本文主要是介绍一些常见分布-正态分布、对数正态分布、伽马分布、卡方分布、t分布、F分布等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
正态分布
对数正态分布
伽马分布
伽马函数
贝塔函数
伽马分布
卡方分布
F分布
t分布
附录
参考文献
本文主要介绍一些常见的分布,包括正态分布、对数正态分布、伽马分布、卡方分布、F分布、t分布。给出了分布的定义,推导了概率密度函数,以及函数图像。
正态分布

当,称为标准正态分布,即
。
对数正态分布
对数正态分布(logarithmic normal distribution)是指一个随机变量的对数服从正态分布,则该随机变量服从对数正态分布。对数正态分布从短期来看,与正态分布非常接近。但长期来看,对数正态分布向上分布的数值更多一些。

证明:
假设服从的正态分布为
,概率密度函数为
,
服从的分布为
,概率密度函数为
。显然有
。
下面证明的概率密度函数
表达式如上面所示。
一般我们通过分布函数和概率的定义来证明。
,因为
,则
,
即
,两边对
求导,得到:
,即:
,注意到正态分布概率密度函数
如下:

代入后,可得到表达式如上面所示。
伽马分布
伽马函数
在介绍伽马分布之前,我们先对伽马函数有一个基本理解,伽马函数如下:
![]()
是自变量。伽马函数图像如下:
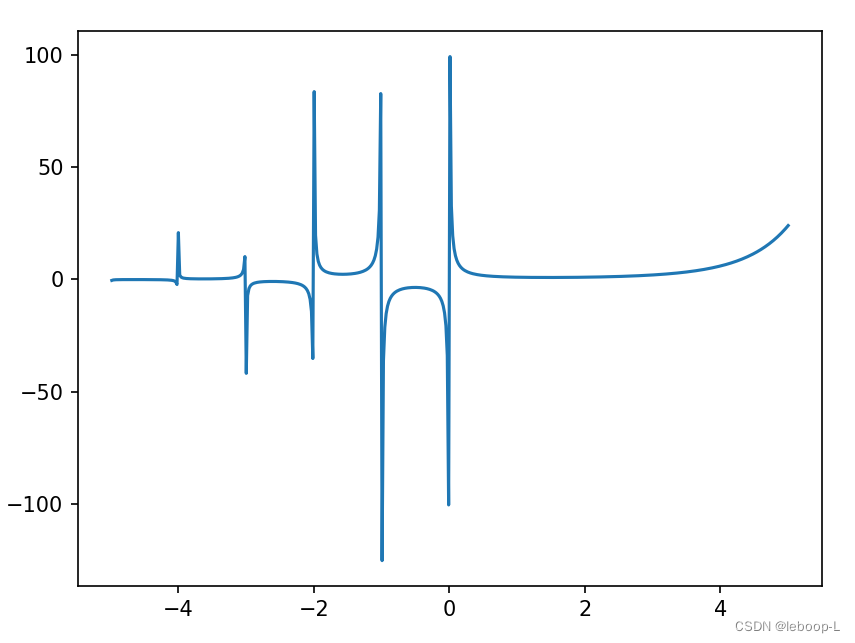
伽马函数图像绘制代码,如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import gammaif __name__ == '__main__':x = np.linspace(-5, 5, 500) # -5到5之间生成500个点y = gamma(x) # 计算y的值,也就是伽马函数的值plt.plot(x, y)plt.show() 为了后面方便推导卡方分布,这里我们证明 。
下面利用标准正态分布的概率密度函数曲线下的面积为1来证明。即:
由正态分布对称性,得到
令进行换元,
因为伽马函数如下:
![]()
知道
伽马函数还有其他很多的函数表达式,这里不再累述。
贝塔函数
在概率统计和其他应用学科中会经常用到伽玛函数和贝塔函数,有的反常积分的计算最后也会归结为贝塔函数或伽玛函数。贝塔函数又称为第一类欧拉积分,而第二类欧拉积分就是大名鼎鼎的伽玛函数Γ(x。贝塔函数具有很好的性质,以及实用的递推公式,另外需要注意的是伽玛函数和贝塔函数之间的关系。贝塔函数如下:
