本文主要是介绍zookeeper日志中Error KeeperErrorCode NoNode 错误的排查过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求背景
zookeeper日志中出现不少以下类似错误:
2021-05-11 09:03:28,004 [myid:3] - INFO [ProcessThread(sid:3 cport:-1)::PrepRequestProcessor@648] - Got user-level KeeperException when processing sessionid:0x27918ca11740225 type:create cxid:0x1c3bbb zxid:0x20008db83 txntype:-1 reqpath:n/a Error Path:/dlock/dhy/330922966870720/GL/GL_Acc_Insert5601048 Error:KeeperErrorCode = NoNode for /dlock/dhy/330922966870720/GL/GL_Acc_Insert5601048
二、解决方案
由日志可以得出的信息:
1、dlock是我们项目中分布式锁使用的命名空间
2、dhy/330922966870720/GL/GL_Acc_Insert5601048是我们项目中一个模块中的分布式加锁点 [临时顺序节点]
3、其它加锁点有类似日志信息
分布式锁工具是经过测试并且在生产环境已经使用很长时间了,从功能上来说肯定是没有问题的,只是这条日志信息反馈了可能有实现不太优雅的地方,作为架构师要精益求精,解决方案不但要可行而且要优雅完美。
下面通过 源码分析org.apache.curator.framework获取分布式锁的过程来 寻找产生这条日志的根本原因。
三、代码实现
下面是我几年前写的一把分布式锁工具类(简化版)
/*** 基于zookeeper的分布式锁实现* @author lvaolin* @create 18/3/7 上午10:38*/
public class DlockUtil {private static final Logger logger = LoggerFactory.getLogger(DlockUtil.class);private static final String ZK_LOCK_PATH = "/dhy/";private static CuratorFramework client = null;static {RetryPolicy