本文主要是介绍一文带你深入浅出 MongoEngine 经典查询【内附详细案例】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、 查询数据库(所有)
- 二、 过滤查询(单个、条件)
- 1. 查单个
- 2. 可用的过滤查询运算符
- 3. 过滤查询运算符使用示范
- 三、字符串查询(模糊)
- 1. 可用的模糊查询运算符
- 2. 模糊查询运算符使用示范
- 四、原始查询 ( _ _ raw _ _ )
- 1. 原始查询详解
- 2. 原始查询示例
- 五、排序 / 排序结果( +、- )
- 六、限制和跳过结果( [ ]、first() )
- 七、聚合查询
- 1. 求和
- 2. 求平均值
- 3. 计数
- 4. 求频率
- 总结
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
一、 查询数据库(所有)
- 在MongoEngine中,要查询 MongoDB 数据库中的所有文档,你可以使用模型的 objects 属性并选择性调用 all() 方法。
books = Books.objects
books2 = Books.objects.all()

- Document 类有一个 objects 属性,用于访问与类关联的数据库中的对象。该 objects 属性实际上是一个 QuerySetManager,它在访问时创建并返回一个新 QuerySet 对象。可以迭代该 QuerySet 对象以从数据库中获取文档:
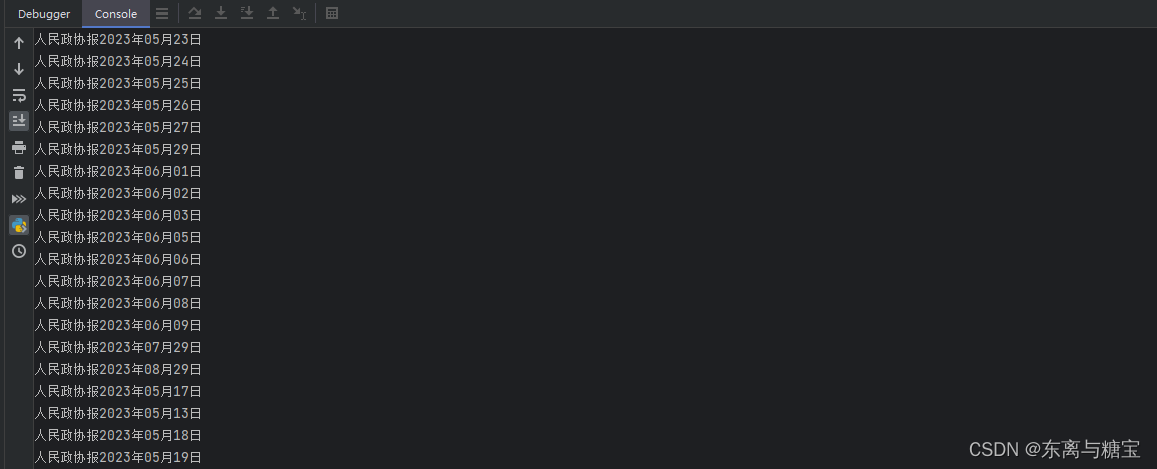
for book in Books.objects:print (book.bookName)
二、 过滤查询(单个、条件)
1. 查单个
在 MongoEngine 中,要查询单个文档,你可以使用 first() 方法或 get() 方法,具体取决于你的需求和查询条件。
1. 使用 first() 方法来查询第一个符合条件的文档
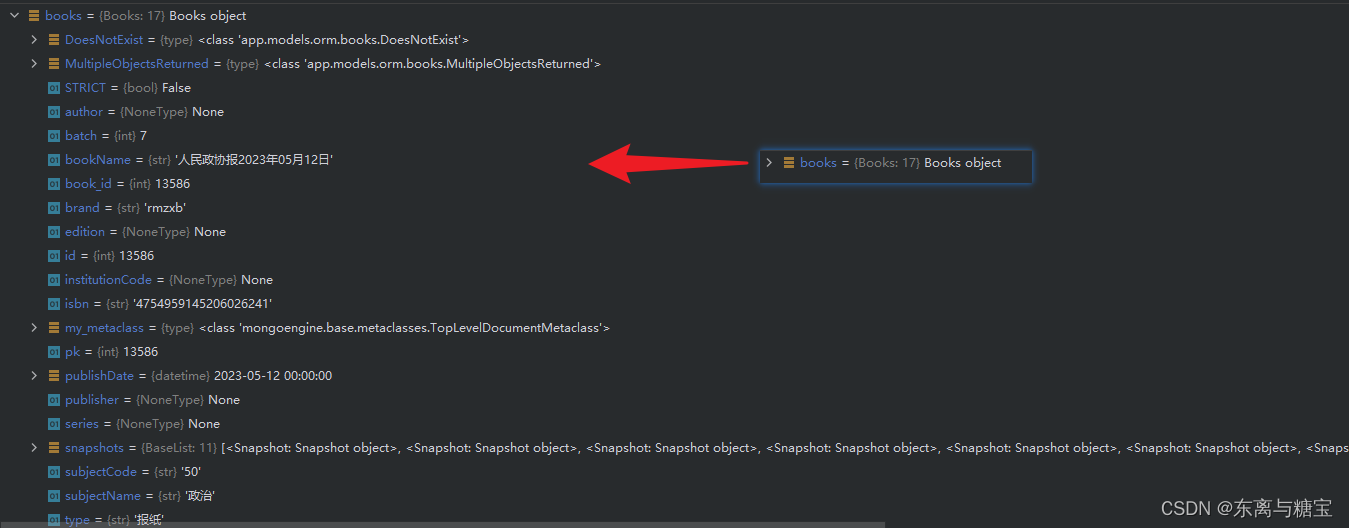
# 查询第一个 brand 字段名称为 rmzxb 的报纸
books = Books.objects(brand='rmzxb').first()
2. 使用 get() 方法来查询符合条件的唯一文档(如果存在)
-
要检索集合中应唯一的结果,请使用 get() 。如果没有与查询匹配的文档,并且 MultipleObjectsReturned 有多个文档与查询匹配,则会引发 DoesNotExist 此值。这些异常将合并到您的文档定义中,例如:MyDoc.DoesNotExists
-
