本文主要是介绍达观杯--风险事件实验记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
达观杯–风险事件实验记录
官方代码
#!/usr/bin/env python
# coding: utf-8import pandas as pd
from sklearn.model_selection import train_test_splitimport sys
sys.path.append("./")# ### 加载数据集,并切分train/dev# In[2]:# 加载数据
df_train = pd.read_csv("./datasets/phase_1/splits/fold_0/train.txt")
df_train.columns = ["id", "text", "label"]
df_val = pd.read_csv("./datasets/phase_1/splits/fold_0/dev.txt")
df_val.columns = ["id", "text", "label"]
df_test = pd.read_csv("./datasets/phase_1/splits/fold_0/test.txt")
df_test.columns = ["id", "text", ]# 构建词表
charset = set()
for text in df_train['text']:for char in text.split(" "):charset.add(char)
id2char = ['OOV', ',', '。', '!', '?'] + list(charset)
char2id = {id2char[i]: i for i in range(len(id2char))}# 标签集
id2label = list(df_train['label'].unique())
label2id = {id2label[i]: i for i in range(len(id2label))}# ### 定义模型# In[3]:# 定义模型from tensorflow.keras.layers import *
from tensorflow.keras.models import *
MAX_LEN = 128
input_layer = Input(shape=(MAX_LEN,))
layer = Embedding(input_dim=len(id2char), output_dim=256)(input_layer)
layer = Bidirectional(LSTM(256, return_sequences=True))(layer)
layer = Flatten()(layer)
output_layer = Dense(len(id2label), activation='softmax')(layer)
model = Model(inputs=input_layer, outputs=output_layer)
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as npX_train, X_val, X_test = [], [], []
y_train = np.zeros((len(df_train), len(id2label)), dtype=np.int8)
y_val = np.zeros((len(df_val), len(id2label)), dtype=np.int8)for i in range(len(df_train)):X_train.append([char2id[char] for char in df_train.loc[i, 'text'].split(" ")])y_train[i][label2id[df_train.loc[i, 'label']]] = 1
