本文主要是介绍MapReduce编程开发之求平均成绩,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MapReduce计算平均成绩是一个常见的算法,本省思路很简单,就是将每个人的成绩汇总,然后做除法,在map阶段,是直接将姓名做key,分数作为value输出。在shuffle阶段,会将每个人的所有成绩做汇总,数据结构变为<name,<score1,score2...>>这样子,我们在reduce阶段就通过分数这个value-list来结算平均分。average = sum(score)/courseCount,即平均分等于分数总和除以课程数。
mapreduce代码:
package com.xxx.hadoop.mapred;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** 求平均成绩**/
public class AverageScoreApp {public static class Map extends Mapper<Object, Text, Text, IntWritable>{@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)throws IOException, InterruptedException {//成绩的结构是:// 张三 80// 李四 82// 王五 86StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\n");while(tokenizer.hasMoreElements()) {StringTokenizer lineTokenizer = new StringTokenizer(tokenizer.nextToken());String name = lineTokenizer.nextToken(); //姓名String score = lineTokenizer.nextToken();//成绩context.write(new Text(name), new IntWritable(Integer.parseInt(score)));}}}public static class Reduce extends Reducer<Text, IntWritable, Text, DoubleWritable>{@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, DoubleWritable>.Context context)throws IOException, InterruptedException {//reduce这里输入的数据结构是:// 张三 <80,85,90>// 李四 <82,88,94>// 王五 <86,80,92>int sum = 0;//所有课程成绩总分double average = 0;//平均成绩int courseNum = 0; //课程数目for(IntWritable score:values) {sum += score.get();courseNum++;}average = sum/courseNum;context.write(new Text(key), new DoubleWritable(average));}}public static void main(String[] args) throws Exception{String input="/user/root/averagescore/input",output="/user/root/averagescore/output";System.setProperty("HADOOP_USER_NAME", "root");Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://192.168.56.202:9000");Job job = Job.getInstance(conf);job.setJarByClass(AverageScoreApp.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(DoubleWritable.class);FileInputFormat.addInputPath(job, new Path(input));FileOutputFormat.setOutputPath(job, new Path(output));System.exit(job.waitForCompletion(true)?0:1);}}
准备学生成绩数据:
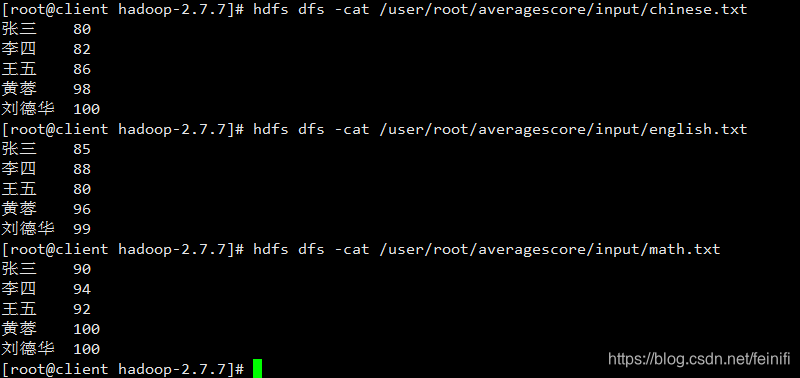
控制台打印信息:
2019-08-31 15:50:26 [INFO ] [main] [org.apache.hadoop.conf.Configuration.deprecation] session.id is deprecated. Instead, use dfs.metrics.session-id
2019-08-31 15:50:26 [INFO ] [main] [org.apache.hadoop.metrics.jvm.JvmMetrics] Initializing JVM Metrics with processName=JobTracker, sessionId=
2019-08-31 15:50:27 [WARN ] [main] [org.apache.hadoop.mapreduce.JobResourceUploader] Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2019-08-31 15:50:27 [WARN ] [main] [org.apache.hadoop.mapreduce.JobResourceUploader] No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2019-08-31 15:50:27 [INFO ] [main] [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] Total input paths to process : 3
2019-08-31 15:50:27 [INFO ] [main] [org.apache.hadoop.mapreduce.JobSubmitter] number of splits:3
2019-08-31 15:50:27 [INFO ] [main] [org.apache.hadoop.mapreduce.JobSubmitter] Submitting tokens for job: job_local83653871_0001
2019-08-31 15:50:27 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] The url to track the job: http://localhost:8080/
2019-08-31 15:50:27 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] Running job: job_local83653871_0001
2019-08-31 15:50:27 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] OutputCommitter set in config null
2019-08-31 15:50:27 [INFO ] [Thread-3] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] File Output Committer Algorithm version is 1
2019-08-31 15:50:27 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2019-08-31 15:50:27 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] Waiting for map tasks
2019-08-31 15:50:27 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Starting task: attempt_local83653871_0001_m_000000_0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] File Output Committer Algorithm version is 1
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] ProcfsBasedProcessTree currently is supported only on Linux.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@52fc070c
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Processing split: hdfs://192.168.56.202:9000/user/root/averagescore/input/math.txt:0+55
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] (EQUATOR) 0 kvi 26214396(104857584)
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] mapreduce.task.io.sort.mb: 100
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] soft limit at 83886080
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396; length = 6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner]
