本文主要是介绍Elasticsearch实战(十八)--ES搜索Doc Values/Fielddata 正排索引 深入解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.正排索引与倒排索引
先说结论,再讲原理
!!!尽量不要再生产环境使用fielddata=true,即使要用也要控制好占用内存比例的大小,否则容易出现OOM
!!!尽量不要再生产环境使用fielddata=true,即使要用也要控制好占用内存比例的大小,否则容易出现OOM
!!!尽量不要再生产环境使用fielddata=true,即使要用也要控制好占用内存比例的大小,否则容易出现OOM
讲讲 原理,现在又3个文档如下
doc1:i am jzj
doc2:you are right
doc3:i am lucy
正排索引->就是人们正常的思维, 一个文档包含哪些单词
doc1: i, am, jzj 3个单词
doc2: you, are, right 3个单词
doc3: i,am,lucy 3个单词
倒排索引-> 反向思维,将分词,映射到每一个doc,每个单词在哪些文档中出现
i单词:doc1,doc3
am单词:doc1,doc3
jzj单词:doc1
you单词:doc2
are单词:doc2
right单词:doc2
lucy单词:doc3
正排优势
查询文档中包括哪些term单词,天然的支持比如搜索doc1有哪些term,直接取1条数据就可以得出结果,再比如聚合排序操作 doc4中有个 age:18, order by age,直接就可以取到值,进行排序,劣势是搜索慢,比如我要找 am单词出现在哪些文档,就要便利每一个doc1,doc2,doc3,去查该文档是否包含am单词
倒排优势
查询am单词出现在哪些文档中?对于倒排索引天然的支持,因为他就是按这样子存储的,am单词:doc1,doc2,直接可以定位到doc1,doc3 两个文档,劣势是对于聚合操作及排序操作不友好
所以ES中即存在倒排索引,有存在正排索引
搜索需要用到倒排索引
排序和聚合则需要使用 “正排索引”。
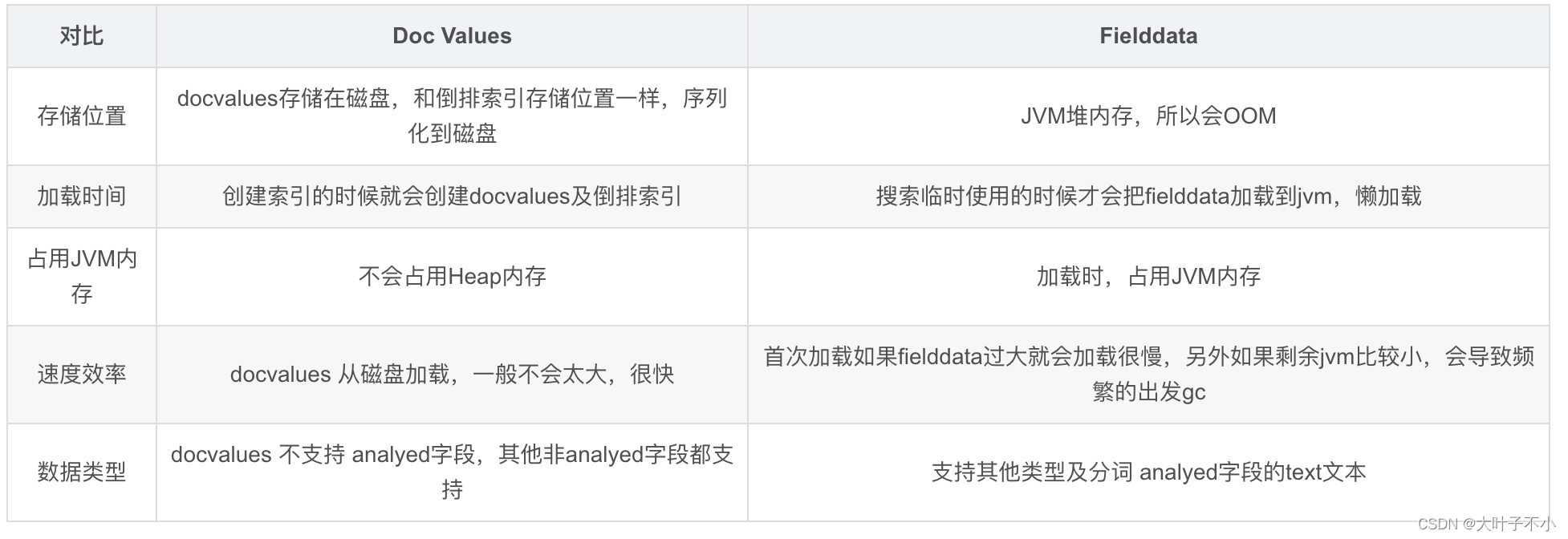
Doc Values和Fielddata就是用来给文档建立正排索引的, DocValues工作地盘主要在磁盘,是建立索引的时候进行的初始化,而Fielddata的工作地盘在内存,需要开启 fielddata=true ,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆,使用text字段进行聚合排序的时候才加载到内存。
2.准备数据
先构造 index:testquery, 然后构造mapping结构, 插入测试数据
#构建 库index testquer
put /testquery
#构建mapping结构
put /testquery/_mapping
{
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"age" : {
"type" : "long"
},
"area" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"deptName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"empId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"info" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"mobile" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"provice" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"salary" : {