for i in range(len(df_val)):X_val.append([char2id[char] if char in char2id else 0 for char in df_val.loc[i, 'text'].split(" ")])y_val[i][label2id[df_val.loc[i, 'label']]] = 1
for i in range(len(df_test)):X_test.append([char2id[char] if char in char2id else 0 for char in df_test.loc[i, 'text'].split(" ")])X_train = pad_sequences(X_train, maxlen=MAX_LEN, padding='post', truncating='post')
X_val = pad_sequences(X_val, maxlen=MAX_LEN, padding='post', truncating='post')
X_test = pad_sequences(X_test, maxlen=MAX_LEN, padding='post', truncating='post')# ### 模型训练# In[5]:model.fit(x=X_train, y=y_train, validation_data=(X_val, y_val), epochs=5, batch_size=32)# In[19]:y_val_pred = model.predict(X_val).argmax(axis=-1)
print(y_val_pred[: 20])
y_val = []
for i in range(len(df_val)):y_val.append(label2id[df_val.loc[i, 'label']])
y_val = [int(w) for w in y_val]
print(y_val[: 20])from sklearn.metrics import classification_report
results = {}
classification_report_dict = classification_report(y_val_pred, y_val, output_dict=True)
for key0, val0 in classification_report_dict.items():if isinstance(val0, dict):for key1, val1 in val0.items():results[key0 + "__" + key1] = val1else:results[key0] = val0import json
print(json.dumps(results, indent=2, ensure_ascii=False))y_pred = model.predict(X_test).argmax(axis=-1)
pred_labels = [id2label[i] for i in y_pred]
pd.DataFrame({"id": df_test['id'], "label": pred_labels}).to_csv("submission.csv", index=False)baseline f1-score
0.36730954652
StratifiedKFold 有放回交叉验证
20210901
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| 随机word2vec bilstm max-pool | 0.5019740105397982 | 0.5305047362015384 | 0.48712090715947126 | 0.48712090715947126 | 0.48810399175309066 | 0.501351448 |
