本文主要是介绍略解深度学习优化策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、基本概念
二、梯度下降
三、牛顿法
四、随机梯度下降(SGD)
五、动量法
一、基本概念
常见的优化算法:SGD和Adam
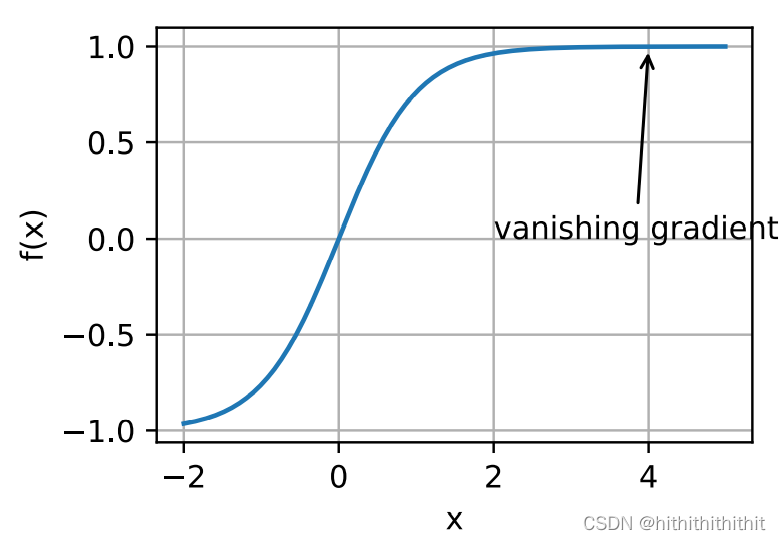
梯度的简单解释:梯度可以理解为函数的导数,也可理解为函数的倾斜程度。函数图像水平时,函数的梯度消失。
凸函数:深度学习中出现的几乎所有优化问题都是非凸的。下面是对凸(convex)和非凸的一个介绍。
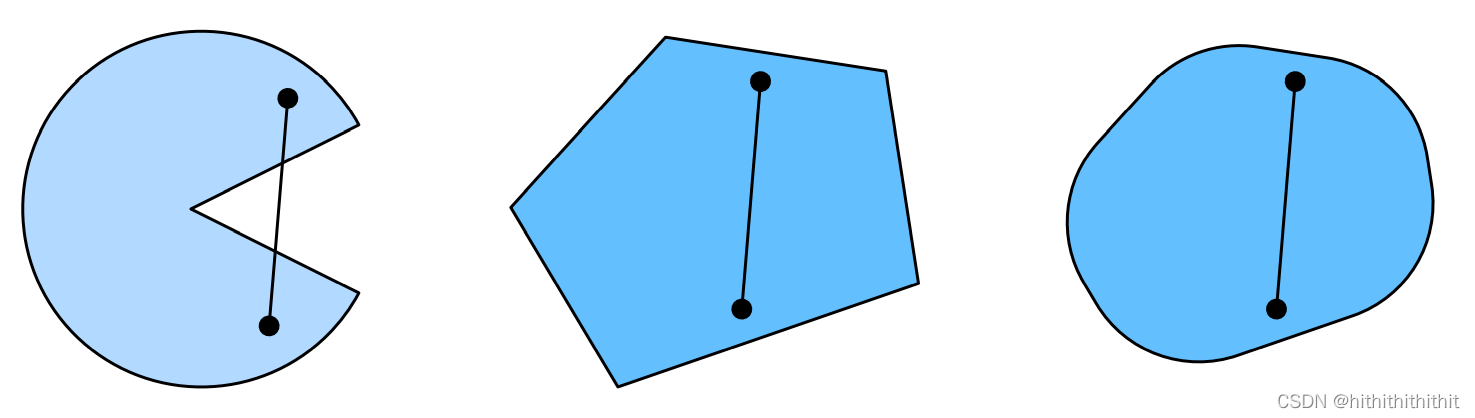
由上图可以找到明显的规律是,第一个图形和后两个图形的明显区别,第一张图中的点线段部分出现在了图形外,而后两张线段都被包含在了图形内部。前者是非凸,后者是凸。继续看下面的图形。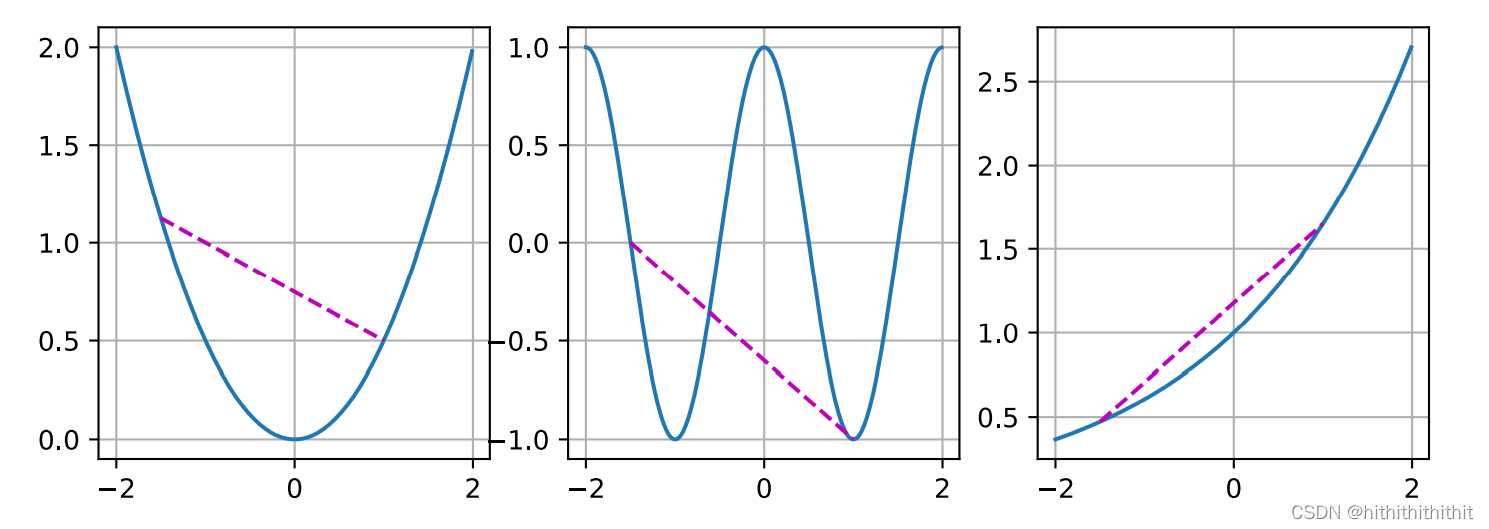
上面三张图形,中间的是非凸函数,两边的是凸函数,具体来说就是函数上的任意两点连线的线段中间的点的纵坐标大于或者小于函数上中间点的纵坐标,这类函数就叫做凸函数。
凸函数的性质:凸函数的局部最小值也是全局最小值。