这种方法的变体get_or_create()存在,但它不安全。它不能被安全,因为mongoDB中没有事务。应调查其他方法,以确保在使用与此方法类似的方法时不会意外复制数据。因此,它在 0.8 中被弃用,在 0.10 中被删除。
-
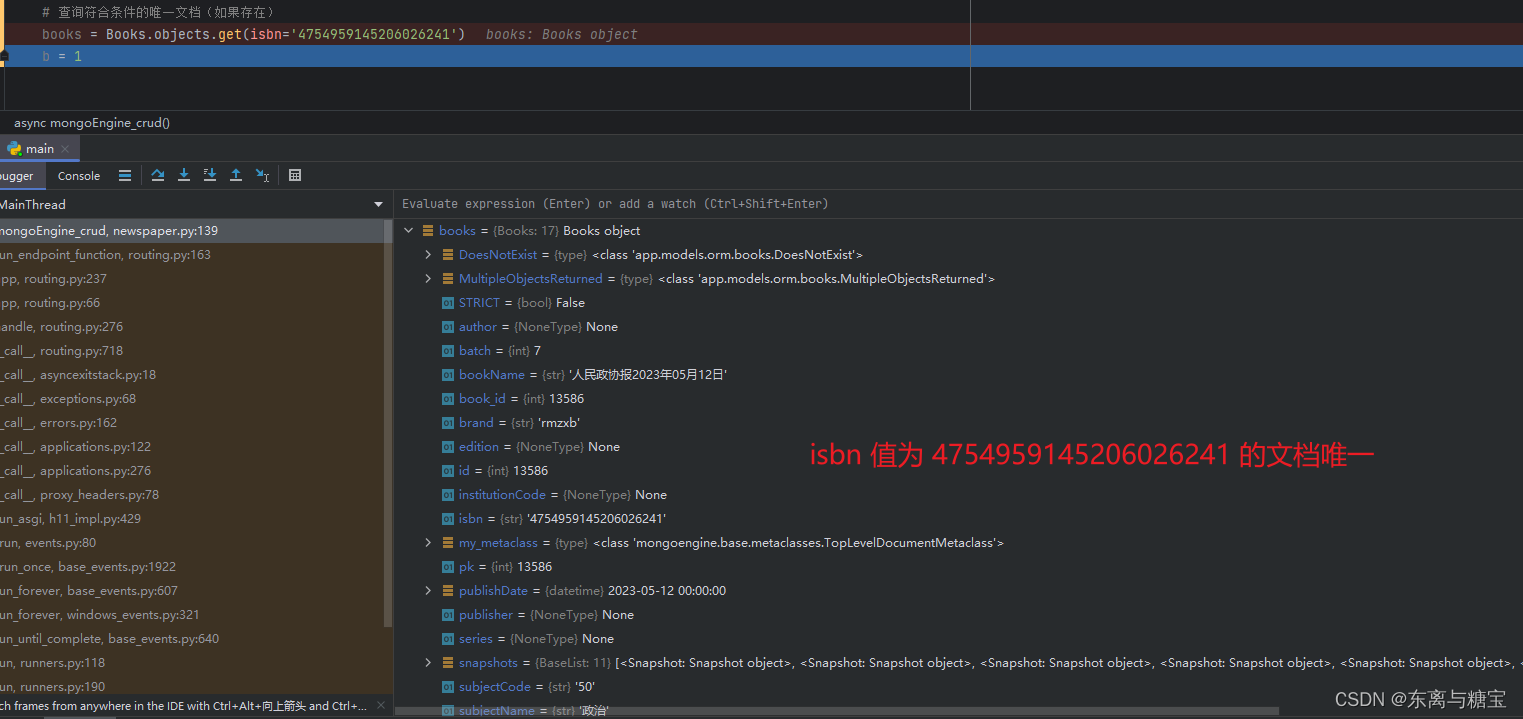
查询成功示例
# 查询符合条件的唯一文档(如果存在)
books = Books.objects.get(isbn='4754959145206026241')
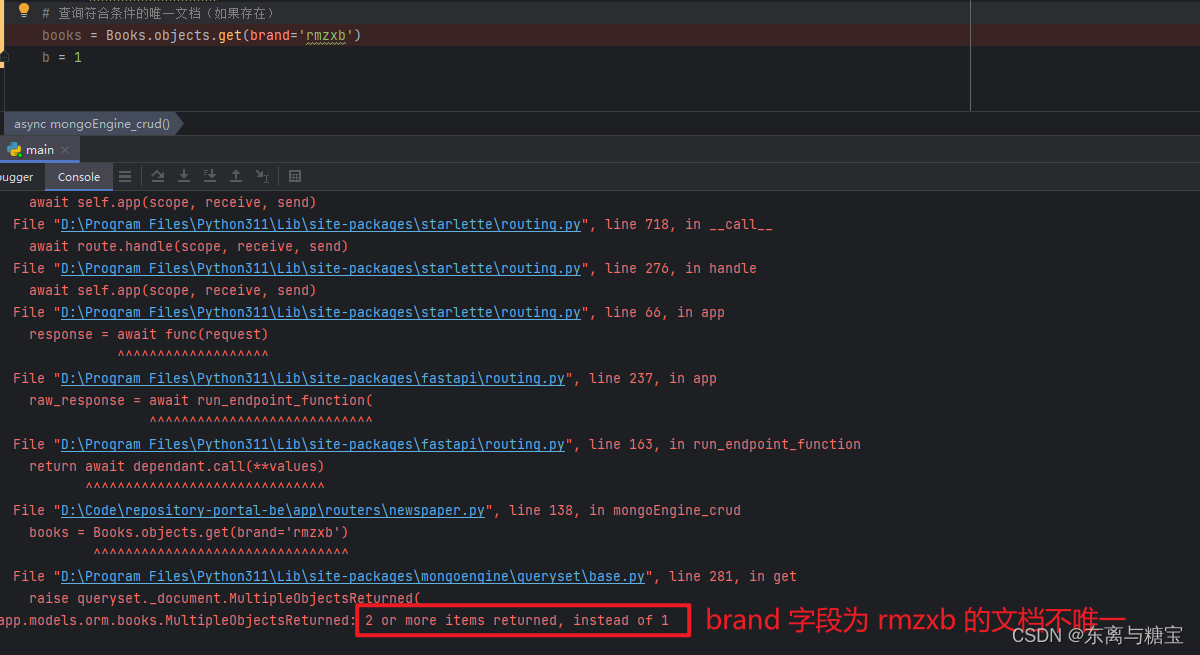
- 查询失败示例
# 查询符合条件的唯一文档(如果存在)
books = Books.objects.get(brand='rmzxb')
2. 可用的过滤查询运算符
| 作用 | 符号表示 | 英文全称 |
|---|---|---|
| 不等于 | ne | not equal to |
| 小于 | lt | less than |
| 小于或等于 | lte | less than or equal to |
| 大于 | gt | greater than |
| 大于或等于 | gte | greater than or equal to |
| 否定标准检查,可以在其他运算符之前使用,例如查询年龄不是5的倍数的文档:Q (age_ not _mod=(5, 0)) | not | |
| 值在列表中(应提供值列表) | in | |
| 值不在列表中(应提供值列表) | nin | |
| 查询年龄字段满足模数条件的文档,例如,年龄除以5的余数等于1的文档result = Person.objects(age_ _mod=(5, 1)) | mod | |
| 提供的值列表中的每个项目都在数组中,例如使用 all 方法查询包含所有指定兴趣爱好的人员 people = Person.objects(hobbies_ _all=hobbies) | all | |
| 数组的大小,例如使用 size 方法查询具有特定数量兴趣爱好的人员 count = Person.objects(hobbies_ _size=hobby) | size | |
| 字段值存在,例如 使用 exists() 方法查询包含 name 字段的文档people_with_name = Person.objects(name_ _exists=True) | exists |
3. 过滤查询运算符使用示范
- 查询日期小于 2023-05-25 的报纸
presentPublishDate = '2023-05-25T00:00:00.000+00:00'
