本文主要是介绍Java 工具类:SqlFileCompareUtils(比较数据库表和字段变化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【产生背景】
我们在实际开发的过程中,通常会有开发环境、测试环境、生产环境等。
在这些环境中,一般会有各自对应的数据库,由于每次新需求都是在测试环境中进行的测试,所以就会导致不同环境的数据库结构有不同。
当新一版本的功能在测试环境测好后,需要将新功能更新至生产环境,此时,生产环境数据库结构就需要再一次和测试环境数据库结构保持一致,才能保证新功能正常使用。
【数据库比较】
当我们想知道两个数据库的有哪些变化时候,如果每张表,每个字段的去比较,当在变化很大的时候,这将会是一个很不友好的体验,不但耗时耗力,而且容易出错。于是写了一个数据库字段比较的工具类 SqlFileCompareUtils(源代码见末尾)。
【使用方法】
(1)先将每个环境的数据库的 sql 文件(仅结构即可)导出;
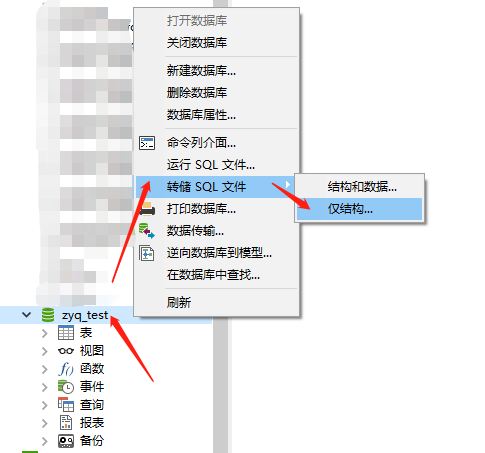
(2)然后将导出的每个 sql 文件放到任何工程的根目录下。

(3)然后打开工具类 SqlFileCompareUtils(源代码见末尾),将工具类中的两个常量,分别修改为对应环境的 sql 文件名称。

(4)执行类中的 main 方面,控制台就会打印数据库结构变化了,输出如下(样本),这样就可以根据下面的提示,很清晰的到生产环境中去添加对应的表和字段了。
共变化 17处,具体如下:
【1】z_dept 表新增字段:fillStatus : smallint(2)
【2】z_dept 表新增字段:syncStatus : smallint(6)
【3】z_dept_month_labor 表新增字段:transProject : char(1)
【4】z_dept_month_labor 表新增字段:transDept : char(1)
【5】z_project 表字段变化:piCode : varchar(255) -> varchar(50)
【6】z_project 表字段变化:code : varchar(255) -> varchar(50)
【7】z_project 表字段变化:operateSn : varchar(255) -> varchar(50)
【8】z_project 表字段变化:finName : varchar(255) -> varchar(50)
【9】z_project 表字段变化:finCode : varchar(255) -> varchar(50)
【10】z_project 表字段变化:name : varchar(255) -> varchar(50)
【11】z_project 表字段变化:operateName : varchar(255) -> varchar(50)
【12】z_project 表字段变化:syncStatus : varchar(255) -> varchar(5)
【13】z_project 表新增字段:isTransfer : char(1)
【14】新增表:z_project_log
【15】新增表:z_sow_log
【16】新增表:z_dept_user
【17】新增表:z_sow
【工具源码】
package com.zyq.test;import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;/*** 比较两个SQL文件,是否存在表变化和字段变化* * @author zyq* @since 2021/11/04*/
public class SqlFileCompareUtils {// 源 sql 文件(测试环境)public static String sqlFileNameFrom = "zyq_test.sql";// 目标 sql 文件(正式环境)public static String sqlFileNameTo = "zyq_live.sql";public static void main(String[] args) {printDifference();}public static void printDifference() {String msg = checkFile();if (msg != null) {System.err.println(msg);return;}// 获取源 sql 文件的表字段信息Map<String, Map<String, String>> fromMap = getTableMap(sqlFileNameFrom);// 获取目标 sql 文件的表字段信息Map<String, Map<String, String>> toMap = getTableMap(sqlFileNameTo);// 比较两个 sql 文件的字段信息List<String> differenceList = getDifferenceList(fromMap, toMap);if (differenceList.isEmpty()) {System.out.println("表和字段无变化");return;}int size = differenceList.size();System.out.println("共变化 " + size + "处,具体如下:");for (int i = 0; i < size; i++) {System.out.println(String.format("【%s】%s", (i + 1), differenceList.get(i)));}}private static List<String> getDifferenceList(Map<String, Map<String, String>> fromMap,Map<String, Map<String, String>> toMap) {List<String> list = new ArrayList<String>();Set<String> toTableSet = toMap.keySet();for (String tableName : toTableSet) {Map<String, String> fromFieldMap = fromMap.get(tableName);// 如果目标文件有该表,源文件没有该表,则表已被删除,冗余if (fromFieldMap == null) {list.add("多余表:" + tableName);}// 继续比较表的字段Map<String, String> toFieldMap = toMap.get(tableName);List<String> fieldList = getDifferenceFieldList(tableName, fromFieldMap, toFieldMap);if (!fieldList.isEmpty()) {list.addAll(fieldList);}}// 新增表Set<String> fromTableSet = fromMap.keySet();fromTableSet.removeAll(toTableSet);for (String tableName : fromTableSet) {list.add("新增表:" + tableName);}return list;}private static List<String> getDifferenceFieldList(String tableName, Map<String, String> fromMap,Map<String, String> toMap) {List<String> list = new ArrayList<String>();Set<String> toFiledSet = toMap.keySet();for (String filedName : toFiledSet) {String fromFileType = fromMap.get(filedName);// 如果目标文件表有该字段,源文件表没有该字段,则该字段已被删除,冗余if (fromFileType == null) {list.add("%s 表多余字段:" + fromFileType);continue;}// 继续比较字段类型String toFileType = toMap.get(filedName);if (!fromFileType.equals(toFileType)) {list.add(String.format("%s 表字段变化:%s : %s -> %s", tableName, filedName, toFileType, fromFileType));}}// 新增字段Set<String> fromFiledSet = fromMap.keySet();fromFiledSet.removeAll(toFiledSet);for (String fromFiledName : fromFiledSet) {list.add(String.format("%s 表新增字段:%s : %s", tableName, fromFiledName, fromMap.get(fromFiledName)));}return list;}private static Map<String, Map<String, String>> getTableMap(String fileName) {String sqlFrom = getFileContent(fileName);Map<String, Map<String, String>> map = new HashMap<String, Map<String, String>>();// 读取 sql 文件的所有行String[] lines = sqlFrom.split("\r\n");String tableName = null;for (String line : lines) {String trimLine = line.trim();// 以【CREATE TABLE】为开头的,则为表名if (trimLine.startsWith("CREATE TABLE")) {// 然后去掉 CREATE TABLE、`、( 即可获取表名tableName = trimLine.replaceAll("CREATE TABLE|`|\\(", "").trim();map.put(tableName, new HashMap<String, String>());continue;}// 以 ` 开头的,则为字段if (trimLine.startsWith("`")) {// 第 1 个 ` 和第 2 个 ` 之间的则为字段名String fieldName = getSplintIndexValue(trimLine, "`", 1);// 按 [空格] 拆分的第2个为字段类型String fieldType = getSplintIndexValue(trimLine, " ", 2);map.get(tableName).put(fieldName, fieldType);}}return map;}private static String getSplintIndexValue(String s, String regex, int index) {String[] strs = s.split(regex);int idx = 0;for (String str : strs) {if (!str.isEmpty()) {idx++;}if (idx == index) {return str;}}return "";}private static boolean isEmpty(String s) {return s == null || s.isEmpty();}private static String checkFile() {if (isEmpty(sqlFileNameFrom)) {return "源文件名称不能为空";}if (!sqlFileNameFrom.endsWith(".sql")) {return "源文件不是sql文件";}File from = new File(sqlFileNameFrom);if (!from.exists()) {return "源文件不存在于工程根目录下";}if (isEmpty(sqlFileNameTo)) {return "目标文件名称不能为空";}if (!sqlFileNameTo.endsWith(".sql")) {return "目标文件不是sql文件";}File to = new File(sqlFileNameTo);if (!to.exists()) {return "目标文件不存在于工程根目录下";}return null;}private static String getFileContent(String fileName) {File file = new File(fileName);try (FileInputStream fis = new FileInputStream(file)) {byte[] b = new byte[(int) file.length()];fis.read(b);return new String(b, "UTF-8");} catch (IOException e) {e.printStackTrace();}return "";}}
这篇关于Java 工具类:SqlFileCompareUtils(比较数据库表和字段变化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