优化函数:用于来对损失函数进行最小化优化,就是采取一种怎么样的策略使损失函数接近于最小值。优化函数的目标是为了最小化目标函数,深度学习的目标则是为了寻找合适的模型去解决一个指定的问题。对于训练和推理来说,优化主要是在训练阶段发挥作用,而深度学习的目标则是为了在推理阶段发挥作用,优化是为了较小训练误差,深度学习则是为了减小泛化误差。
经验风险:经验风险是训练数据集的平均损失。
风险:是整个数据群的预期损失。
深度学习的优化挑战:
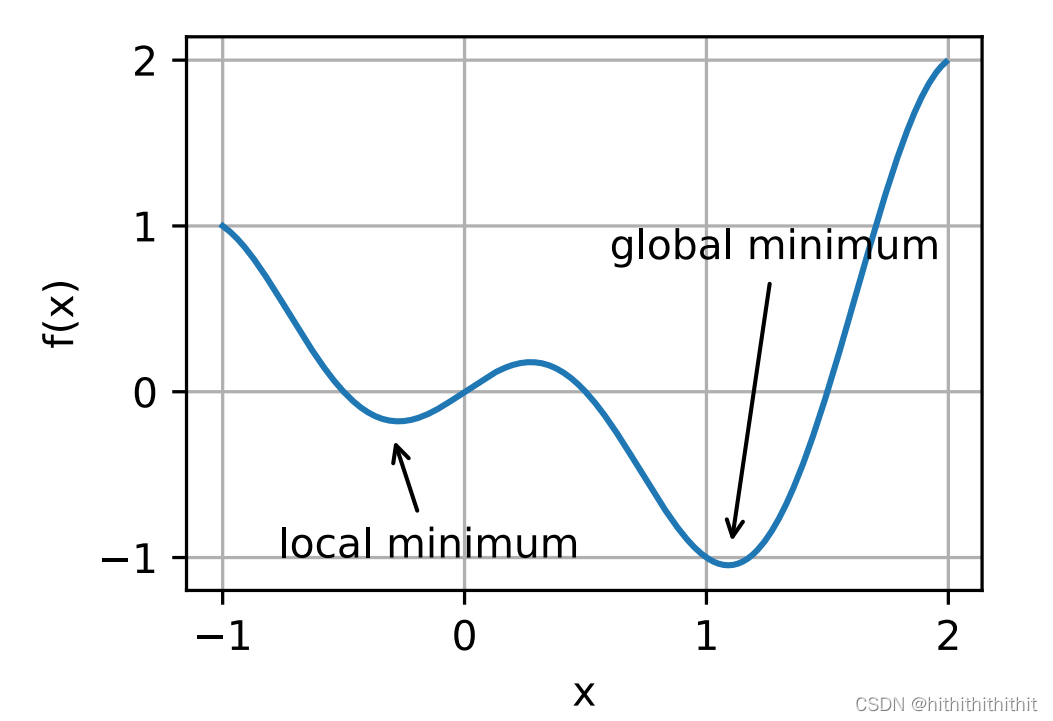
1、局部最小值:对于非凸函数,则存在多个极值点,此时局部最小值和全局最小值是不一样的。
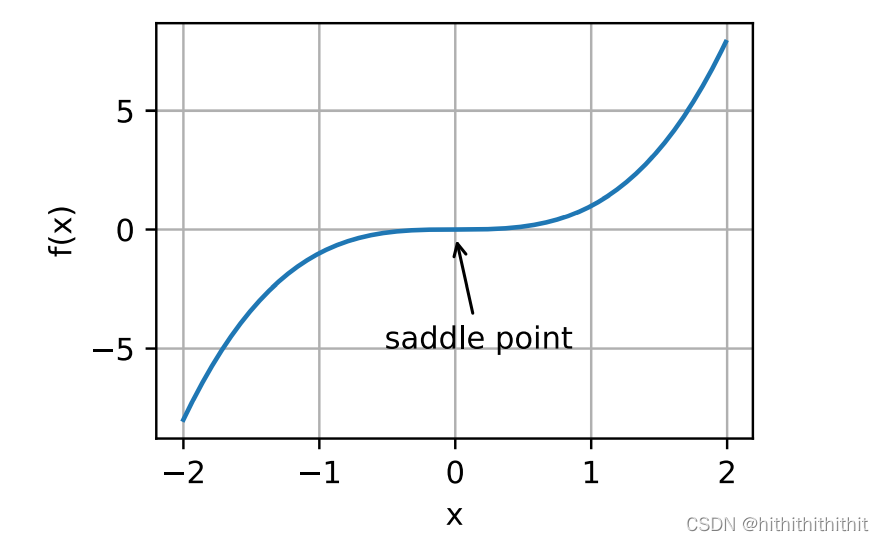
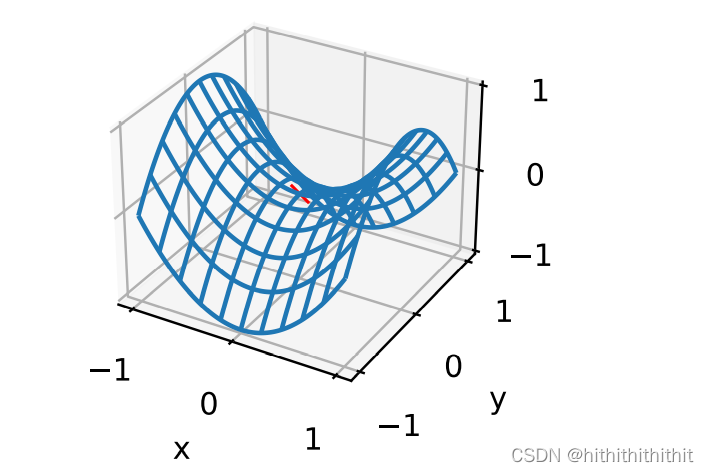
2、鞍点:鞍点指的是函数一阶导和二阶导均为0的点,此时虽然函数梯度消失,但既不是全局最小值也不是局部最小值。而到了这里优化可能会停止,这将导致优化过程失败。为了更加明白鞍点这个概念的由来,下面右图给出了一个三维空间的函数图像,其中红色的点就是鞍点,整个图像像极了马鞍。
3、梯度消失:梯度消失是最常遇见的问题,如果函数遭遇了梯度消失问题,那么函数的优化可能会趋于停滞。
二、梯度下降
梯度下降就是函数沿着趋向于梯度消失的方向进行优化,我们可以通过设置学习率来调整梯度下降的变化率。主要思想就是通过搜索方向(梯度消失的方向)和步长(学习率的大小)来对参数进行更新。
