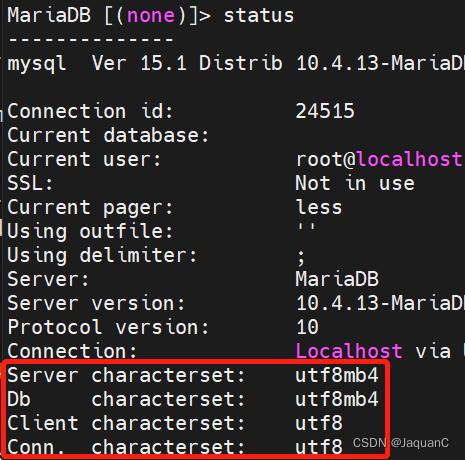
所以,还得自己来。
2.1 看数据
看报错,第1419行数据的 ‘remark’ 字段太长,先看看数据是什么样子吧。
data_df['remark'][1410:1420]

搞笑,报错明显跟实际数据不一致。莫名其妙。
会不会和写入时候的数据量有关系,这次写入的数据有41298条。

会不会是单次写入的数据量超过 sqlalchemy 的限制,只是猜想,也没功夫去细究sqlalchemy的源码了,先把数据拆分再写入试试。
2.2 数据拆分写入
部分代码:

结果还是报错了,现象和上次一样。明明报错行的字段数据为空,实在不行还有最后一招:我知道数据本来的样子,既然数据没错,那我就把报错那行的字段值截了。
ddd = data.get("remark", "---")
itm["remark"] = ddd[:255] if len(ddd) > 255 else ddd
好了,搞定收工!
2.3 写在最后
我的解决方法只是提供个参考,看到这篇博客的朋友如果有新的发现可以留言,不要照搬我的思路哦,毕竟我是在知道真实数据的情况下做出的操作。
这篇关于解决pymysql.err.DataError (1406, “Data too long for column ‘remark‘ at row 1419“)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