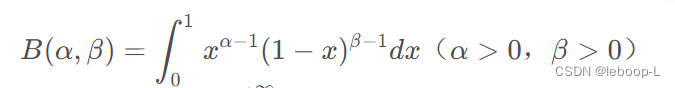
贝塔函数是一个积分形式,为参数。
下面推导伽马函数与贝塔函数之间存在的关系。我们先给出他们的关系:
由伽马函数:
![]()
得到
使用如下积分换元,即
容易得到,并且s=0时,v=1,
时,v=0。变换前后微元关系如下:
则换元后,原式如下:
即:
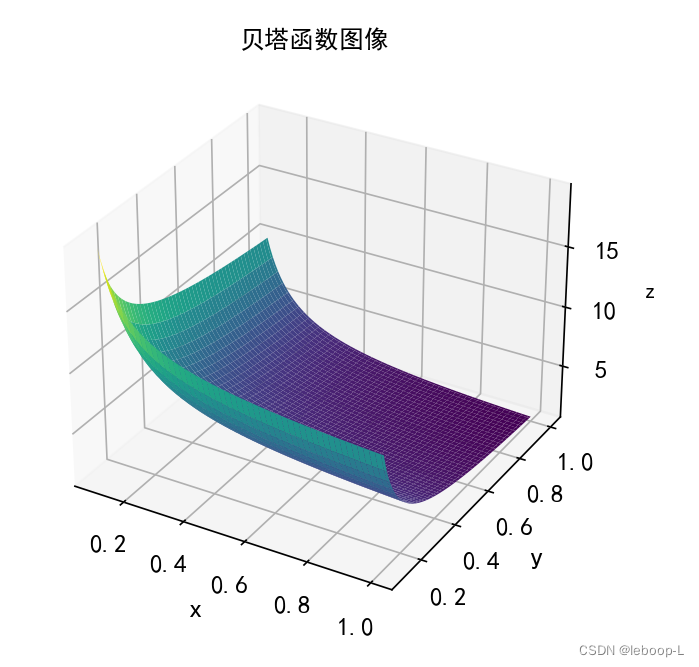
为了直观地理解贝塔函数,下面我们绘制出贝塔函数的三维曲面图像。代码如下:
import numpy as np
from scipy.special import beta
import matplotlib.pyplot as pltif __name__ == '__main__':# 创建一个网格x, y = np.meshgrid(np.linspace(0.1, 1, 100), np.linspace(0.1, 1, 100))print('x=', '\n', x)print('y=', '\n', y)z = beta(x, y)print('z=', '\n', z)plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')ax.tick_params(axis="both", labelsize=12)ax.plot_surface(x, y, z, cmap='viridis')ax.set_xlabel('x', fontsize=13)ax.set_ylabel('y', fontsize=13)ax.set_zlabel('z')ax.set_title('贝塔函数图像')plt.show()
运行结果,如下:
伽马分布
从定义可以看到,伽马分布的概率密度函数的分母中就是伽马函数。 可以通过scipy提供的统计库stats,绘制出正态分布、对数正态分布、伽马分布的概率密度函数曲线,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma as gamma_dis
from scipy.stats import lognorm