梯度下降的具体演示如下图所示。
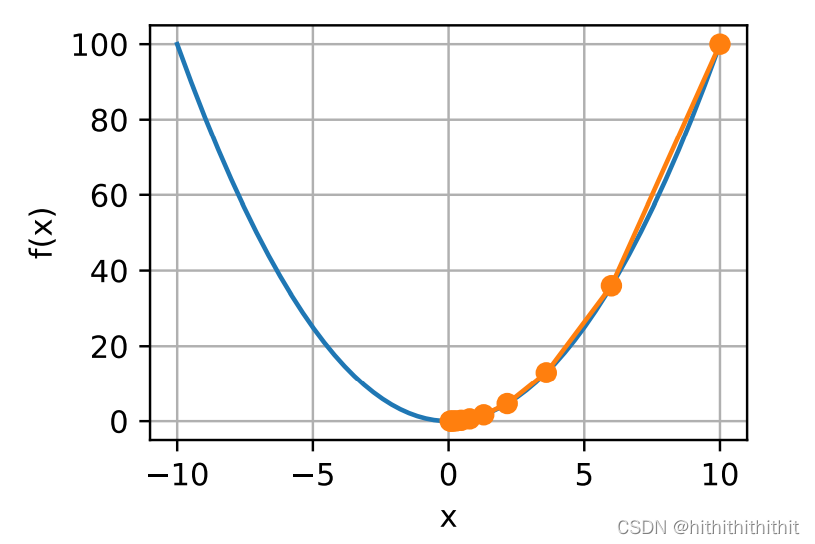
由上图可知,起始点在右上角的那个点,沿着梯度下降的方向进行着优化,最终达到了函数的极小值点,在凸函数中,同样这也是函数的最小值点,也就是一个最优解。下面是两个不同学习率的优化解。
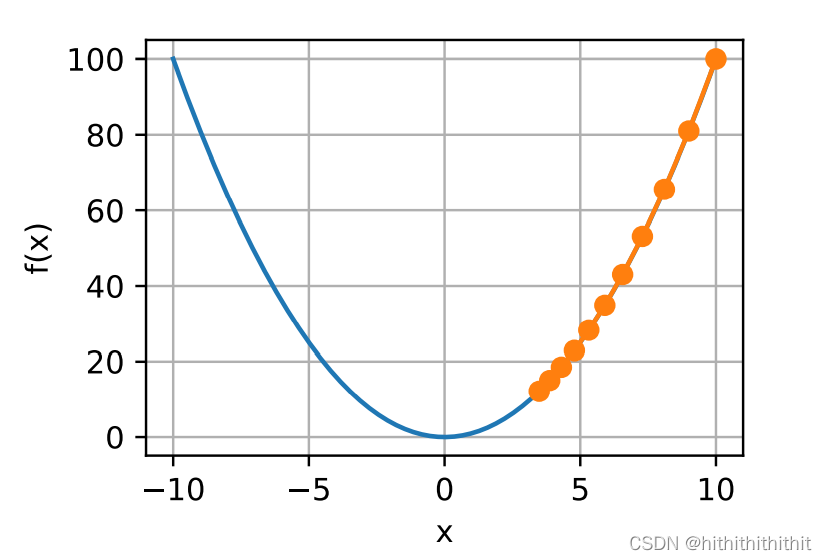
上图第一张图片中由于学习率过大,导致优化的步幅较大,一直来回振荡了多次,仍然没有得到函数的最优解,而第二张图片中由于学习率国小导致在指定的步数中,函数仍然没有得到最优解。而在非凸的问题中却没有那么方便,例如下图。
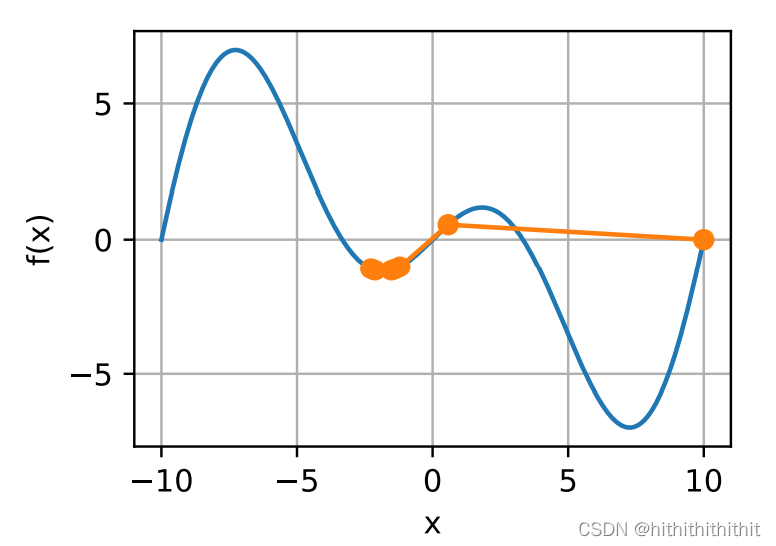
由上图可以看到,即使函数到了局部最小值的点,但是仍然没有获得一个全局的最优解。
三、牛顿法
前面我们介绍了梯度下降的方法,知道梯度下降是利用函数的一阶导求梯度,然后对函数进行极小值的优化。但是一阶导的学习率设置是非常困难的,如何自动确定一个合适的学习率是我们需要的。我们在高数中学习过利用一阶导和二阶导直接求函数的极值点和该点的凹凸性来求解函数的极值点。牛顿法就是利用这个原理来进行的,这样可以大大加快收敛的速度。