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Starting flush of map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Spilling map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufend = 58; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396(104857584); kvend = 26214380(104857520); length = 17/6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Finished spill 0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task:attempt_local83653871_0001_m_000000_0 is done. And is in the process of committing
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] map
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task 'attempt_local83653871_0001_m_000000_0' done.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Finishing task: attempt_local83653871_0001_m_000000_0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Starting task: attempt_local83653871_0001_m_000001_0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] File Output Committer Algorithm version is 1
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] ProcfsBasedProcessTree currently is supported only on Linux.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@3f0602b3
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Processing split: hdfs://192.168.56.202:9000/user/root/averagescore/input/chinese.txt:0+54
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] (EQUATOR) 0 kvi 26214396(104857584)
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] mapreduce.task.io.sort.mb: 100
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] soft limit at 83886080
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396; length = 6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner]
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Starting flush of map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Spilling map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufend = 58; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396(104857584); kvend = 26214380(104857520); length = 17/6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Finished spill 0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task:attempt_local83653871_0001_m_000001_0 is done. And is in the process of committing
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] map
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task 'attempt_local83653871_0001_m_000001_0' done.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Finishing task: attempt_local83653871_0001_m_000001_0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Starting task: attempt_local83653871_0001_m_000002_0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] File Output Committer Algorithm version is 1
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] ProcfsBasedProcessTree currently is supported only on Linux.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@47fe69f7
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Processing split: hdfs://192.168.56.202:9000/user/root/averagescore/input/english.txt:0+53
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] (EQUATOR) 0 kvi 26214396(104857584)
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] mapreduce.task.io.sort.mb: 100
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] soft limit at 83886080
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396; length = 6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner]
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Starting flush of map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Spilling map output
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] bufstart = 0; bufend = 58; bufvoid = 104857600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] kvstart = 26214396(104857584); kvend = 26214380(104857520); length = 17/6553600
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.MapTask] Finished spill 0
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task:attempt_local83653871_0001_m_000002_0 is done. And is in the process of committing
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] map
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.Task] Task 'attempt_local83653871_0001_m_000002_0' done.
2019-08-31 15:50:28 [INFO ] [LocalJobRunner Map Task Executor #0] [org.apache.hadoop.mapred.LocalJobRunner] Finishing task: attempt_local83653871_0001_m_000002_0
2019-08-31 15:50:28 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] map task executor complete.
2019-08-31 15:50:28 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] Waiting for reduce tasks
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] Starting task: attempt_local83653871_0001_r_000000_0
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] File Output Committer Algorithm version is 1
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] ProcfsBasedProcessTree currently is supported only on Linux.