from scipy.stats import normif __name__ == '__main__':alpha = 2 # 伽马分布的形状参数theta = 2 # 伽马分布的比例参数# 创建一个 sample spacex = np.linspace(0, 10, 200)# 计算概率密度函数 (PDF)gamma_pdf = gamma_dis.pdf(x, alpha, scale=theta) # 伽马分布概率密度函数log_norm_pdf = lognorm.pdf(x, loc=0, s=1) # 对数正态分布概率密度函数norm_pdf = norm.pdf(x, loc=0, scale=1) # 正态分布概率密度函数plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文# 绘制伽马分布曲线plt.plot(x, gamma_pdf)plt.plot(x, log_norm_pdf)plt.plot(x, norm_pdf)plt.legend(['伽马分布', '对数正态分布', '正态分布']) # 设置图例plt.title('概率密度函数曲线')plt.xlabel('x')plt.ylabel('概率密度函数值')plt.show()
运行结果如下:
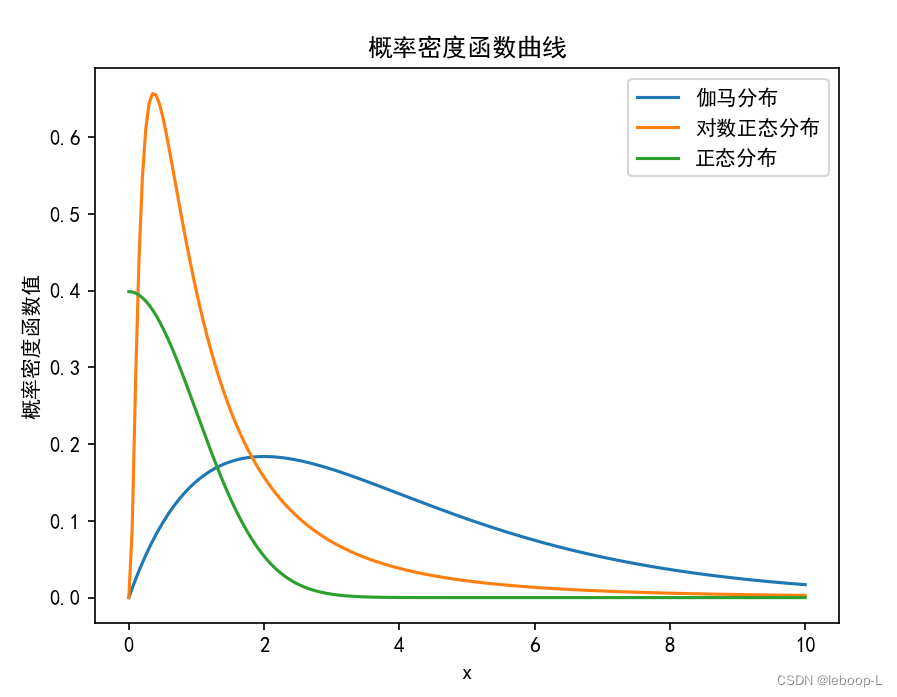
伽马分布有如下重要的性质:
(1)设随机变量,
,且
相互独立,则
。
证明:
假设随机变量的分布为
,概率密度函数为
,随机变量
的概率密度函数分别为
,
。两者的联合概率密度函数为
,因为
相互独立,显然有:
因为
取值都在
,所以
的取值也在
,从而当
时,
。
当时,
,这里将z看成常数,有
使用换元,将x看陈常数,有
,则
,且
,
得到
两边对z求导,得到
。
这就是卷积公式。因为
,
,代入得到
使用换元,当
时,
,并且
,则
根据,得到
,所以
卡方分布
假设n个相互独立的随机变量,均服从标准正态分布(也称独立同分布于标准正态分布)
。则这n个服从标准正态分布的随机变量的平方和
构成一个新的随机变量,其分布规律称为卡方分布(chi-square distribution),记作
,n称为卡方分布的自由度(degree of freedom),记作
。
这个分布由麦克斯韦(James Clerk Maxwell, 1831-1879)在研究空气分子的运动速度的分布时发现的,他发现分子运动速度的平方服从自由度为3的卡方分布,即
