本文主要是介绍Elasticsearch“滚动查询“(Scrolling)的机制的与Java使用ES Client 调用滚动查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Elasticsearch"滚动查询"(Scrolling)的机制的与Java使用ES Client 调用滚动查询
- 前言
- 1. 滚动查询的一般步骤
- 1.1 发起初始搜索请求,返回命中结果和滚动ID
- 1.2 使用滚动ID检索下一页结果
- 1.4 重复执行直到没有检索结果返回
- 1.5 清除滚动上下文释放资源
- 2.Java Elasticsearch客户端执行滚动查询
- 3. SpringDataElasticsearch滚动查询
前言
ES在进行普通的查询时,默认只会查询出来10条数据。我们通过设置es中的size可以将最终的查询结果从10增加到10000。如果需要查询数据量大于es的翻页限制或者需要将es的数据进行导出又当如何?
Elasticsearch提供了一种称为"滚动查询"(Scrolling)的机制,用于处理大型数据集的分页查询。滚动查询允许在持续的时间段内保持一个活动的搜索上下文,然后使用滚动ID进行迭代检索结果。滚动查询和关系型数据库中的游标有点类似,因此也叫游标查询
1. 滚动查询的一般步骤
1.1 发起初始搜索请求,返回命中结果和滚动ID
scroll=5m表示每个滚动查询的有效时间为5分钟
POST /your_index/_search?scroll=5m
{"size": 100, // 每次返回的结果数量"query": { ... } // 查询条件
}
命中结果:
{"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==","hits": {"total": {"value": 10000,"relation": "eq"},"hits": [ ... ] // 检索到的文档}
}
示例:
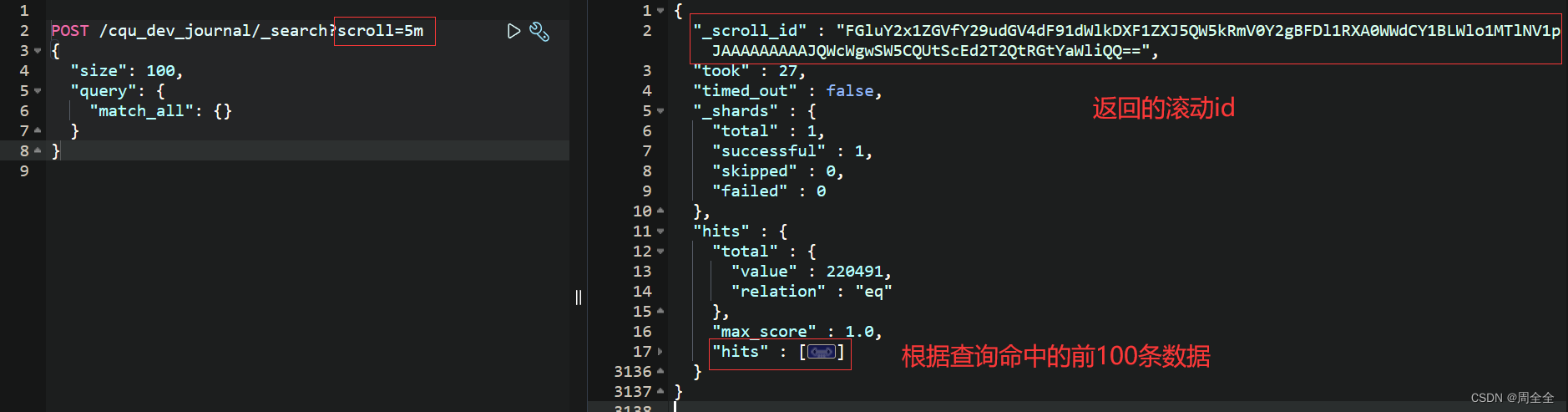
1.2 使用滚动ID检索下一页结果
POST /_search/scroll
{"scroll": "5m","scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
示例:
POST /_search/scroll{"scroll": "5m","scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFDJPRXc0WWdCY1BLWlo1MTk4MmR3AAAAAAAAAXYWcWgwSW5CQUtScEd2T2QtRGtYaWliQQ=="}
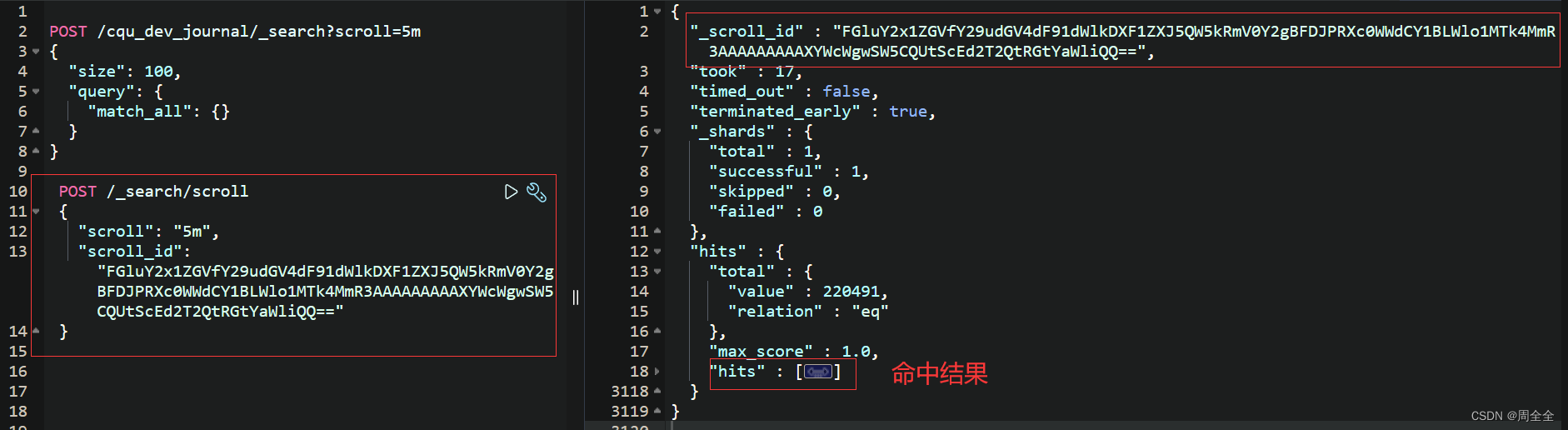
1.4 重复执行直到没有检索结果返回
Elasticsearch将返回下一页结果和一个新的滚动ID。可以根据需要重复这个步骤,直到没有更多结果为止
1.5 清除滚动上下文释放资源
滚动查询结束后,您可以通过发送一个清除滚动上下文的请求来释放资源:
DELETE /_search/scroll
{"scroll_id": ["DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="]
}
以上为滚动查询进行分页检索的基本过程。在每个滚动请求中,都需要提供先前滚动请求返回的滚动ID。这样Elasticsearch才能够维护搜索上下文并返回正确的结果
2.Java Elasticsearch客户端执行滚动查询
public static void main(String[] args) {long start = System.currentTimeMillis();//构建es HttpHost对象HttpHost httpHost1 = new HttpHost("192.168.1.1", 9200, "http");// 滚动时间窗口long scrollTime = 1L;// 每次返回的文档数量int batchSize = 20000;//索引名String indexName = "你的索引名称";try (RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(httpHost1))) {//构建查询请求SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.boolQuery());searchSourceBuilder.size(batchSize);//设置查询返回字段String[] includes = {};searchSourceBuilder.fetchSource(includes, null);// 滚动查询请求SearchRequest searchRequest = new SearchRequest(indexName);searchRequest.source(searchSourceBuilder);//设置请求滚动时间窗口时间searchRequest.scroll(TimeValue.timeValueMinutes(scrollTime));//执行首次检索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//首次检索返回scrollId,用于下一次的滚动查询String scrollId = searchResponse.getScrollId();//获取首次检索命中结果SearchHit[] searchHits = searchResponse.getHits().getHits();//计数int count = 0;// 处理第一批结果for (SearchHit hit : searchHits) {// 处理单个文档JSONObject dataJson = (JSONObject) JSON.parse(hit.getSourceAsString());System.out.println("====对首次请求的进行处理,当前计数:" + count++);}// 处理滚动结果while (searchHits != null && searchHits.length > 0) {SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);scrollRequest.scroll(TimeValue.timeValueMinutes(scrollTime));searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);scrollId = searchResponse.getScrollId();searchHits = searchResponse.getHits().getHits();for (SearchHit hit : searchHits) {JSONObject dataJson = (JSONObject) JSON.parse(hit.getSourceAsString());System.out.println("====滚动查询,当前计数:" + count++);}}// 清理滚动上下文ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);boolean succeeded = clearScrollResponse.isSucceeded();long end = System.currentTimeMillis();System.out.println("共执行时间:" + (end - start) / 1000 + " s");} catch (Exception e) {System.out.println("===error==" + e.getMessage());e.printStackTrace();}
}
3. SpringDataElasticsearch滚动查询
import org.elasticsearch.action.search .*;
import org.elasticsearch.client .*;
import org.elasticsearch.common.unit .*;
import org.elasticsearch.index.query .*;
import org.elasticsearch.search .*;
import org.elasticsearch.search.builder .*;
import org.springframework.beans.factory.annotation .*;
import org.springframework.data.elasticsearch.core .*;
import org.springframework.data.elasticsearch.core.query .*;public class ScrollSearchExample {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void performScrollSearch() {String scrollTime = "1m"; // 滚动时间窗口int batchSize = 100; // 每次返回的文档数量QueryBuilder queryBuilder = QueryBuilders.matchQuery("field", "value");NativeSearchQueryBuilder searchQuery = new NativeSearchQueryBuilder();searchQuery.withQuery(queryBuilder).withPageable(PageRequest.of(0, batchSize)).build();SearchResponse searchResponse = elasticsearchOperations.startScroll(scrollTime,searchQuery,YourEntityClass.class,IndexCoordinates.of("your_index"));String scrollId = searchResponse.getScrollId();SearchHits<YourEntityClass> searchHits = searchResponse.getSearchHits();// 处理第一批结果for (SearchHit<YourEntityClass> hit : searchHits) {YourEntityClass entity = hit.getContent();// 处理单个文档}// 处理滚动结果while (searchHits != null && searchHits.hasSearchHits()) {searchResponse = elasticsearchOperations.continueScroll(scrollId, scrollTime, YourEntityClass.class);scrollId = searchResponse.getScrollId();searchHits = searchResponse.getSearchHits();for (SearchHit<YourEntityClass> hit : searchHits) {YourEntityClass entity = hit.getContent();// 处理单个文档}}// 清理滚动上下文elasticsearchOperations.clearScroll(scrollId);}
}
这篇关于Elasticsearch“滚动查询“(Scrolling)的机制的与Java使用ES Client 调用滚动查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