| 随机word2vec textcnn max-pool | 0.439562055261517 | 0.4648484073382289 | 0.44261612551282675 | 0.4457093924403507 | 0.434124310352773 | 0.4453720582 |
| 随机word2vec bigru max-pool | 0.48342625023887464 | 0.5054070454155676 | 0.4933128922080378 | 0.5201217214903346 | 0.49556451728443063 | 0.499566485 |
submit 随机word2vec bilstm max-pool -> 0.56353646

20210902
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| word2vec 128dim bilstm max-pool | 0.4708744068465424 | 0.47845341273531994 | 0.4949468498144354 | 0.47445775060161777 | 0.4920726822823006 | 0.48216102 |
| word2vec 256dim bilstm max-pool | 0.5000242476735502 | 0.5074785775400152 | 0.48898313465365634 | 0.48141964408586274 | 0.5011912207362488 | 0.495819365 |
20210902
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| word2vec bilstm dr_pool | 0.49550919963206336 | 0.4959174229132799 | 0.4975635618147769 | 0.4901513796262005 | 0.5364222467099669 | 0.503112762 |
| word2vec bilstm slf_attn_pool | 0.538690929260001 | 0.5348826422709811 | 0.5344279139390143 | 0.5297157921167813 | 0.5087694907593167 | 0.529297354 |
| word2vec bilstm avg_pool | 0.5000242476735502 | 0.5074785775400152 | 0.48898313465365634 | 0.48141964408586274 | 0.5011912207362488 | 0.495819365 |
| word2vec bilstm max_pool | 0.5378373123329686 | 0.5430106048648518 | 0.5396615043234209 | 0.5374038674177514 | 0.5364222467099669 | 0.538867107 |
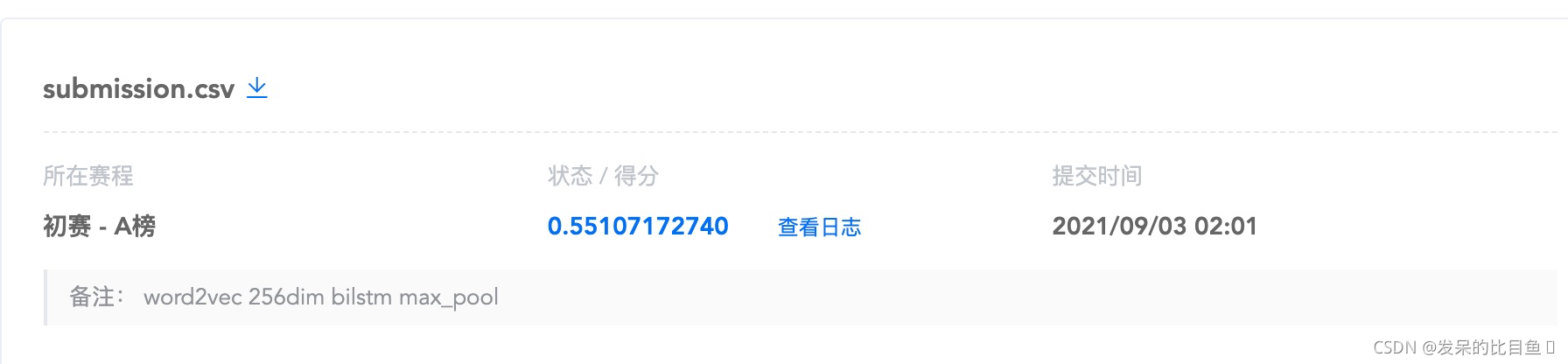
有点过拟合
20210907
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| bert-base-chinese+random | 0.5087 | 0.4765 | 0.4942 | 0.5102 | 0.4936 | 0.49664 |