book = Books.objects(publishDate__exists=True, publishDate__lt=presentPublishDate)

- 查询 isbn 在列表中的报纸
isbns = ['4759307800083959809','4760032575949377537']
book = Books.objects(isbn__in=isbns)

三、字符串查询(模糊)
1. 可用的模糊查询运算符
| 作用 | 字符表示 |
|---|---|
| 字符串字段完全匹配值 | exact |
| 字符串字段完全匹配值(不区分大小写) | iexact |
| 字符串字段包含值 | contains |
| 字符串字段包含值(不区分大小写) | icontains |
| 字符串字段以值开头 | startswith |
| 字符串字段以值开头(不区分大小写) | istartswith |
| 字符串字段以值结尾 | endswith |
| 字符串字段以值结尾(不区分大小写) | iendswith |
| 字符串字段包含整个单词 | wholeword |
| 字符串字段包含整个单词(不区分大小写) | iwholeword |
| 正则表达式的字符串字段匹配 | regex |
| 正则表达式的字符串字段匹配(不区分大小写) | iregex |
| 执行$elemMatch,以便您可以匹配数组中的整个文档 | match |
2. 模糊查询运算符使用示范
- 查询文章标题包含指定字符串的报纸
title_input = '回信勉励海军'
article = Cards.objects(title__contains=title_input).first()
四、原始查询 ( _ _ raw _ _ )
1. 原始查询详解
-
在 MongoEngine 中,你可以使用原始查询来执行 MongoDB 查询语句,这允许你直接发送 MongoDB 查询命令而不受 MongoEngine API 的限制。原始查询在需要执行复杂的或特殊的查询时非常有用,因为它们允许你直接编写 MongoDB 查询语句。
-
可以提供原始 PyMongo 查询作为查询参数,该参数将直接集成到查询中。这是使用 raw 关键字参数完成的:
Page.objects(__raw__={'tags': 'coding'})
- 同样,可以为该方法 update() 提供原始更新:
Page.objects(tags='coding').update(__raw__={'$set': {'tags': 'coding'}})
- 而两者也可以结合起来:
Page.objects(__raw__={'tags': 'coding'}).update(__raw__={'$set': {'tags': 'coding'}})