。后来又有多人提出这种分布,例如弗里德里希·罗伯特·海尔默特(Friedrich Robert Helmert, 1843-1917)于1875年,故卡方分布有时(在德国常见,因海尔默特是德国人)也称海尔默特分布;另外,这一结果被英国生物统计学家、优生学家、数理统计学创始人和社会达尔文主义理论家卡尔·皮尔逊(Karl Pearson, 1857-1936)推广并于1900年发表。
卡方分布的概率密度函数
下面来推导。
(1)当df=1时,。卡方分布的概率密度函数变为:
假设随机变量的分布函数为
,概率密度函数为
,随机变量
的分布函数为
,概率密度函数为
,随机变量
的分布函数为
,概率密度函数为
。因为
,
服从标准正态分布,有
。
因为
两边对x求导,
因为,所以:
即
事实上,它是的伽马分布,即
。根据如下伽马分布的概率密度函数,很容易得出。
(2)当df=n时,,由上面的结论知道,
。另外因为
相互独立,所以
也相互独立。根据之前证明的如下结论:
如果随机变量,
,且
相互独立,则
。
得到服从
,代入伽马分布,得到如下卡方分布
从结论来看,卡方分布是伽马分布的一个特例,即。也就是说
。
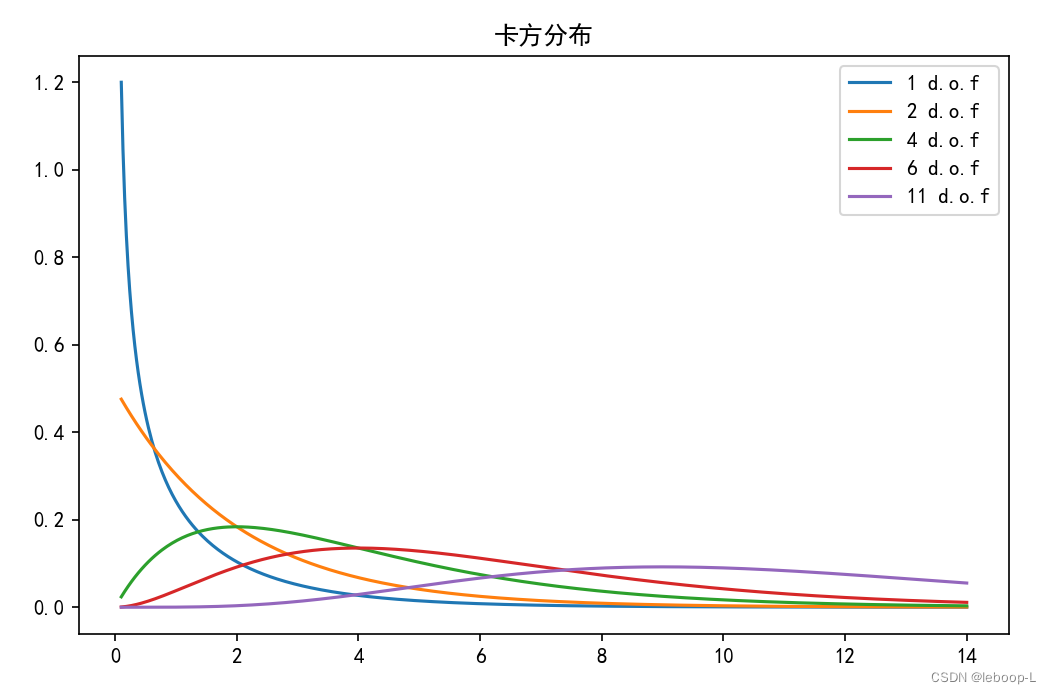
为了直观的观测卡方分布,下面使用python代码绘制卡方分布曲线。代码如下:
import numpy as np
from scipy.special import beta
import matplotlib.pyplot as plt
from scipy import statsif __name__ == '__main__':# # 创建一个网格# x, y = np.meshgrid(np.linspace(0.1, 1, 100), np.linspace(0.1, 1, 100))# print('x=', '\n', x)# print('y=', '\n', y)# z = beta(x, y)# print('z=', '\n', z)#plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文# fig = plt.figure(figsize=(10, 8))# ax = fig.add_subplot(111, projection='3d')# ax.tick_params(axis="both", labelsize=12)# ax.plot_surface(x, y, z, cmap='viridis')# ax.set_xlabel('x', fontsize=13)# ax.set_ylabel('y', fontsize=13)# ax.set_zlabel('z')# ax.set_title('贝塔函数图像')# plt.show()X = np.linspace(0.1, 14, 500)plt.subplots(figsize=(8, 5))plt.plot(X, stats.chi2.pdf(X, df=1), label="1 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=2), label="2 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=4), label="4 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=6), label="6 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=11), label="11 d.o.f")plt.title("卡方分布")plt.legend()plt.show()
代码中绘制了自由度为1,2,3,4,11的5个卡方分布,运行结果如下:
F分布
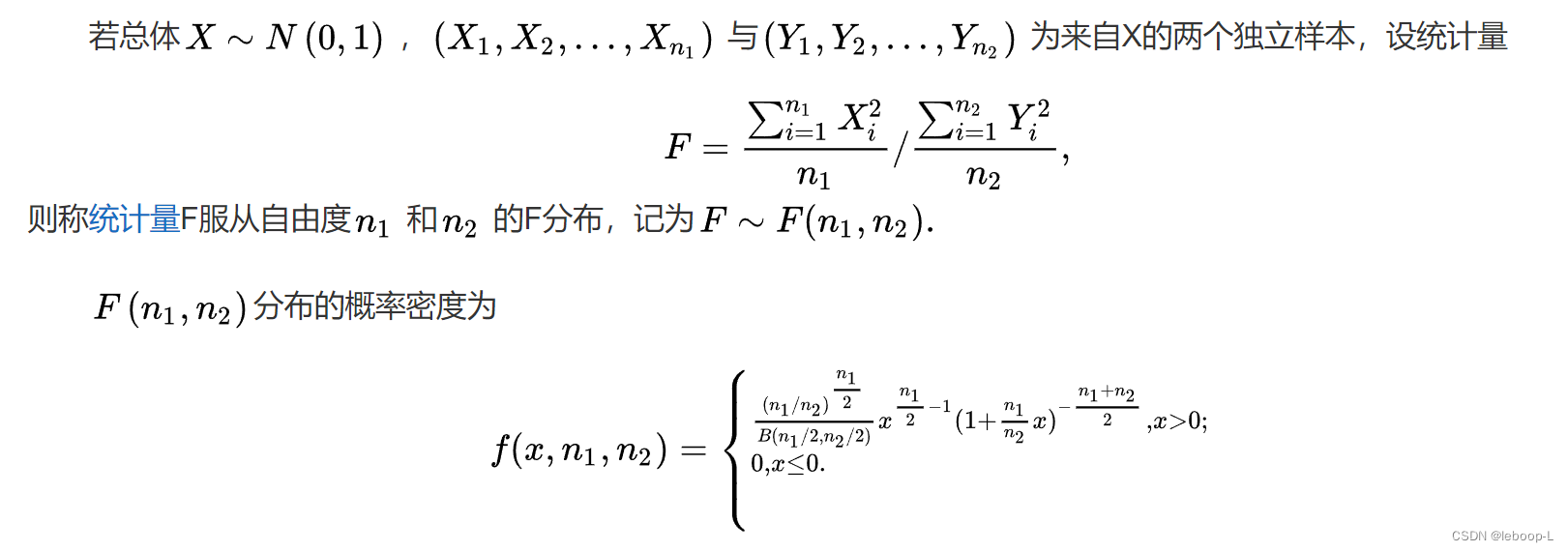
由卡方分布的定义知道,F分布定义可以转换为:如果 ,
,则
为F分布。概率密度函数的证明参见参考文献。
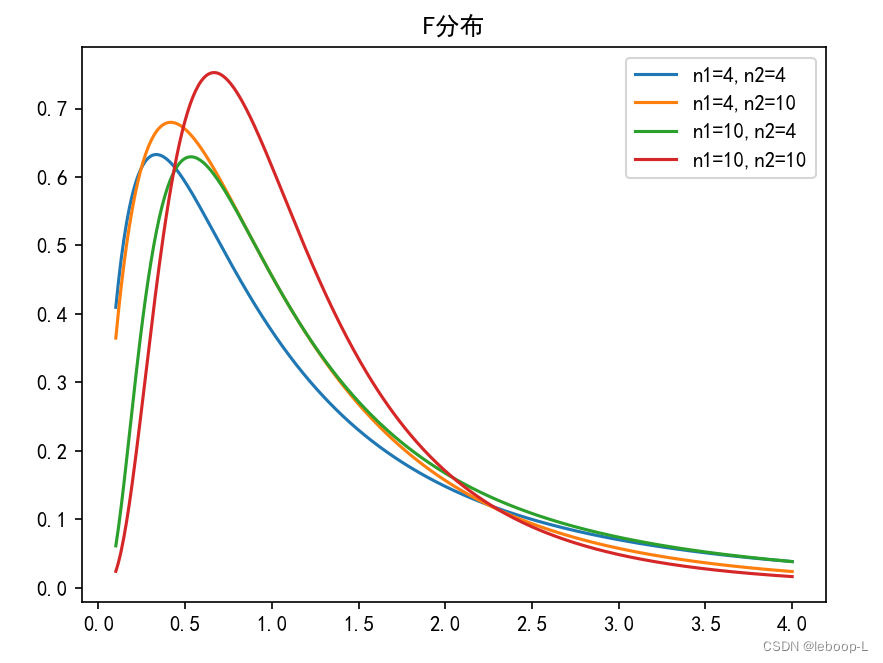
代码如下:
X = np.linspace(0.1, 4, 500)plt.plot(X, stats.f.pdf(X, 4,4), label="n1=4,n2=4")plt.plot(X, stats.f.pdf(X, 4,10), label="n1=4,n2=10")plt.plot(X, stats.f.pdf(X, 10,4), label="n1=10,n2=4")plt.plot(X, stats.f.pdf(X, 10,10), label="n1=10,n2=10")plt.title("F分布")plt.legend()plt.show()运行结果如下:
t分布
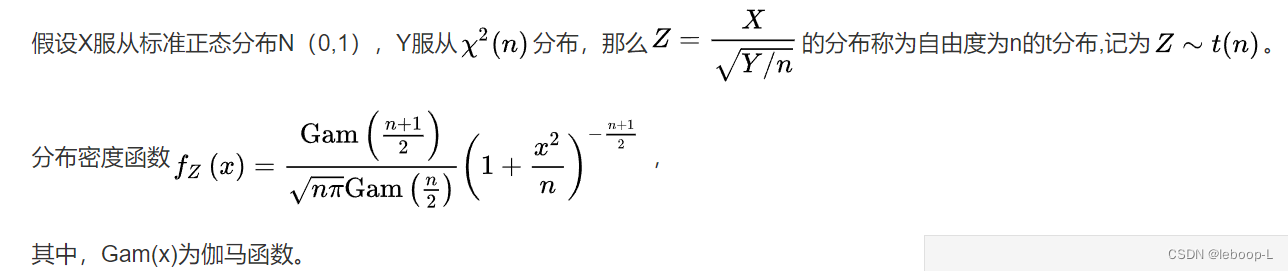