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Task] Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4309aafd
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.ReduceTask] Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@44113ec8
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] MergerManager: memoryLimit=1265788544, maxSingleShuffleLimit=316447136, mergeThreshold=835420480, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2019-08-31 15:50:28 [INFO ] [EventFetcher for fetching Map Completion Events] [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] attempt_local83653871_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] localfetcher#1 about to shuffle output of map attempt_local83653871_0001_m_000000_0 decomp: 70 len: 74 to MEMORY
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] Read 70 bytes from map-output for attempt_local83653871_0001_m_000000_0
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] closeInMemoryFile -> map-output of size: 70, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->70
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] localfetcher#1 about to shuffle output of map attempt_local83653871_0001_m_000001_0 decomp: 70 len: 74 to MEMORY
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] Read 70 bytes from map-output for attempt_local83653871_0001_m_000001_0
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] closeInMemoryFile -> map-output of size: 70, inMemoryMapOutputs.size() -> 2, commitMemory -> 70, usedMemory ->140
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] localfetcher#1 about to shuffle output of map attempt_local83653871_0001_m_000002_0 decomp: 70 len: 74 to MEMORY
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] Read 70 bytes from map-output for attempt_local83653871_0001_m_000002_0
2019-08-31 15:50:28 [INFO ] [localfetcher#1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] closeInMemoryFile -> map-output of size: 70, inMemoryMapOutputs.size() -> 3, commitMemory -> 140, usedMemory ->210
2019-08-31 15:50:28 [INFO ] [EventFetcher for fetching Map Completion Events] [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] EventFetcher is interrupted.. Returning
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] 3 / 3 copied.
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] finalMerge called with 3 in-memory map-outputs and 0 on-disk map-outputs
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Merger] Merging 3 sorted segments
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Merger] Down to the last merge-pass, with 3 segments left of total size: 174 bytes
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] Merged 3 segments, 210 bytes to disk to satisfy reduce memory limit
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] Merging 1 files, 210 bytes from disk
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] Merging 0 segments, 0 bytes from memory into reduce
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Merger] Merging 1 sorted segments
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Merger] Down to the last merge-pass, with 1 segments left of total size: 194 bytes
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] 3 / 3 copied.
2019-08-31 15:50:28 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] Job job_local83653871_0001 running in uber mode : false
2019-08-31 15:50:28 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] map 100% reduce 0%
2019-08-31 15:50:28 [INFO ] [pool-6-thread-1] [org.apache.hadoop.conf.Configuration.deprecation] mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Task] Task:attempt_local83653871_0001_r_000000_0 is done. And is in the process of committing
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] 3 / 3 copied.
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Task] Task attempt_local83653871_0001_r_000000_0 is allowed to commit now
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] Saved output of task 'attempt_local83653871_0001_r_000000_0' to hdfs://192.168.56.202:9000/user/root/averagescore/output/_temporary/0/task_local83653871_0001_r_000000
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] reduce > reduce
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.Task] Task 'attempt_local83653871_0001_r_000000_0' done.
2019-08-31 15:50:29 [INFO ] [pool-6-thread-1] [org.apache.hadoop.mapred.LocalJobRunner] Finishing task: attempt_local83653871_0001_r_000000_0
2019-08-31 15:50:29 [INFO ] [Thread-3] [org.apache.hadoop.mapred.LocalJobRunner] reduce task executor complete.
2019-08-31 15:50:29 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] map 100% reduce 100%
2019-08-31 15:50:29 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] Job job_local83653871_0001 completed successfully
2019-08-31 15:50:29 [INFO ] [main] [org.apache.hadoop.mapreduce.Job] Counters: 35File System CountersFILE: Number of bytes read=4456FILE: Number of bytes written=1087800FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=488HDFS: Number of bytes written=63HDFS: Number of read operations=33HDFS: Number of large read operations=0HDFS: Number of write operations=6Map-Reduce FrameworkMap input records=15Map output records=15Map output bytes=174Map output materialized bytes=222Input split bytes=393Combine input records=0Combine output records=0Reduce input groups=5Reduce shuffle bytes=222Reduce input records=15Reduce output records=5Spilled Records=30Shuffled Maps =3Failed Shuffles=0Merged Map outputs=3GC time elapsed (ms)=27Total committed heap usage (bytes)=1493172224Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=162File Output Format Counters Bytes Written=63
运行完毕,查看结果:

这篇关于MapReduce编程开发之求平均成绩的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