但是神经网络中的矩阵求导并不是我们手动操作的那么简单,对矩阵进行求逆的时间复杂度很高,且进行反向传播计算可能雪上加霜。且牛顿法对于非凸函数的求解很复杂,需要进行一定的预处理,这就是为什么梯度下降的方法更加收到欢迎的原因。虽然这个方法不能直接应用于深度学习,但它们为如何设计高级优化算法提供了有用的思维直觉。
四、随机梯度下降(SGD)
由于目标函数的计算是成批计算的,即计算所有的样本损失然后取平均值作为样本的一个平均损失。我们设置下面的目标函数,其中是关于索引
的训练样本的损失函数,则目标函数如下
通过上面的目标函数,我们对每个样本进行梯度计算,可以得到梯度计算的公式如下,
如果使用梯度下降方法,则每个自变量迭代的计算代价为,因此,当训练集数据比较多时,每次迭代的梯度下降计算代价将较高。
随机梯度下降在每次迭代的时候,对数据样本随机均匀采样一个索引,并计算梯度
以更新
,这样每个批次迭代的时候只需要相当于对单个样本进行计算梯度最优值,这样大大加快了收敛所需要的时间。此外,随机梯度是对完整梯度的无偏估计,因为
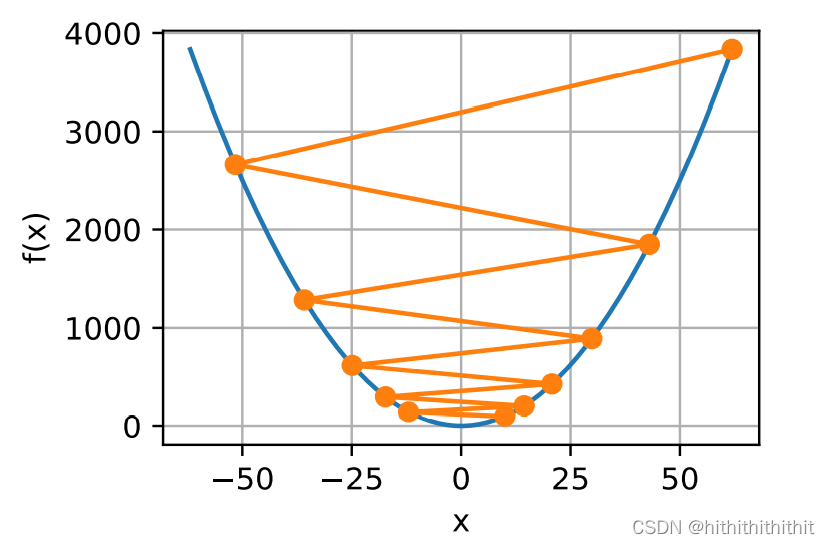
这意味着,就平均而言,随机梯度是对梯度的良好估计。下面给出随机梯度下降的过程模拟。
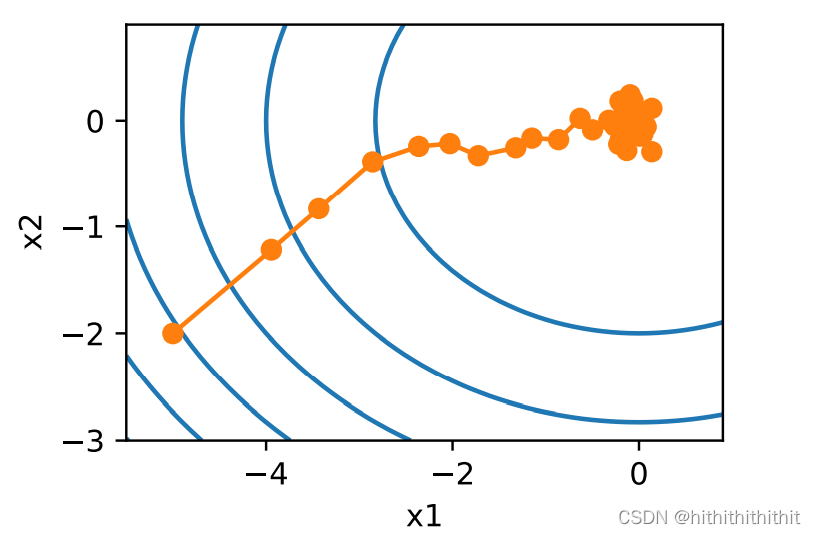