retryPolicy = new RetryOneTime(60000);client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181").connectionTimeoutMs(5000) .retryPolicy(retryPolicy).namespace("dlock").build();client.start();logger.info("zk client start successfully!");}/*** 获取分布式锁,如果获取失败会立刻返回,不会等待* 注意:调用方需要保留 此方法的 返回值,在finally里调用releaseDLock(lock) 进行锁释放** @param orgId 企业ID* @param moduleName 业务模块名称 英文* @param lockName 锁名称(具体业务操作命名) 英文* @return 返回值为null 代表 获取锁失败,非null代表 获取锁成功*/public static InterProcessMutex getDLock(String orgId, String moduleName, String lockName) {return getDLock(orgId, moduleName, lockName, 0);}/*** 获取分布式锁(可指定获取锁超时时间)* 注意:调用方需要保留 此方法的 返回值,在finally里调用releaseDLock(lock) 进行锁释放* InterProcessMutex.isAcquiredInThisProcess() 可以准确判断是否还持有锁** @param orgId 企业ID* @param moduleName 业务模块名称 英文* @param lockName 锁名称(具体业务操作命名) 英文* @param second 超时时间 :-1代表一直堵塞,直到获取成功;0代表不等待,如果获取失败,立刻返回;大于0 则表示会尝试排队获取锁,直到超时就返回* @return 返回值为null 代表 获取锁失败,非null代表 获取锁成功*/public static InterProcessMutex getDLock(String orgId, String moduleName, String lockName, long second) {if (client == null) {logger.error("client == null,未启用分布式锁DLOCK");return