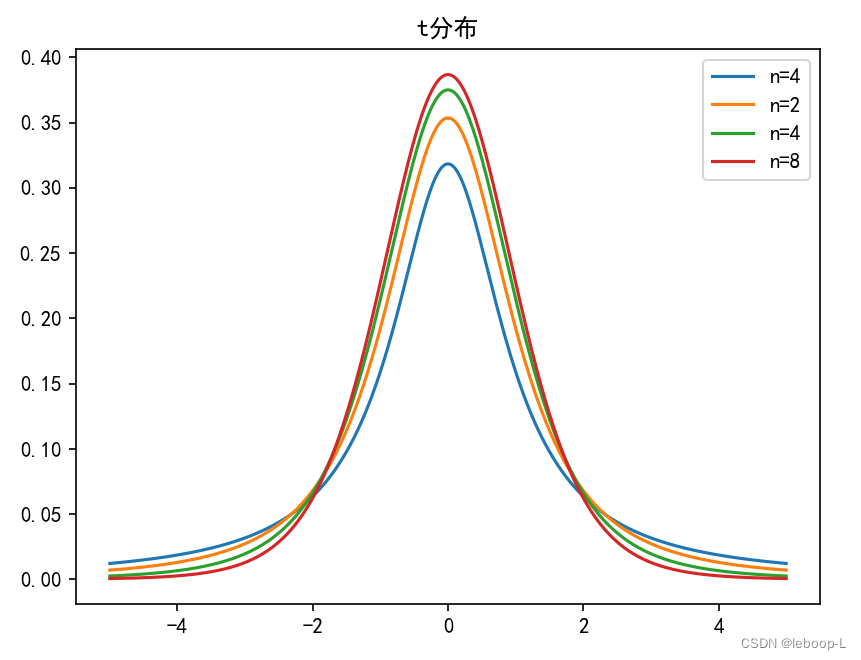
代码如下:
plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号X = np.linspace(-5, 5, 1500)plt.plot(X, stats.t.pdf(X, 1), label="n=4")plt.plot(X, stats.t.pdf(X, 2), label="n=2")plt.plot(X, stats.t.pdf(X, 4), label="n=4")plt.plot(X, stats.t.pdf(X, 8), label="n=8")plt.title("t分布")plt.legend()plt.show()运行结果如下:
附录
本节所有代码如下:
import numpy as np
from scipy.special import beta
import matplotlib.pyplot as plt
from scipy import statsif __name__ == '__main__':# 创建一个网格x, y = np.meshgrid(np.linspace(0.1, 1, 100), np.linspace(0.1, 1, 100))print('x=', '\n', x)print('y=', '\n', y)z = beta(x, y)print('z=', '\n', z)plt.rcParams['font.sans-serif'] = ['Simhei'] # 显示中文fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')ax.tick_params(axis="both", labelsize=12)ax.plot_surface(x, y, z, cmap='viridis')ax.set_xlabel('x', fontsize=13)ax.set_ylabel('y', fontsize=13)ax.set_zlabel('z')ax.set_title('贝塔函数图像')plt.show()X = np.linspace(0.1, 14, 500)plt.subplots(figsize=(8, 5))plt.plot(X, stats.chi2.pdf(X, df=1), label="1 