由上图可以看出,在其快要收敛到极值点时,由于采用的是随机梯度,所有每次快要收敛时会不停地震荡。即使经过更多次数的迭代,仍然会不停的震荡,因为一个样本的极值无法代表全体样本的极值点。我们唯一的选择时改变学习率,但是固定的学习率设置的太大或者时太小都会带来不利的影响,所以我们期望使用一个可以变化的学习率来进行步幅的调整。例如,在刚开始的时候,我们使用更大的学习率来快速接近极值点。在快接近极值点时,我们使用较小的学习率一步一步达到极值点,以防学习率过大振荡。
动态学习率
为了解决固定学习率带来的不利影响,我们推出了动态学习率。主要介绍一下几个调整学习率的策略:
分段常数
指数衰减
多项式衰减
分段常数表示在某个阶段会将学习率设置为一个指定的值,指数衰减可以更积极的降低学习率的值,但是会导致算法过早的收敛停止。的多项式衰减时一个比较好用的做法,在凸优化中,这种速率表现良好。
随机梯度和有限样本
随机梯度下降时,我们每次抽取一个样本进行梯度下降,并且将所有的实例遍历了一遍。那么为什么不采用可替换采样呢?即采取有放回的方式,这种情况下,对n个样本执行n次随机抽样会导致样本被选择至少一次的概率为0.63,样本被恰好选择一次的概率为0.37。与无替换采样(即无放回)相比,方差增加且降低了数据的效率,所以随机梯度一般用无替换采样来操作的。
小批量随机梯度下降