- 请注意,原始查询允许你执行复杂的查询,但也需要小心使用,因为它们绕过了 MongoEngine 的对象映射和验证。确保你的原始查询语句正确且安全,以避免潜在的安全问题。
2. 原始查询示例
- 查询 id 在指定范围内并且 snapshots 字段值不为 0 的报纸
book_ids = [13586,13849,13871]
sm = {'_id': {'$in': book_ids}, 'snapshots.0': {'$exists': True}}
docs: Books = Books.objects(__raw__=sm)

五、排序 / 排序结果( +、- )
可以使用 按 order_by() 1 个或多个键对结果进行排序。可以通过在每个键前面加上“+”或“-”来指定顺序。如果没有前缀,则假定按升序排列。
# Order by ascending date
blogs = BlogPost.objects().order_by('date') # equivalent to .order_by('+date')# Order by ascending date first, then descending title
blogs = BlogPost.objects().order_by('+date', '-title')
六、限制和跳过结果( [ ]、first() )
- 与传统 ORM 一样,我们可以限制返回的结果数量或跳过查询中的数字或结果。 limit() 和 skip() 方法在对象上 QuerySet 可用,但数组切片语法是实现此目的的首选:
# Only the first 5 people
users = User.objects[:5]# All except for the first 5 people
users = User.objects[5:]# 5 users, starting from the 11th user found
users = User.objects[10:15]
- 还可以为查询编制索引以检索单个结果。如果该索引中的项目不存在,则将引发 。 IndexError 提供了检索第一个结果并在不存在结果时返回 None 的快捷方式 ( first() ):
# Make sure there are no users
>>>User.drop_collection()
>>>User.objects[0]
IndexError: list index out of range
>>>User.objects.first() == None
True
>>>User(name='Test User').save()