| bert-base-chinese+w2v | 0.5152 | 0.4865 | 0.5079 | 0.5037 | 0.508 | 0.50426 |
| chinese-bert-wwm-ext+random | 0.5281 | 0.4854 | 0.512 | 0.5086 | 0.5159 | 0.51 |
| chinese-bert-wwm-ext+w2v | 0.51 | 0.4869 | 0.5064 | 0.505 | 0.5054 | 0.50274 |
| chinese-roberta-wwm-ext+random | 0.505 | 0.4799 | 0.5029 | 0.5073 | 0.4954 | 0.4981 |
| chinese-roberta-wwm-ext+w2v | 0.5057 | 0.4786 | 0.4993 | 0.4917 | 0.4903 | 0.49312 |
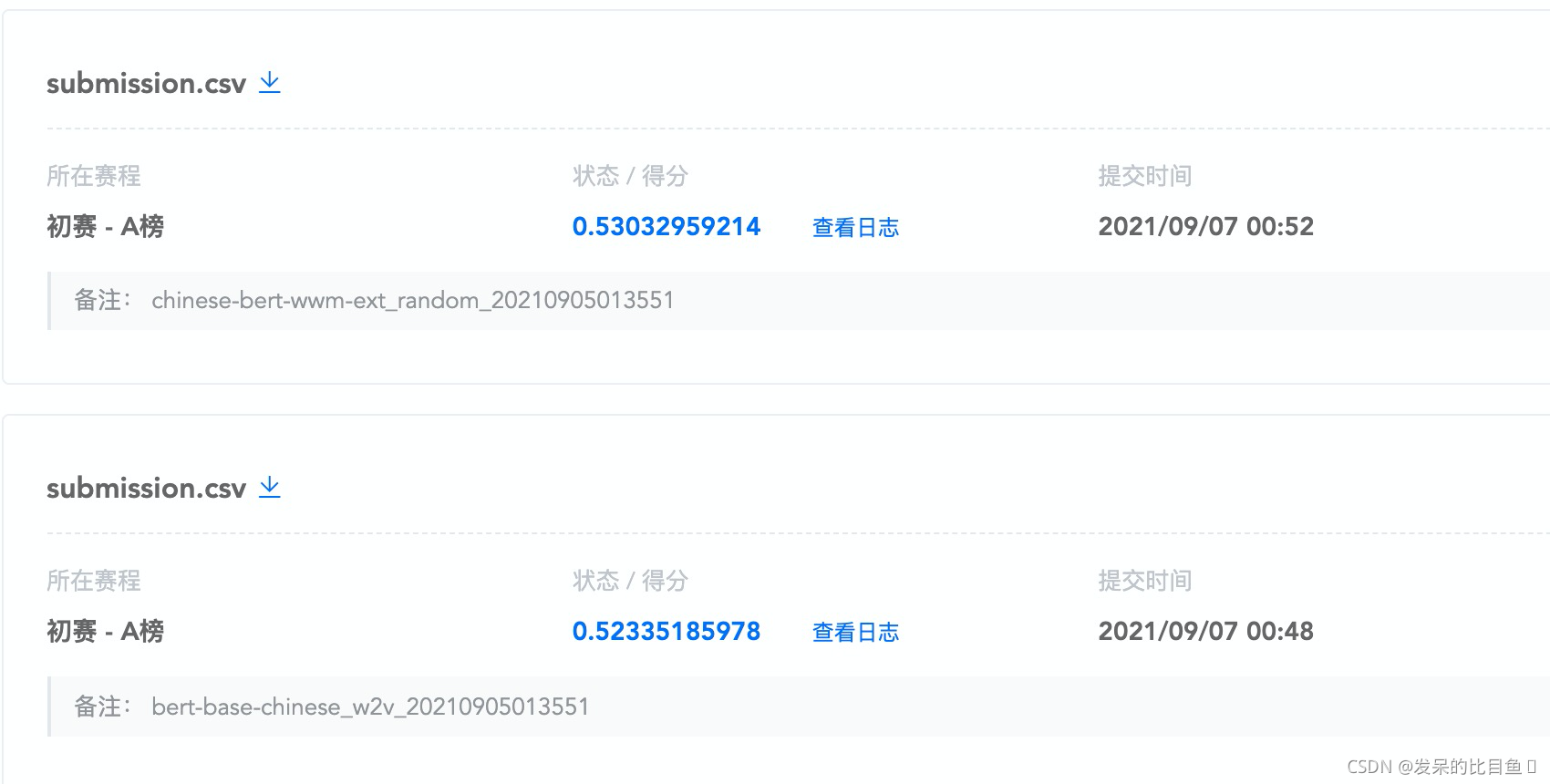
20210908
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| chinese-roberta-wwm-ext+counts | 0.5329 | 0.5101 | 0.5141 | 0.5412 | 0.5259 | 0.52484 |
| chinese-roberta-wwm-ext + dict_vocab2freq | 0.5246 | 0.5072 | 0.5091 | 0.5139 | 0.5103 | 0.51302 |
| chinese-roberta-wwm-ext + dict_vocab2freq_wiki_zh | 0.5155 | 0.5049 | 0.5075 | 0.5293 | 0.5091 | 0.51326 |
| chinese-bert-wwm-ext + counts | 0.5352 | 0.514 | xx | 0.5304 | 0.5028 | 0.5206 |
| chinese-bert-wwm-ext_dict + vocab2freq_0819 | 0.5254 | xx | xx | 0.5151 | 0.5186 | 0.5197 |
| chinese-bert-wwm-ext + dict_vocab2freq_wiki_zh | 0.5217 | 0.5105 | xx | 0.5274 | 0.5256 | 0.5213 |
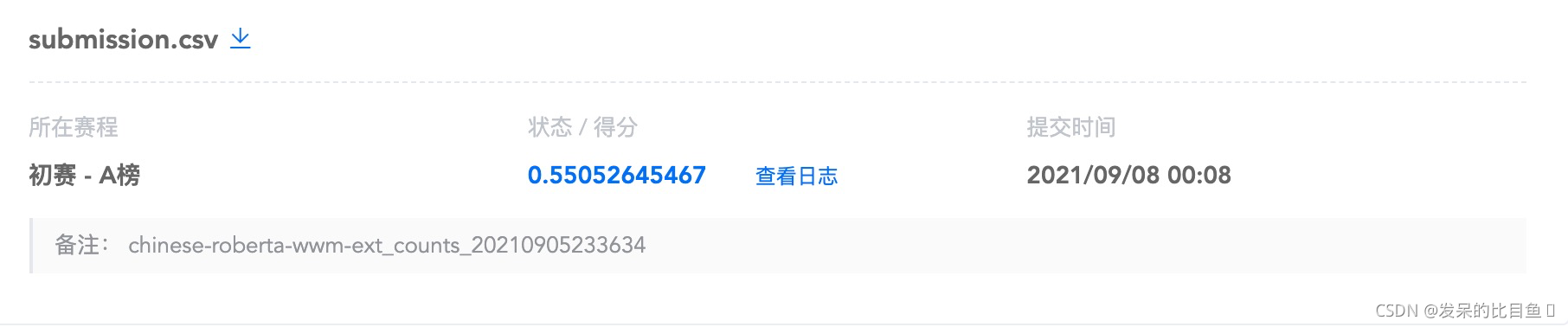
*20210910
NEZHA 脱敏+counts
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| NEZHA-Base + counts | 0.5191 | 0.5078 | 0.5178 | 0.5169 | 0.5469 | 0.5217 |
| NEZHA-Base-WWM + counts | 0.5494 | 0.5258 | 0.5091 | 0.5325 | 0.5253 | 0.52948 |

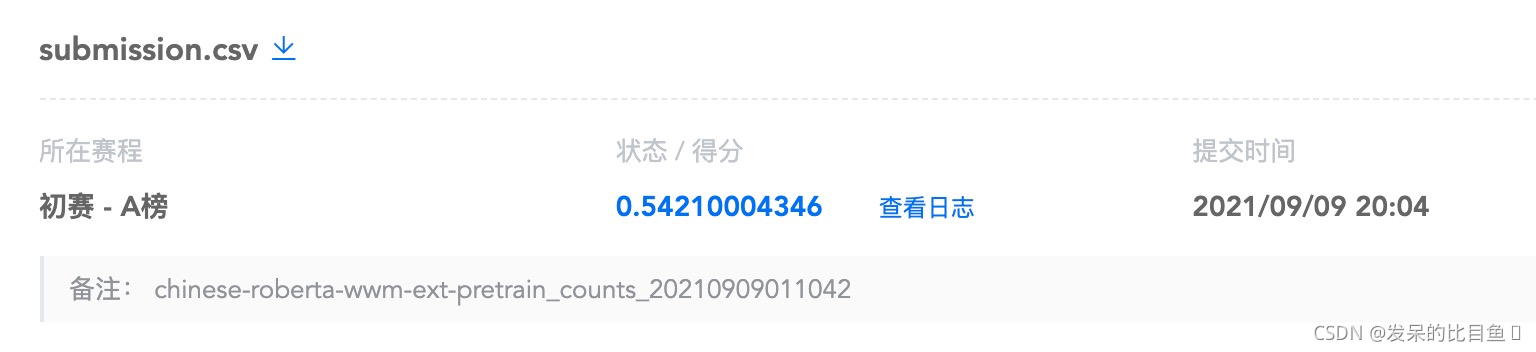
Roberta 脱敏 + 预训练 + counts
| dev macro-F1 | 0 | 1 | 2 | 3 | 4 | avg |
|---|---|---|---|---|---|---|
| chinese-roberta-wwm-ext + pretrain + counts | 0.5427 | 0.5203 | 0.5237 | 0.527 | 0.5286 | 0.52846 |

这篇关于达观杯--风险事件实验记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