前面说的梯度下降和随机梯度下降,每次分别用全部数据来计算梯度和每次使用一个样本来计算梯度皆是有利有弊。每当数据⾮常相似时,梯度下降并不 是⾮常“数据⾼效”。而由于CPU和GPU⽆法充分利⽤向量化,随机梯度下降并不特别“计算⾼效”。这暗⽰ 了两者之间可能有折中⽅案,这便涉及到小批量随机梯度下降(minibatch gradient descent)。
采用小批量随机梯度下降方法的原因一大部分是为了计算的效率,因为如果单纯使用随机梯度下降,那么过大的方差必然导致总体的收敛困难。如果采用总体的梯度下降,那么计算的成本较大。而采用了平均梯度的批量随机梯度下降则很好的对矩阵进行了加速。
五、动量法
对于多个变量有多个梯度的情况下,选取一个固定的学习率显然不是一个好的选择。因为在某些变量的梯度下选取一个固定的学习率可能会很快达到收敛,而在其他梯度下可能还没有达到收敛的状态或者收敛停滞。前面我们提到的动态学习率在同一时刻下仍然是一个固定的值,虽然说比始终固定值的学习率更好,但是仍然没有解决实际的问题。
为此提出了动量法,和之前不太一样的是,动量法考虑了前面更新状态时的梯度大小,将前面状态的梯度作为一个现在动量的因变量求得如今的梯度然后才对其进行更新。具体如下,
使用前面状态的动量和前面状的梯度求得现在的动量,然后根据得到的动量取更新权重参数。
这篇关于略解深度学习优化策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