>>>User.objects[0] == User.objects.first()
True
七、聚合查询
1. 求和
- 我们可以使用以下命令对 sum() 文档上特定字段的值求和:
yearly_expense = Employee.objects.sum('salary')
- 如果文档中不存在该字段,则该文档将从总和中忽略。
2. 求平均值
- 要获取文档集合上字段的平均值,请使用 average() :
mean_age = User.objects.average('age')
3. 计数
- 就像限制和跳过结果一样, QuerySet 对象上有一个方法 – count() :
num_users = User.objects.count()
-
从技术上讲,我们可以使用 来 len(User.objects) 获得相同的结果,但它会比 慢 count() 得多。当您执行服务器端计数查询时,您让MongoDB完成繁重的工作,并通过网络接收单个整数。同时,检索所有结果,将它们放在本地缓存中, len() 最后对它们进行计数。如果我们比较这两个操作的性能, len() 比 慢得多 count()
-
示例
book_ids = [13586,13849,13871]
sm = {'_id': {'$in': book_ids}, 'snapshots.0': {'$exists': True}}
count = client.get_db()['books'].count(sm)

4. 求频率
由于MongoDB提供本机列表,MongoEngine提供了一个辅助方法来获取整个集合中列表中项目频率的字典 - item_frequencies() 。它的使用示例是生成“标签云”:
class Article(Document):tag = ListField(StringField())# After adding some tagged articles...
tag_freqs = Article.objects.item_frequencies('tag', normalize=True)from operator import itemgetter
top_tags = sorted(tag_freqs.items(), key=itemgetter(1), reverse=True)[:10]
总结
欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
这篇关于一文带你深入浅出 MongoEngine 经典查询【内附详细案例】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