"type" : "long"
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"addtime" : {
"type":"date",
//时间格式 epoch_millis表示毫秒
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
插入测试数据
put /testquery/_bulk
{"index":{"_id": 1},"addtime":"1658041203000"}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article", "addtime":"1658140003000"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3},"addtime":"1658040045600"}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4},"addtime":"1658040012000"}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5},"addtime":"1658040593000"}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6},"addtime":"1658043403000"}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer","addtime":"1658041003000"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer","addtime":"1658040008000"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language","addtime":"1656040003000"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer","addtime":"1608040003000"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch","addtime":"1654040003000"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java ","addtime":"1658740003000"}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good","addtime":"165704003000"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java ","addtime":"1658140003000"}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++","addtime":"1656040003000"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good","addtime":"1658040003000"}
3. ES field data 使用及配置
3.1 field data防止内存溢出OOM配置及熔断控制
fielddata应该在JVM中合理利用,否则会影响es性能,正确使用fielddata要配置以下参数
indices.fielddata.cache.size限制fielddata内存使用,可以是具体大小(如2G),也可以是占用内存的百分比(如20%)
运行命令进行监控 GET /_stats/fielddata ,查看当前 fielddata占用内存大小
防止一次性加载字段直接超过内存值,就要使用熔断控制断路器, ES内部检查来估算一个查询需要的内存。它然后检查要求加载的 fielddata 是否会导致 fielddata 的总量超过堆的配置比例。如果估算查询大小超出限制,就会触发熔断,查询会被中止并返回异常 ,控制参数 indices.breaker.fielddata.limit/ indices.breaker.request.limit /indices.breaker.total.limit
#控制 fielddata可以使用多少jvm内存,一般不超过20%
indices.fielddata.cache.size
#查看
get /_stats/fielddata
get /_stats/fielddata?fields=*
如果一次性加载字段直接超过内存值,就会触发熔断,查询会被中止并返回异常
indices.breaker.fielddata.limit fielddata级别限制,默认为堆的60%
indices.breaker.request.limit request级别请求限制,默认为堆的40%
indices.breaker.total.limit 保证上面两者组合起来的限制,默认堆的70%
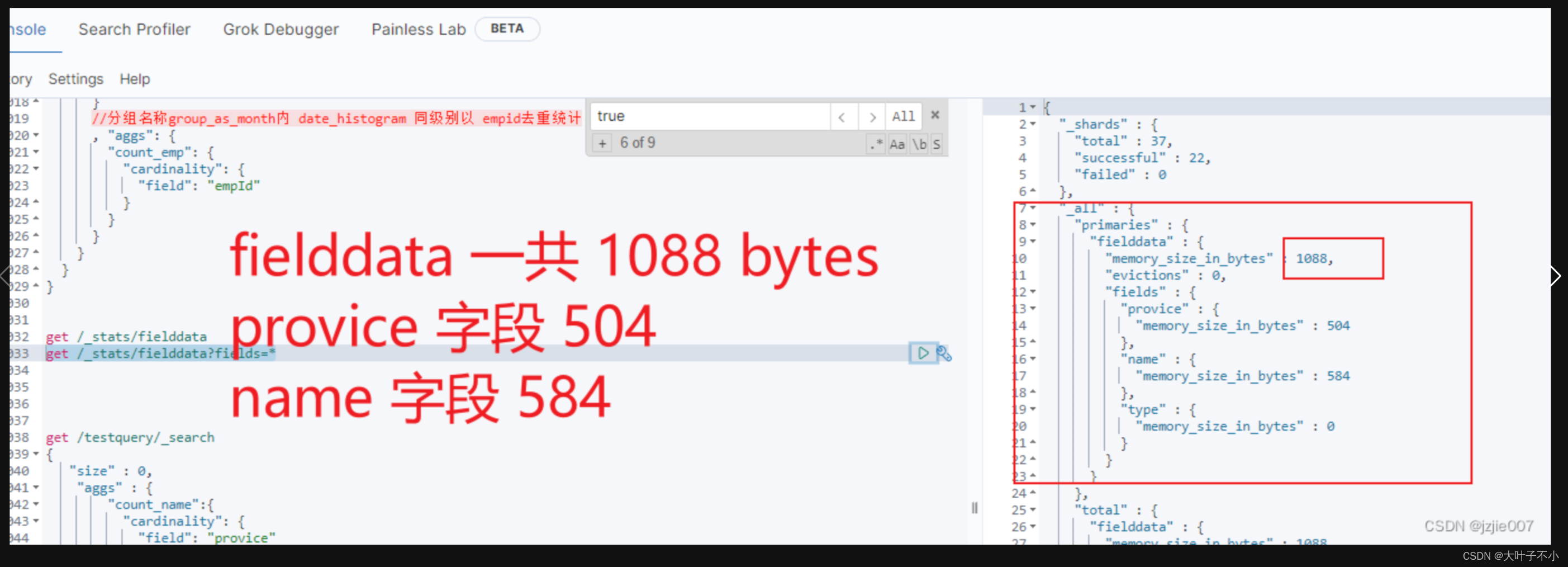
查询fielddata占用多少 memory信息 get /_stats/fielddata?fields=* ,可以看到 fielddata一共占了 1088bytes, 字段 provice fielddata 占了 504 bytes, 字段 name fielddata 占了 584 bytes
3.2 对text类型字段进行聚合
对text人名进行 聚合count操作, 出错
“reason” : “Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [name] in order to load field data by uninverting the inverted index. Note that this can use significant memory.”
get /testquery/_search
{
"size" : 0,
"aggs" : {
"count_name":{
"cardinality": {
"field": "name"
}
}
}
}
}
出错,因为name名字字段是text类型,但是没有设置 fielddata=true,所以不允许进行 聚合排序操作
3.3 修改 fielddata=true设置
修改聚合字段 name 的 设置 fielddata=true
PUT testquery/_mapping
{
"properties": {
"name": {
"type": "text",
"fielddata": true
}
}
}
再次执行上面的 aggs 语句
PUT testquery/_mapping
{
"properties": {
"name": {
"type": "text",
"fielddata": true
}
}
}
查询成功
至此 我们已经学习了 ES 正排索引,倒排索引的应用场景及优势/劣势, 再正确的场合使用正确的索引,才能提高查询效率, 还学些了 fielddata的 内存jvm控制参数,熔断策略等来 避免线上出现事故
————————————————
版权声明:本文为CSDN博主「jzjie」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010134642/article/details/125834384
这篇关于Elasticsearch实战(十八)--ES搜索Doc Values/Fielddata 正排索引 深入解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