null;}InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH + orgId + "/" + moduleName + "/" + lockName);try {if (second == -1) {//-1代表一直堵塞下去直到获取成功logger.info("-1 正在获取分布式锁..." + Thread.currentThread().getName());lock.acquire();logger.info("获取分布式锁成功" + Thread.currentThread().getName());return lock;} else {//获取不到锁就返回获取锁失败logger.info(second + " 正在获取分布式锁..." + Thread.currentThread().getName());if (lock.acquire(second, TimeUnit.SECONDS)) {logger.info("获取分布式锁成功" + Thread.currentThread().getName());return lock;} else {return null;}}} catch (Exception e) {logger.error("获取分布式锁失败:" + e.getMessage(), e);return null;}}/*** 释放分布式锁* 注意:此方法需要在finally里进行调用** @param lock 要释放的锁,来自于getDLock()的返回值*/public static void releaseDLock(InterProcessMutex lock) {try {if (lock != null) {//判断是否还持有锁if (lock.isAcquiredInThisProcess()) {lock.release();//是否是最后一把锁if (!lock.isAcquiredInThisProcess()) {lock = null;}} else {lock = null;}logger.info("释放锁成功:" + Thread.currentThread().getName());} else {logger.info("无需释放" + Thread.currentThread().getName());}} catch (Exception e) {logger.error("释放分布式锁失败:" + e.getMessage(), e);}}
}关键代码:
//定义一把锁
InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH + orgId + "/" + moduleName + "/" + lockName);
//获取这把锁,返回值代表是否成功
boolean result = lock.acquire(second, TimeUnit.SECONDS)
下面深究 lock.acquire的源代码(由于代码较多,我只贴关键代码了)
关键方法:InterProcessMutex.internalLock(long time, TimeUnit unit)
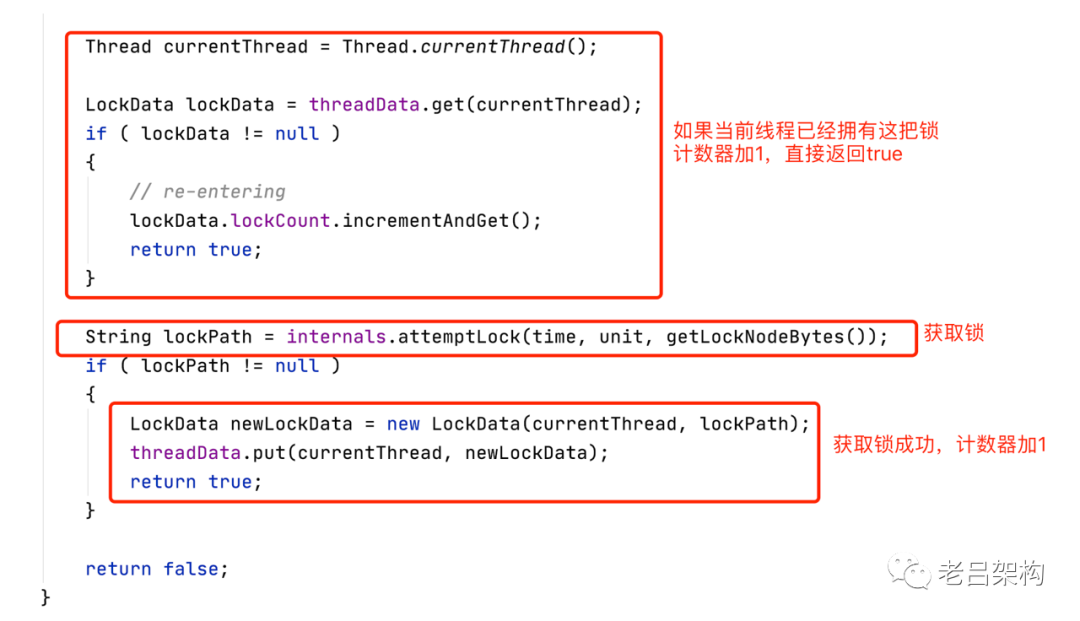
看下internals.attemptLock 方法
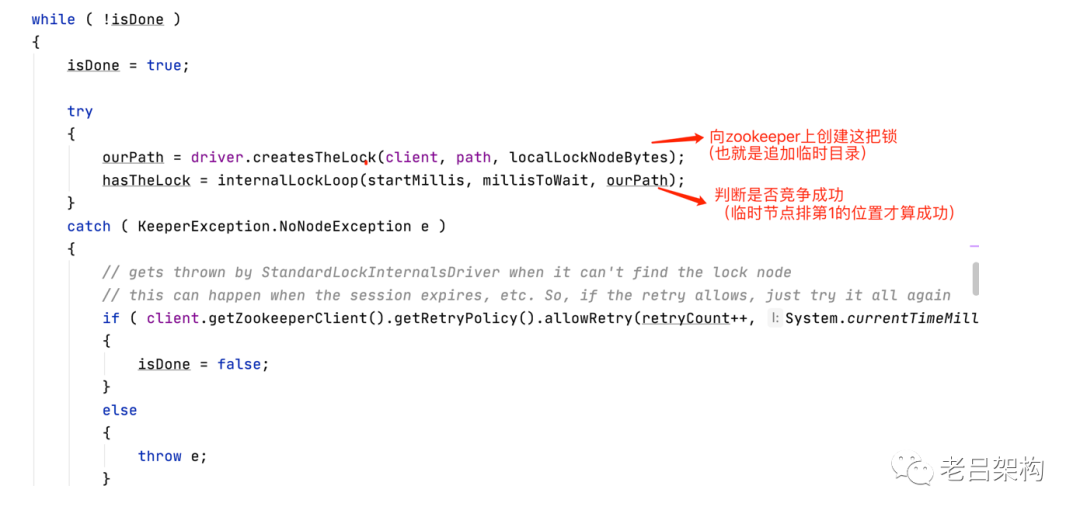
日志已经显示了是在创建节点时报的,所以看driver.createsTheLock就对了
关键代码,可以看到创建的是 "临时有序节点类型","自动创建父目录"
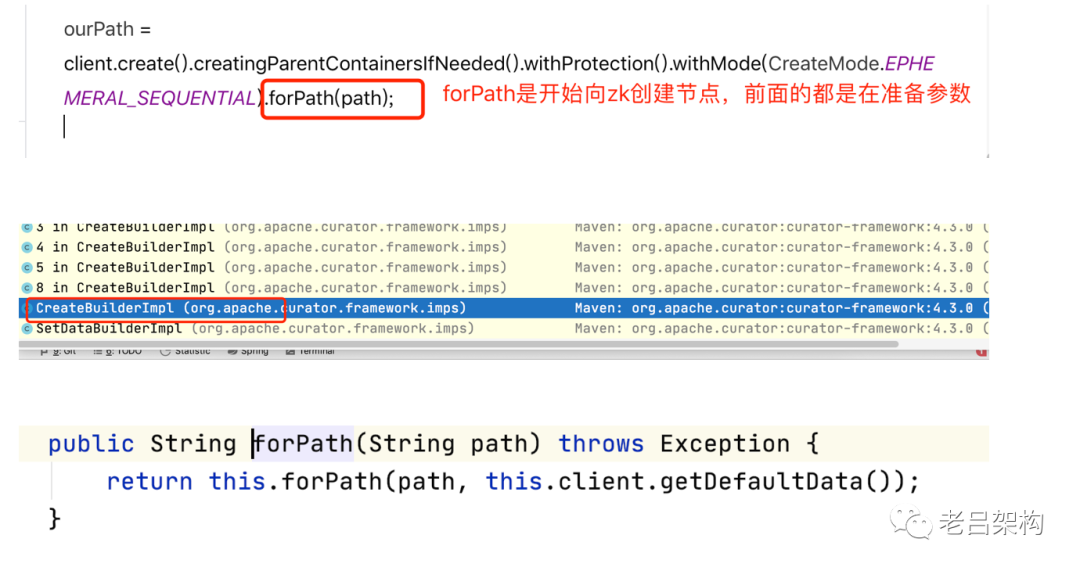
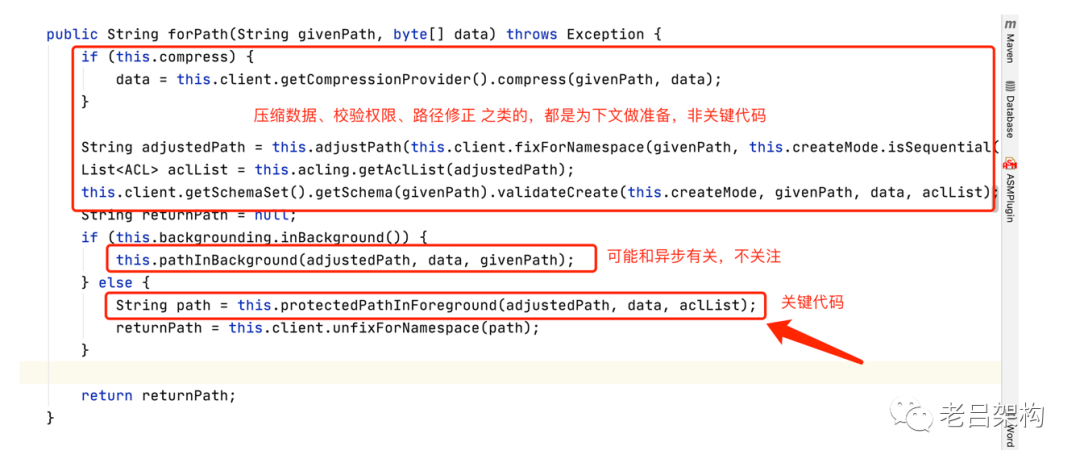
看下protectedPathInForeground方法
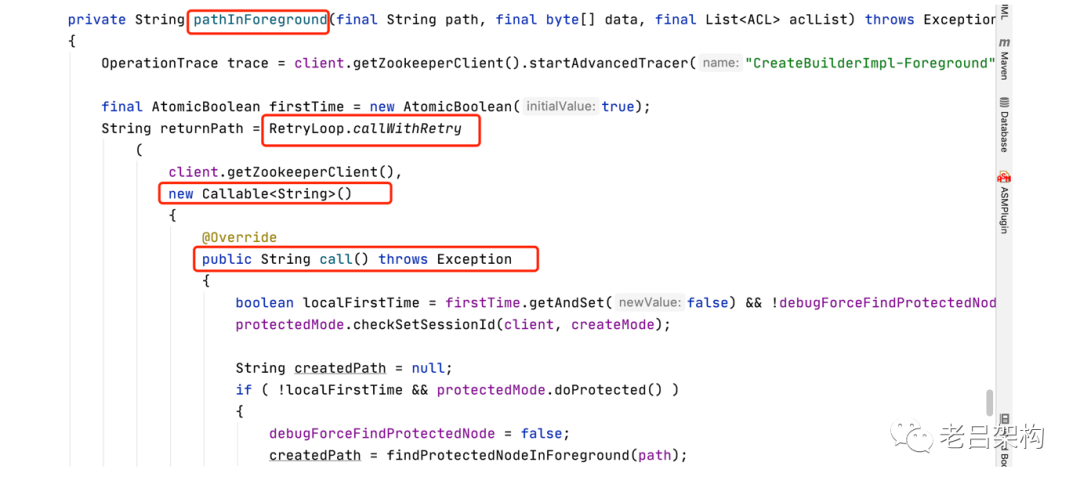
call方法关键内容如下:
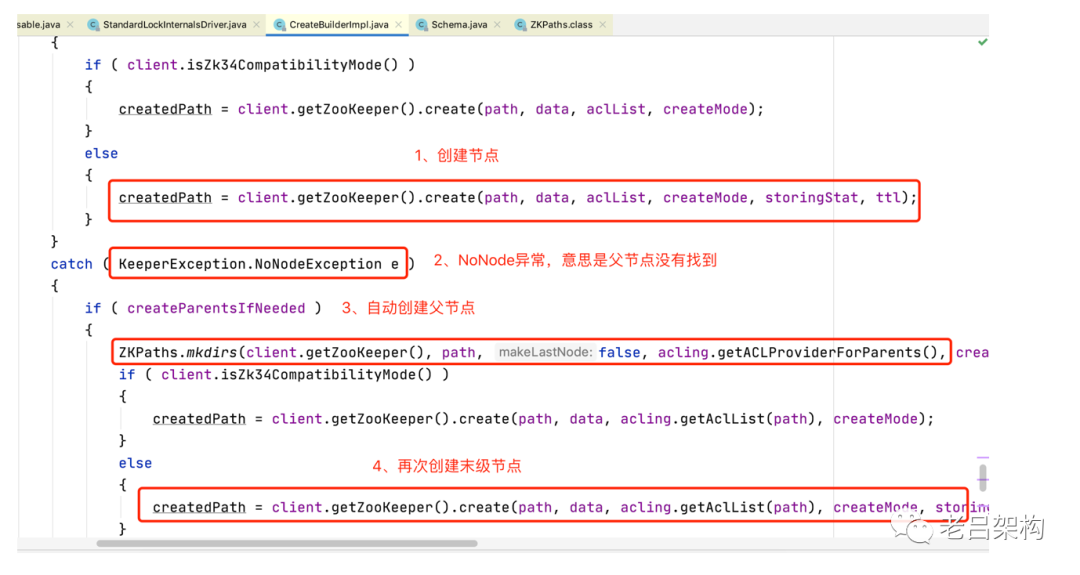
在这里我们找到了 NoNodeException的捕获,并且我们知道了是由于父节点不存在才抛出的异常。
ZKPaths.mkdirs 方法会自动创建所有的上级节点,只留末级节点不创建,最后再次创建末级节点一定能成功
至此,我们大致明白了错误的原因了。是因为要锁定的末级目录的父节点不存在造成的,框架自动处理了这种情况,默默的自动创建了父目录,所以在应用层是无感知的,只能在zookeeper的日志里发现此问题。
四、总结
1、zookeeper的原生api是不支持 自动创建父目录的。
2、apache.curator 框架封装了自动创建父目录的过程,应用层无感知,友好。
3、要解决zookeeper中日志打印的问题就需要在创建分布式锁之前判断并创建父目录,或者path中不带任何父目录直接追加末级节点。
4、不要忽略日志中的可疑日志,细究总是能发现问题。
这篇关于zookeeper日志中Error KeeperErrorCode NoNode 错误的排查过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