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=2), label="2 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=4), label="4 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=6), label="6 d.o.f")plt.plot(X, stats.chi2.pdf(X, df=11), label="11 d.o.f")plt.title("卡方分布")plt.legend()plt.show()X = np.linspace(0.1, 4, 500)plt.plot(X, stats.f.pdf(X, 4,4), label="n1=4,n2=4")plt.plot(X, stats.f.pdf(X, 4,10), label="n1=4,n2=10")plt.plot(X, stats.f.pdf(X, 10,4), label="n1=10,n2=4")plt.plot(X, stats.f.pdf(X, 10,10), label="n1=10,n2=10")plt.title("F分布")plt.legend()plt.show()plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号X = np.linspace(-5, 5, 1500)plt.plot(X, stats.t.pdf(X, 1), label="n=4")plt.plot(X, stats.t.pdf(X, 2), label="n=2")plt.plot(X, stats.t.pdf(X, 4), label="n=4")plt.plot(X, stats.t.pdf(X, 8), label="n=8")plt.title("t分布")plt.legend()plt.show()
参考文献
高数篇(一)-- Gamma 函数 VS Beta 函数
极坐标与直角坐标二重积分转换
F分布概率密度函数的推导
python绘制正态分布及三大抽样分布的概率密度图像
这篇关于一些常见分布-正态分布、对数正态分布、伽马分布、卡方分布、t分布、F分布等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


