本文主要是介绍简析联合索引、覆盖索引、MRR优化、ICP优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简析联合索引、覆盖索引、MRR优化、ICP优化
- 联合索引
- 覆盖索引
- 优化器选择不使用索引的情况
- Multi-Range Read(MRR)优化
- Index Condition Pushdown(ICP)优化
联合索引
与建立单个索引的方式相同,不过联合索引有多个索引列,且不同的列有严格的先后顺序。
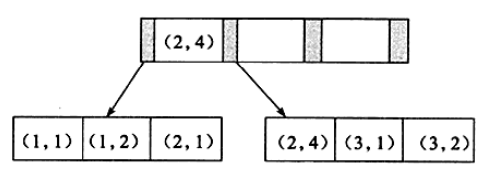
如图所示,为一个由两个整形列组成的联合索引的索引结构。同单个键值的索引一样,联合索引的键值也在叶子节点上排序,按照第一个列为主要关键字,第二个列为次要关键字的顺序。这样的顺序就决定了联合索引查找的“最左匹配”原则。
SELECT * FROM TABLE WHERE a=xxx and b=xxx;
这样的查询语句完美匹配了联合索引。
SELECT * FROM TABLE WHERE a=xxx ;
这个查询虽然不完全匹配,但通过观察发现,联合索引中已经按照a列进行了排序(a为主要关键字),已经满足了这次查询需要的索引,因此这次查询也会使用联合索引。
SELECT * FROM TABLE WHERE b=xxx ;
虽然b也在联合索引之中,但是b并不是主要关键字,实际的顺序是先按照a排序,再按照b排序的,要想直接查询b,在这个索引中是无法绕开a的,也就是说这些全部数据对于b来说是无序的,因此不可以使用联合索引。
同样,对于需要对a查找,并将结果对b排序,也适用联合索引
SELECT * FROM TABLE WHERE a=xxx ORDER BY b ;
知道了两列的联合索引后,更多列的联合索引的原理也是同理。
例如,建立联合索引(a,b,c),下面的查询并不会直接得出结果
SELECT * FROM TABLE WHERE a=xxx ORDER BY c ;
因为逻辑顺序是先按照a列排序,再按照b列排序,再按照c列排序,因此查找a后得到的结果首先是按照b排序的,并不是按照c排序的。这正是最左匹配原则。
覆盖索引
覆盖索引,又称为索引覆盖。在辅助索引的叶子节点上保存着键值和书签,通常我们需要拿到书签后再用聚集索引查到数据。如果我们需要的数据恰好就是辅助索引叶子节点上保存的键值,那么书签就没用了,不需要再用聚集索引去查找了,这就成为覆盖索引。这有一个好处,辅助索引不包含整行记录,所占空间极小,所以相比聚集索引可以减少大量的IO操作,节省时间。
另一方面,在使用聚合函数查询,例如统计总数时,也会进行覆盖索引。同理,因为它不需要知道详细数据,仅从辅助索引就可以得到答案,而且辅助索引的IO操作更少。
此外,通常情况下,对于(a,b)的联合索引,是不可以跳过a,直接选择b进行查询的,因为并不是按照b来排序的。但是对于b的统计操作,只需要数量而不需要内容的情况下,虽然选择联合索引与否,都需要全部扫描,但是相对聚集索引来说,使用该联合索引可以利用到覆盖索引,从而在满足要求的前提下减少IO操作。
优化器选择不使用索引的情况
这种情况多发生于范围查找、JOIN链接操作等情况。下面举一个范围查找的例子。
SELECT * FROM t WHERE orderid>10000 and orderid<102000;
表t建立了对于列OrderID的辅助索引。显然,该查询可以利用这个辅助索引快速定位到需要查询的行数据。
然而实际上,查询优化器并没有使用这个索引。
查询优化器使用了聚集索引,也就是表扫描。
原因在于,辅助索引的叶子节点保存的只是键值和书签,该查询查的是整行,并不能利用覆盖索引,所以,虽然辅助索引中找到书签的速度很快,但利用这些书签去聚集索引中找到全部数据的过程将会非常漫长。因为这个过程是无序的,只能一次一次查找,变成了磁盘上的离散读。如果查询的数据数量很少,还是可以使用辅助索引的,但此查询数据量极大(20%左右),还不如全表扫描(顺序读要远远快于离散读)。
Multi-Range Read(MRR)优化
MySQL5.6版本开始支持MRR优化。主要目的是为了减少对磁盘的随机访问,将其转化为较为顺序的数据访问。适用于range,ref,eq_ref类型的查询。
有如下几个好处
- 使数据访问变得较为顺序。辅助索引查询得到书签后,先对主键进行排序,再按序进行查找
- 减少缓冲池中页被替换的次数
- 批量处理对键值的查询操作
具体操作步骤如下
- 先把查询到的辅助索引键值放在缓存中(此时是自然的按照辅助索引键值排序的)
- 将这些键值按照主键进行排序
- 将排序后的主键使用聚集索引查找
此外,如果缓冲池不够大,在查找某一条时,读进该页,这页会很快被移出缓冲池。如果查找是没有顺序的,可能这页被移除后,很快又要被读进来。这样对同一页反复移入移出,会有很大的消耗。而如果查找是有顺序的,将会极大地避免这种情况。
MRR还可以将某些范围查询,拆分为键值对,以此来进行批量数据查询。这样可以在拆分过程中,直接过滤掉一些不符合查询条件的数据。例如:
SELECT * FROM t WHERE a>=1000 AND a<2000 AND b =1000;
表中建有(a,b)的联合索引。如果没有MRR优化,优化器将会先把满足a>=1000 AND a<2000的所有数据取出,待到取出完后再根据 b =1000的条件进行过滤。这样会使很多无用数据被取出,如果无用数据数量很多,将会浪费很多时间。
启用了MRR优化后,优化器先将查询条件拆分,(1000,1000)(1001,1000)(1002,1000)……根据这些条件进行查询,这样取出的数据就都是有用的数据了。
Index Condition Pushdown(ICP)优化
ICP也是MySQL5.6后开始支持的一种根据索引进行查询的优化方式。以往,我们会根据索引查找记录,再根据WHERE条件来过滤记录。使用ICP优化后,会在取出索引的同时,直接根据WHERE条件过滤,将WHERE的部分过滤操作放在了存储引擎层。在某些查询下可以大大减少上层SQL层对记录的索取,从而提高性能。
例如:
SELECT * FROM t WHERE a=2000 AND b LIKE '%street%';
这张表有联合索引(a,b),如果没有ICP优化,会通过索引找到并取出a=2000的记录后,再过滤WHERE的另一个条件,因为索引对b LIKE '%street%'这个条件并没有任何帮助作用。如果使用了ICP优化,就会在找到索引后,直接进行WHERE条件的过滤(因为这个是联合索引,索引中也有关于列b的值),然后再去获取记录。这将极大的提高查询效率。
同理,如果要查询的两个条件中,一个建立了辅助索引,另一个是聚集索引,也可以使用ICP优化,因为辅助索引的叶子节点中也有聚集索引键(书签)。
参考《MySQL技术内幕:InnoDB存储引擎》
这篇关于简析联合索引、覆盖索引、MRR优化、ICP优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



